







前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见大数据技术体系
目录
- Spark 3.2.0 版本新特性 push-based shuffle 论文详解(一)概要和介绍
- Spark 3.2.0 版本新特性 push-based shuffle 论文详解(二)背景和动机
- Spark 3.2.0 版本新特性 push-based shuffle 论文详解(三)系统设计
- Spark 3.2.0 版本新特性 push-based shuffle 论文详解(四)实现优化
- Spark 3.2.0 版本新特性 push-based shuffle 论文详解(五)评估结果
- Spark 3.2.0 版本新特性 push-based shuffle 论文详解(六)相关工作
- Spark 3.2.0 版本新特性 push-based shuffle 论文详解(七)结论
思维导图
4. 实现优化
我们在 Apache Spark 2.3 的基础上实现了 Magnet。
由于修改只面向 Spark 内部,而不是针对用户的公共 API,因此现有的 Spark 应用程序可以从Magnet中受益,而无需更改代码。
为了实现最佳效率和可扩展性,我们还在实现中应用了一些优化。
4.1 并行化数据传输和任务执行
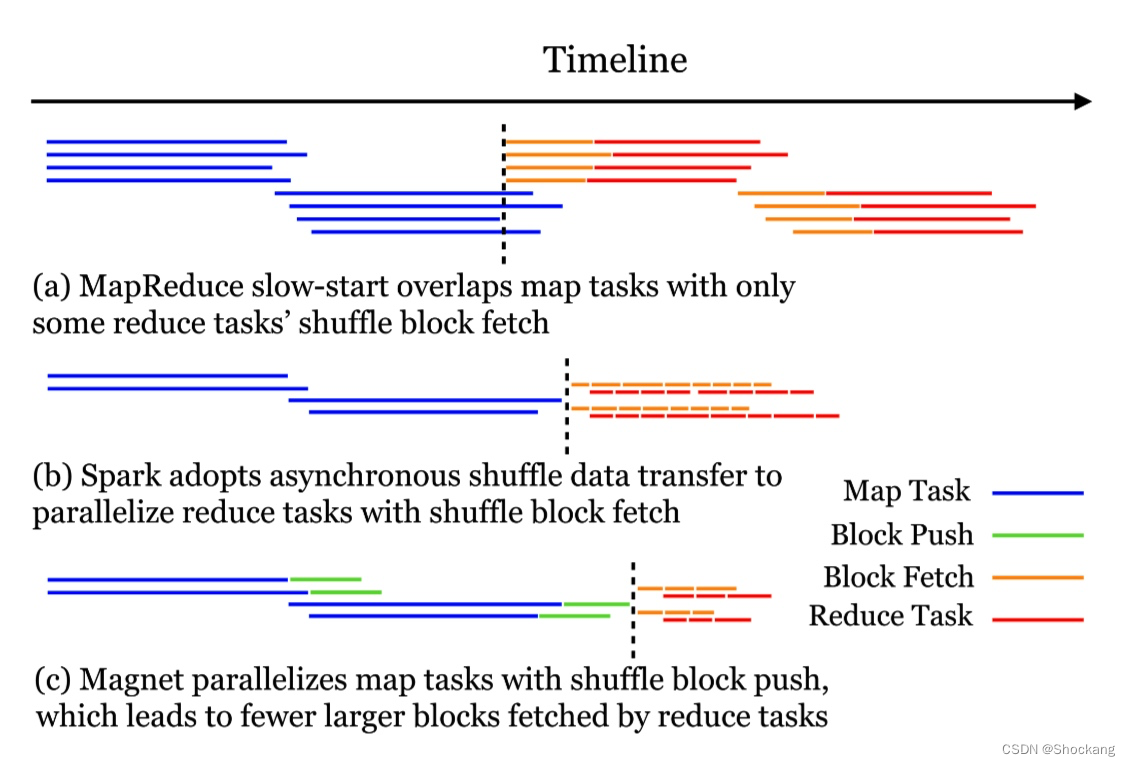
图 7:
Magnet的目标是并行地进行任务执行和 shuffle 数据传输。
Spark 优于旧版 Hadoop MapReduce 引擎的一个地方在于:怎样并行地进行 Shuffle 数据获取和任务执行?
如图 7(a)所示,Hadoop MapReduce 通过称为慢启动(slow start)的技术实现了有限的并行化。
慢启动特性指定 Map 任务完成度为多少时 Reduce 任务可以启动,过早启动 Reduce 任务会导致资源占用,影响任务运行效率,但适当的提早启动 Reduce 任务会提高 Shuffle 阶段的资源利用率,提高任务运行效率。例如:某集群可启动 10 个 Map 任务,MapReduce 作业共 15 个 Map 任务,那么在一轮 Map 任务执行完成后只剩 5 个 Map 任务,集群还有剩余资源,在这种场景下,配置慢启动参数值小于 1,比如 0.8,则 Reduce 就可以利用集群剩余资源。对应的配置参数为:
mapreduce.job.reduce.slowstart.completedmaps,表示当多少占比的 Map 执行完后开始执行 Reduce。默认 100% 的 Map 跑完后开始起 Reduce。
它允许一些 Reduce 任务在某些 Map 任务还在运行的时候,开始获取 Shuffle 数据。
这样,只有部分 Reduce 任务的 Shuffle 数据获取和 Map 任务的执行存在时间上的重叠。
Spark 在这方面做得很好。
相比重叠地执行 Map 任务和 Reduce 任务,这在 DAG 执行引擎中是很不容易管理的,Spark 通过使用异步 RPC 来实现并行。
一个独立的线程用来获取远程的 Shuffle 块,另一个则在获取到的块上面执行 Reduce 任务。
这两个线程的作用就像一对生产者和消费者,可以更好交叠进行 Shuffle 数据获取和执行 Reduce 任务。
图7(b)中说明了这一点。
在Magnet的实现中,我们采用了类似的技术,以实现并行的数据传输和任务执行。
在 Shuffle Map 任务侧,通过专用的线程池,我们将 shuffle block 块推送操作从 Map 任务执行中解脱出来。
这在图7(c)中有说明。
这允许后面的 Mapper 执行期间进行并行化的块推送操作。
Shuffle Map 任务可能导致 CPU/内存 更加的密集,然而,块推送操作则会使得 磁盘/网络 更加的密集。
这种并行化对于 Spark Executor 来讲有助于更好地利用可用的计算资源。
在 Shuffle Reduce 任务侧,如果合并的 Shuffle 文件位于远程的Magnet Shuffle Service上,抓取整个 shuffle 合并文件作为单个块,这可能会导致不期望的延迟,因为我们无法在数据抓取和 Reduce 任务执行之间实现很多并行化。
为了解决这个问题,Magnet 将每个 shuffle 合并文件分成多个 MB 大小的切片,同时附加以 block 块。
shuffle 合并文件中的切片边界作为单独的索引文件保存在磁盘上。
Spark Driver 只需要在 shuffle 合并分区的粒度上追踪信息。
shuffle 合并文件如何进一步划分成切片仅仅由 Magnet shuffle service通过索引文件来追踪。
当 reduce 任务获取远程 shuffle 合并文件的时候,Magnet shuffle service响应以切片的数量,因此客户端可以将 shuffle 合并文件的单次抓取转换成独立 MB 大小切片的多次抓取。
这种技术有助于在优化磁盘 I/O 和并行化数据传输/任务执行之间取得更好的平衡。
4.2 资源的高效实现
Magnet的实现会在 shuffle 服务一侧产生最小的 CPU 和内存开销。
Magnet shuffle service在块推送/合并操作中唯一的职责是接受远程推送的块,并将其附加到相应的 shuffle 合并文件中。
通过下面的措施实现了低开销:
- 与 [33] 不同, shuffle 服务侧没有进行排序。shuffle 期间的所有排序,无论是 map-side 排序还是 reduce-side 排序,都可以通过 map 任务和 reduce 任务在Spark Executor 内部执行。
- 与 [4,41] 的不同,
Magnet shuffle service在合并操作期间不会缓冲内存中的block 块。block 块唯一缓冲在 Spark Executor 内部,而Magnet shuffle service直接在磁盘上合并 block 块。
[33]
S.Rao,R.Ramakrishnan,A.Silberstein, M.Ovsiannikov,and D.Reeves.Sailfish:A framework for large scale data processing.Proceedings of the 3rd ACM Symposium on Cloud Computing,pages 1-14, 2012.
[4]
Cosco: An efficient facebook-scale shuffle service.
(Retrieved 02/20/2020).
[41]
H.Zhang,B.Cho,E.Seyfe,A.Ching,and M.J.
Freedman.Riffle:optimized shuffe service for large-scale data analytics.Proceedings of the 13th EuroSys Conference,pages 1-15,2018.
[41] 中的 Shuffle 优化是通过从本地 Mapper 中拉取/合并 Shuffle block 的 shuffle 服务来实现的。
这需要合并前在内存中缓冲 block 块以提高磁盘效率。
随着 shuffle 服务中并发合并流的数量增长,内存的需要也在增长。
[41] 中提到 20 个并发合并流需要 6-8GB 的内存。
在繁忙的生产集群中,这可能会成为带来更高并发的可扩展性瓶颈。
取而代之的是,Magnet在 Spark Executor 中缓冲 block 块,同时在所有的 Executor 中分配内存需求。
Spark Executor 中有限的并发任务也使得内存的足迹保持着较低的水准,从而使Magnet更具可扩展性。
在 [33,4] 中,合并操作利用了 shuffle 服务内部每个分区的写前缓冲区,以批量写入 shuffle 合并数据。
虽然这有助于减少合并期间写操作的数量,但内存的需求带来了和[41]类似的可扩展性瓶颈问题。
4.3 优化磁盘 I/O
在 3.2 节中,我们展示了Magnet是怎样批量读取 shuffle block 块以提高磁盘 I/O 效率的。
但是,这种改进需要在合并操作期间二次写入大部分的 shuffle 中间数据。
尽管这似乎很昂贵,但我们仍然认为总体的 I/O 效率在提高。
与 HDD 的小型随机读取不同,小型随机写入从多重缓存中受益,例如操作系统页缓存和磁盘缓存。
这些缓存将多个写入操作组合为一个,减少了放置在磁盘上的写操作的数量。
这就导致,与小型随机读取相比,小型随机写入可以获得更高的吞吐量。
5.2.3 节中的基准测试也会有展示。
随着批量读 shuffle block 块和缓存批量写操作,Magnet可以为 shuffle 小型的 shuffle block 块从而减少整个磁盘 I/O 操作,即使它执行了二次写入。
对于大型的 shuffle block 块,如 3.5.2 所述,我们跳过合并这些块。
因此,双写的开销并没有因为这些而产生。
实际上,由于 Magnet致力于的原生特性,选择合适的操作系统 I/O 调度程序,将读操作的优先级设置成比写操作高,可以帮助减少二次写入的开销。
我们还考虑使用小型专用的 SSD 作为缓冲区,以批量写入更多的 block 块。
与 [33,4] 中的写前缓冲方法相比,这提高了 HDD 的写入效率而不产生其他的内存开销。















 1226
1226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









