







 本文通过介绍MNIST数据集及其使用方法,展示了如何利用PyTorch实现全连接神经网络进行手写数字识别。从数据预处理到模型构建,再到训练和测试,详细讲解了每个步骤,并提供了完整的代码示例。同时,解释了one-hot编码和数据归一化的重要性。
本文通过介绍MNIST数据集及其使用方法,展示了如何利用PyTorch实现全连接神经网络进行手写数字识别。从数据预处理到模型构建,再到训练和测试,详细讲解了每个步骤,并提供了完整的代码示例。同时,解释了one-hot编码和数据归一化的重要性。
在对全连接神经网络的基本知识(全连接神经网络详解)学习之后,通过MNIST手写数字识别这个小项目来学习如何实现全连接神经网络。
MNIST数据集
对于深度学习的任何项目来说,数据集是其中最为关键的部分。MNIST数据集是美国国家标准与技术研究院收集整理的大型手写数字数据库,包含60,000个示例的训练集以及10,000个示例的测试集。其中的图像的尺寸为28*28。
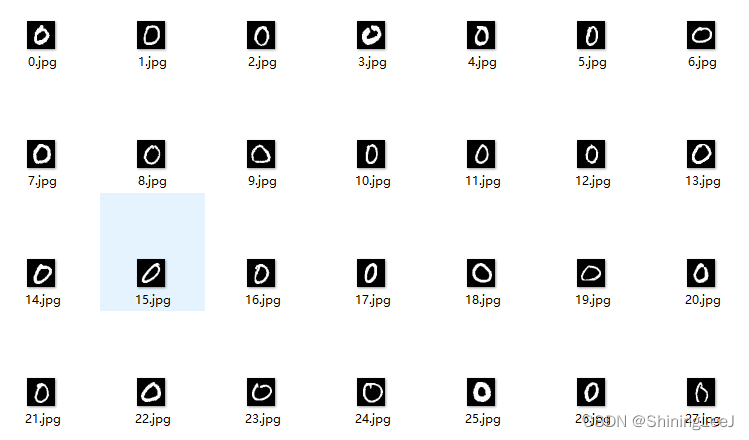
对于MNIST数据集,可以通过torchvision中的datasets进行下载
root (string): 表示数据集的根目录,其中根目录存在MNIST/processed/training.pt和MNIST/processed/test.pt的子目录
train (bool, optional): 如果为True,则从training.pt创建数据集,否则从test.pt创建数据集
download (bool, optional): 如果为True,则从internet下载数据集并将其放入根目录。如果数据集已下载,则不会再次下载
transform (callable, optional): 接收PIL图片并返回转换后版本图片的转换函数
data_train = datasets.MNIST(root = "./data/",
transform=transform,
train = True,
download = True)
data_test = datasets.MNIST(root="./data/",
transform = transform,
train = False)但是对于这样下载的数据,并不能直接以可视化的形式展示,对于初学者来说不是很友好。所也这里采用MNIST数据集的图片形式。(完整的代码和数据会放在最后)
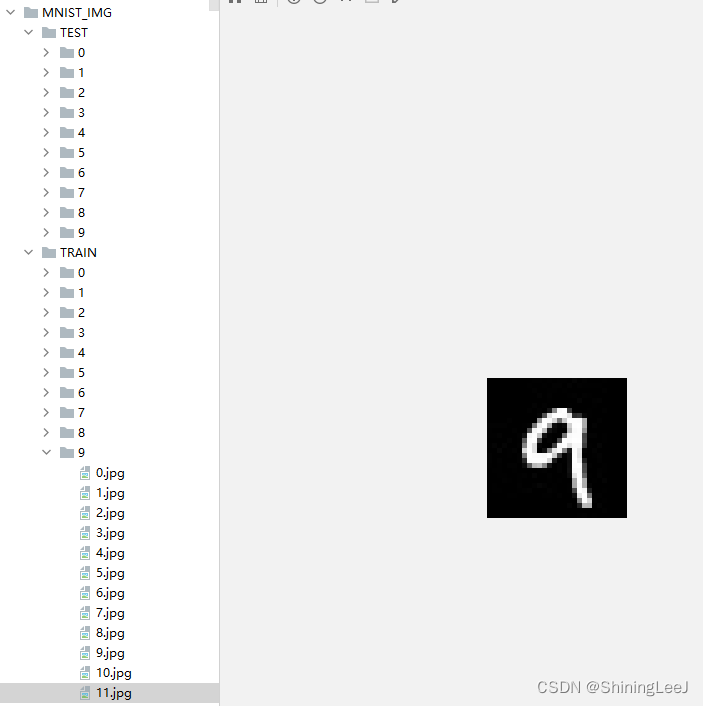
可以看到整个数据集分为训练集和测试集,其中文件夹名作为数据的标签。
下面就开始制作数据集
from torch.utils.data import DataLoader,Dataset
import os
import cv2
import numpy as np
"""
制作自定义的数据集
实现三个魔术方法:
__init__:初始化数据集
__len__:返回数据集的长度
__getitem__:索引数据,在DtaLoader的循环之中会调用这个方法
"""
class MNIST_Dataset(Dataset):
def __init__(self,root,isTrain = True):
#初始化列表,用于存储数据集的路径和标签
#直接存储图片会导致列表过大,所以存储图片的路径
self.dataset = []
#判断数据集是训练集还是测试集
if isTrain:
folder = "TRAIN"
else:
folder = "TEST"
#利用os模块,用字符串拼接图片的路径
for tag in os.listdir(root + "/" + folder):
for file in os.listdir(root + "/" + folder + "/" + tag):
path = root + "/" + folder + "/" + tag + "/" + file
#存储图片的路径和标签
self.dataset.append((path,tag))
def __len__(self):
#返回数据集的长度
return len(self.dataset)
def __getitem__(self, index):
#在DataLoader循环时调用此方法,处理图片
#首先根据index来索引一张图片的路径和标签
data = self.dataset[index]
#获取图像的路径
path = data[0]
#获取图像的标签
tag = data[1]
#利用opencv读取图片
img = cv2.imread(path,0)
#将图像转换为一维数组 由28*28变为784
img = img.reshape(-1)
#归一化处理
img = img / 255
#制作one-hot标签
"""
因为手写数字识别是一个十分类的问题,全连接神经网络最后输出的是一个长度为10的一维数组,
所以one-hot标签是一个长度为10的一维数组,获取的标签(比如数字9)
就在一维数组索引为9的位置置1
"""
tag_one_hot = np.zeros(10)
tag_one_hot[int(tag)] = 1
return np.float32(img), np.float32(tag_one_hot)
if __name__ == '__main__':
#初始化测试集
dataset = MNIST_Dataset("MNIST_IMG",isTrain=False)
#初始化数据加载器 batch_size=100:每一批次的数据量 shuffle=True:是否打乱数据集
loader = DataLoader(dataset=dataset,batch_size=100,shuffle=True)
for i,(img,tag) in enumerate(loader):
print(len(dataset))
#批次
print(i)
print(img)
print(img.shape)
print(tag)
print(tag.shape)下面来看测试集的运行结果:
整个数据集的长度为9997,本来应该为10000,但是我的图像数据中少了三张,在训练集中是正常的60000张。
首先看到的是第一批次的数据,有100张图片的数据,每张图片都由28*28转换为了784(全连接神经网络输入要求)。然后就是数据的one-hot标签,比如第一个标签就是代表数字8

下面再来具体的说说one-hot标签和归一化
one-hot标签:
一位有效编码,用N位状态寄存器来对N个状态进行编码,例如[0, 0, 1]、[1, 0, 0]、[0, 1, 0]
下面来看一个具体的例子:
对 jack 进行one-hot编码
1、确定样本数,特征数;
2、jack共4个字母,也就是4个样本;
3、字母共26个,也就是26个特征。

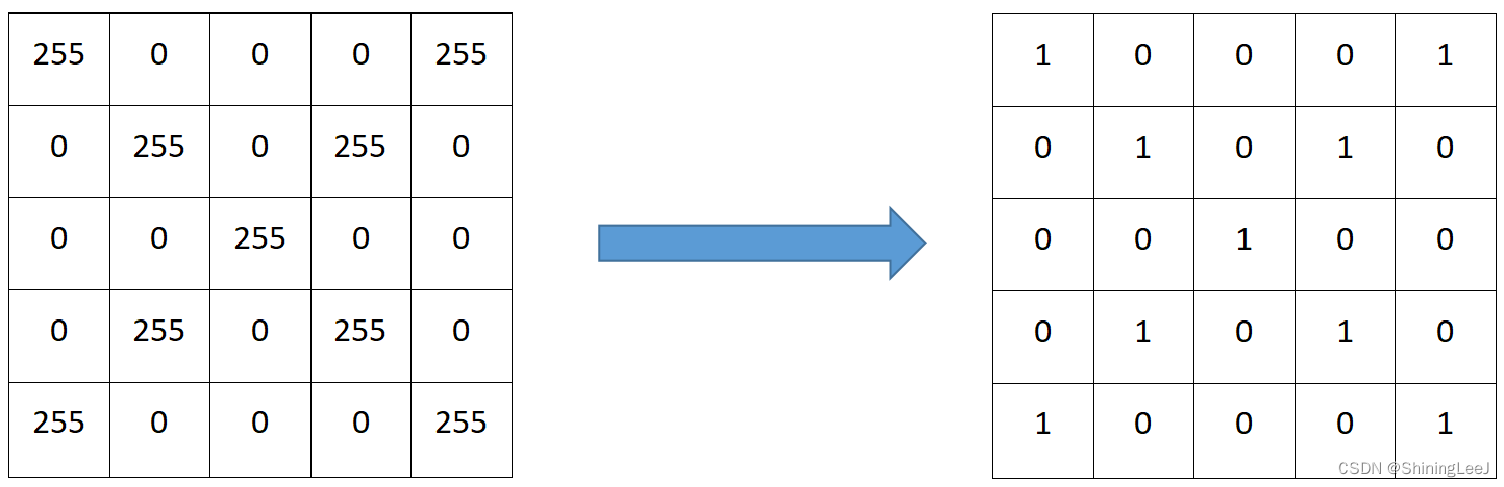
归一化 :
由于再进行深度学习时,大多数使用的数据都是图片。而图片的像素范围是0-255,在进行计算时是不够简单的。所以要对数据进行一个归一化。
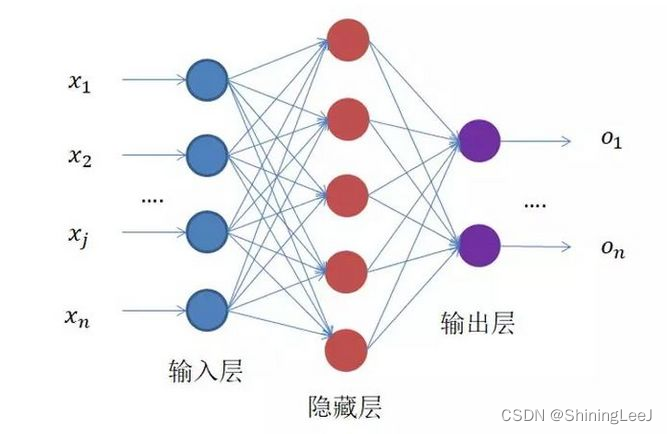
全连接神经网络的设计与实现
import torch
from torch import nn
"""
创建自定义的数据集需要继承torch下的nn.Module类
实现两个方法:
__init__:初始化全连接神经网络
forward:前向传播
"""
class MNIST_Net(nn.Module):
def __init__(self):
#需要实现父类的__init__方法,不然会报错
super().__init__()
#整个全连接神经网络放在Sequential这个容器之中
self.layer = nn.Sequential(
#bias:设置是否存在偏移量,默认为有
#使用Linear实现全连接神经网络的一层
#图片的原尺寸为28*28,转化为784,输入层为784,输出层为512
nn.Linear(784,512),
#使用ReLU激活函数进行激活
nn.ReLU(),
nn.Linear(512,256),
nn.ReLU(),
nn.Linear(256,128),
nn.ReLU(),
nn.Linear(128,64),
nn.ReLU(),
nn.Linear(64,32),
nn.ReLU(),
nn.Linear(32,16),
nn.ReLU(),
nn.Linear(16,10),
#最后一层使用Softmax作为激活函数,返回十个概率值
#NV结构:在进入网络的数据集向上面测试数据集时,是一个批次的进入
#需要将第二个维度的数据进行激活
nn.Softmax(dim=1)
)
#进行前向传播返回结果
def forward(self,x):
return self.layer(x)
if __name__ == '__main__':
#初始化网络
net = MNIST_Net()
#初始化数据
test = torch.randn(1,784)
print(test)
print(test.shape)
#前向传播结果
answer = net.forward(test)
print(answer)
print(answer.shape)进行测试:

MNIST数据集手写数字识别训练
import torch
from torch import optim, nn
from MNIST_Net import MNIST_Net
from MNIST_Dataset import MNIST_Dataset
from torch.utils.data import DataLoader
"""
创建训练类,需要实现两个方法
__init__:初始化
call:训练过程
"""
class MNIST_Train():
def __init__(self):
#加载训练集
self.dataset_train = MNIST_Dataset("MNIST_IMG",isTrain=True)
#加载器
self.dataloader_train = DataLoader(dataset=self.dataset_train,batch_size=600,shuffle=True)
#加载测试集
self.dataset_test = MNIST_Dataset("MNIST_IMG",isTrain=False)
#加载器
self.dataloader_test = DataLoader(dataset=self.dataset_test,batch_size=100,shuffle=True)
#创建模型
self.net = MNIST_Net()
#将模型放到cuda上,如果没有cuda的,就只能使用CPU来进行训练了
self.net.to("cuda")
#创建模型优化器,后面的梯度清空,更新参数都由这个优化器自动完成
self.opt =optim.Adam(self.net.parameters())
#求损失:均方差损失函数
self.loss = nn.MSELoss()
#进行训练
def __call__(self):
#训练300轮
for epoch in range(0,300):
#每一批次的总损失
sum_loss = 0
for i,(img,tag) in enumerate(self.dataloader_train):
#开启训练模式
self.net.train()
#将数据传入cuda
img, tag = img.to("cuda"), tag.to("cuda")
#前向传播结果
out = self.net.forward(img)
# 求损失(均方差):out、tags是矩阵,不是标量
# loss = torch.mean((out - tag) ** 2)
loss = self.loss(out,tag)
# 完成了一次训练:清空梯度、自动求导、更新梯度
self.opt.zero_grad()
loss.backward()
self.opt.step()
# 求损失的和
sum_loss = sum_loss + loss.item()
print("训练损失 {}".format(sum_loss/len(self.dataloader_train)))
# 测试
#测试得分的总和
sum_score = 0
# 测试损失总和
test_sum_loss = 0
# 开始测试
for i, (img, tag) in enumerate(self.dataloader_test):
# 开始测试模式
self.net.eval()
# 将数据传入cuda
img, tag = img.to("cuda"), tag.to("cuda")
# 把数据加载在网络中
test_out = self.net.forward(img)
# 得到测试集的均方差损失
# test_loss = torch.mean((tag - test_out) ** 2)
test_loss = self.loss(test_out,tag)
# 测试损失求和
test_sum_loss = test_sum_loss + test_loss.item()
# 10分类,各自概率,取最大值的索引,做one-hot编码
pre = torch.argmax(test_out, dim=1)
# 取标签结果:正确答案
labels_tag = torch.argmax(tag, dim=1)
# 计算得分
score = torch.mean(torch.eq(pre, labels_tag).float())
# 总分
sum_score = sum_score + score
# 求平均损失(每一轮)
test_avg_loss = test_sum_loss / len(self.dataloader_test)
# 求平均分(每一轮)
test_avg_score = sum_score / len(self.dataloader_test)
print("训练轮次:", epoch, "测试损失", test_avg_loss, "测试得分:", test_avg_score)
if __name__ == '__main__':
train = MNIST_Train()
train()
项目代码以及图片资源
链接:https://pan.baidu.com/s/1ioNsdoAVvXNV9pVsPfwi4Q
提取码:gokg
















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









