




 本文介绍了信息熵作为度量随机变量不确定性的工具,以及在自然语言处理中的应用,包括联合熵、条件熵、互信息和相对熵的概念。互信息用于衡量随机变量间的相关性,而相对熵(KL距离)则衡量两个概率分布的差异。这些理论在语言模型、信息检索和文本理解等领域发挥关键作用。
本文介绍了信息熵作为度量随机变量不确定性的工具,以及在自然语言处理中的应用,包括联合熵、条件熵、互信息和相对熵的概念。互信息用于衡量随机变量间的相关性,而相对熵(KL距离)则衡量两个概率分布的差异。这些理论在语言模型、信息检索和文本理解等领域发挥关键作用。
信息是个相当宽泛的概念,很难用一个简单的定义将其完全准确的把握。然而,对于任何一个概率分布,可以定义一个称为熵(entropy)的量,它具有许多特性符合度量信息的直观要求。这个概念可以推广到互信息(mutual information),互信息是一种测度,用来度量一个随机变量包含另一个随机变量的信息量。熵恰好变成一个随机变量的自信息。相对熵(relative entropy)是个更广泛的量,它是刻画两个概率分布之间距离的一种度量,而互信息又是它的特殊情形。
信息熵
——随机变量不确定度的度量
设p(x)为随机离散变量X的概率密度函数,x属于某个符号或者字符的离散集合 X:
p(x) = P(X = x), x ∈ X
熵表示单个随机变量的不确定性的均值,随机变量的熵越大,它的不确定性越大,也就是说,能正确估计其值的概率越小。熵的计算公式 :
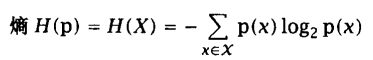
将负号移入对数公式内部:
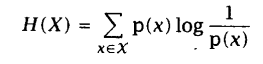
上式实际上表达的是一个加权求值的概念,权重就是随机变量X的每个取值的概率。
用E表示数学期望。如果X~p(x),则随机变量g(X)的期望值可表示为:

当
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1473
1473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









