










- 作者:韩信子@ShowMeAI
- 教程地址:https://www.showmeai.tech/tutorials/33
- 本文地址:https://www.showmeai.tech/article-detail/148
- 声明:版权所有,转载请联系平台与作者并注明出处
- 收藏ShowMeAI查看更多精彩内容

当我们提到python数据分析的时候,大部分情况下都会使用Pandas进行操作。pandas整个系列覆盖以下内容:
一、Pandas数据分组与操作
在我们进行业务数据分析时,经常要对数据根据1个或多个字段分为不同的组(group)进行分析处理。如电商领域可能会根据地理位置分组,社交领域会根据用户画像(性别、年龄)进行分组,再进行后续的分析处理。
Pandas中可以借助groupby操作对Dataframe分组操作,本文介绍groupby的基本原理及对应的agg、transform和apply方法与操作。
我们先模拟产出1个Dataframe:
import numpy as np
import pandas as pd
company=["A","B","C"]
data=pd.DataFrame({
"company":[company[x] for x in np.random.randint(0,len(company),10)],
"salary":np.random.randint(5,50,10),
"age":np.random.randint(15,50,10)})

二、Groupby分组及应用
2.1 分组
pandas实现分组操作的很简单,只需要把分组的依据(字段)放入groupby中,例如下面示例代码基于company分组:
group = data.groupby("company")
经过groupby处理之后我们会得到一个DataFrameGroupBy对象:
group
# 输出
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001C67C072BE0>
这个生成的DataFrameGroupBy是什么?data经过groupby处理后发生了什么?
上面返回的Groupby处理结果是内存地址,并不利于直观地理解,我们可以把group转换成list的形式来看一看内部数据和整个过程:
list(group)
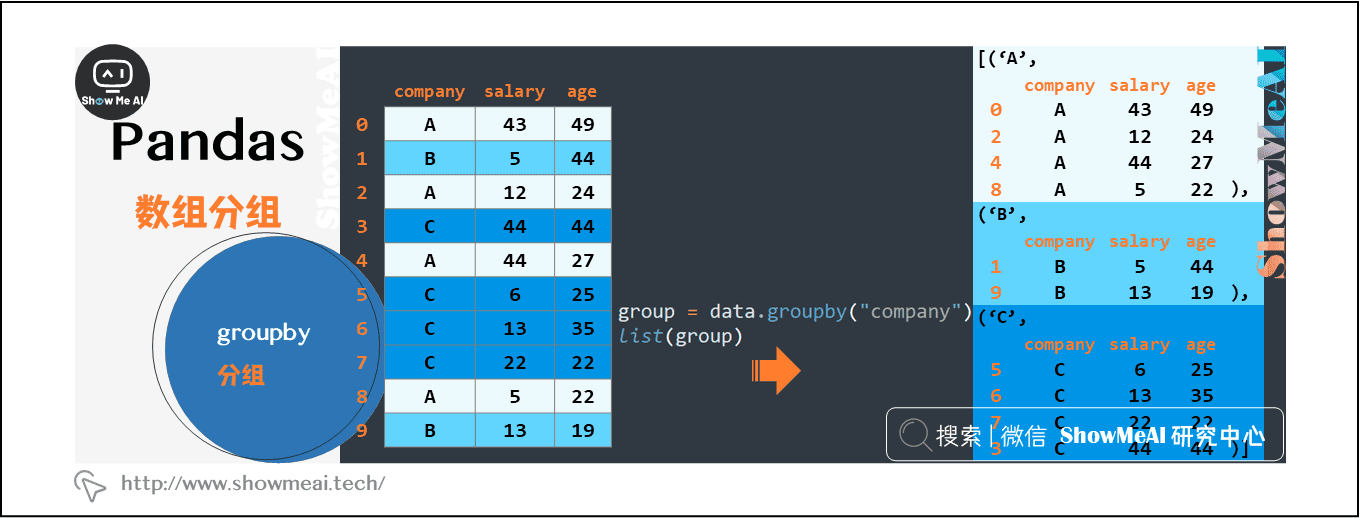
转换成列表的形式后,可以看到,列表由三个元组组成,每个元组中:
- 第一个元素是组别(这里是按照company进行分组,所以最后分为了A,B,C)
- 第二个元素的是对应组别下的DataFrame
总结一下,groupby将原有的DataFrame按照指定的字段(这里是company),划分为若干个分组DataFrame。groupby之后可以进行下一步操作,注意,在groupby之后的一系列操作(如agg、apply等),均是基于子DataFrame的操作。
下面我们一起看看groupby之后的常见操作。
2.2 agg 聚合操作
聚合统计操作是groupby后最常见的操作,类比于SQL中我们会对数据按照group做聚合,pandas中通过agg来完成。聚合操作可以用来求和、均值、最大值、最小值等,下表为Pandas中常见的聚合操作:

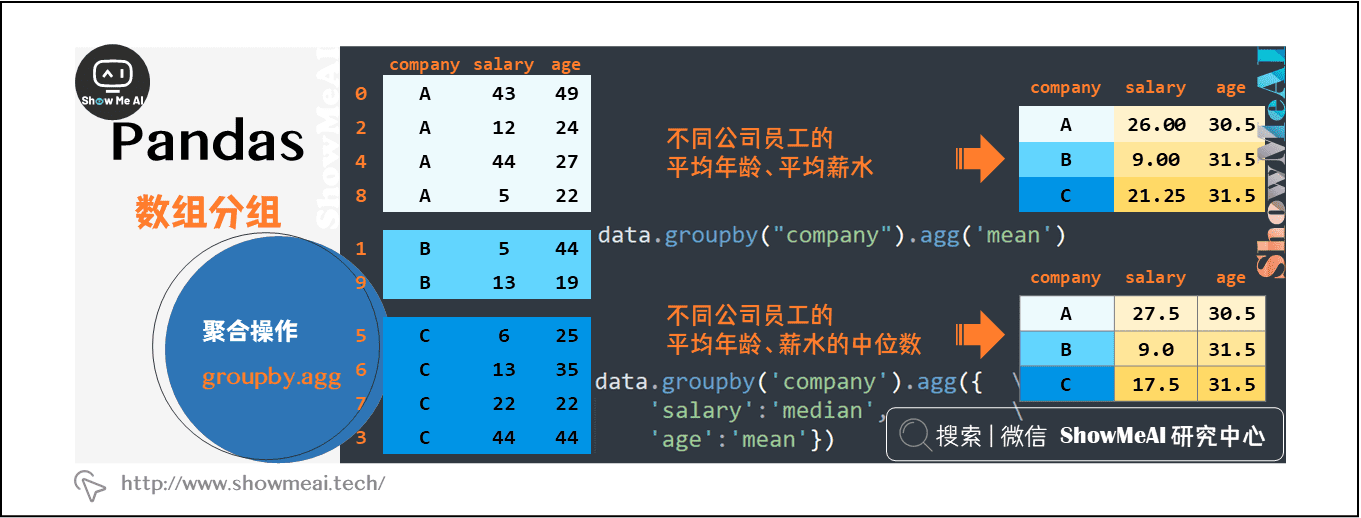
例如,计算不同公司员工的平均年龄和平均薪水,示例代码如下:
data.groupby("company").agg('mean')
或者针对不同字段做不同的计算处理,例如,要计算不同公司员工的平均年龄、薪水的中位数。可以利用字典进行聚合操作:
data.groupby('company').agg({'salary':'median','age':'mean'})
我们对agg聚合过程进行图解,如下所示:
2.3 transform变换
transform是另外一个pandas分组后会使用到的方法,我们举例来说明它的用法。
上述agg应用例子中,我们计算了不同公司员工的平均薪水,如果现在需要新增一列avg_salary,代表员工所在的公司的平均薪水(相同公司的员工具有一样的平均薪水),我们就可以借助transform来完成。
要完成上述任务,我们需要先求得不同公司的平均薪水,再按照员工和公司的对应关系填充到对应的位置,使用之前学到的map方法可以拆解实现如下:
avg_salary_dict = data.groupby('company')['salary'].mean().to_dict()
data['avg_salary'] = data['company'].map(avg_salary_dict)
data
而transform方法可以帮助我们一行实现全过程:
data['avg_salary'] = data.groupby('company')['salary'].transform('mean')
data

下面对groupby+transform的过程做图解帮助理解:
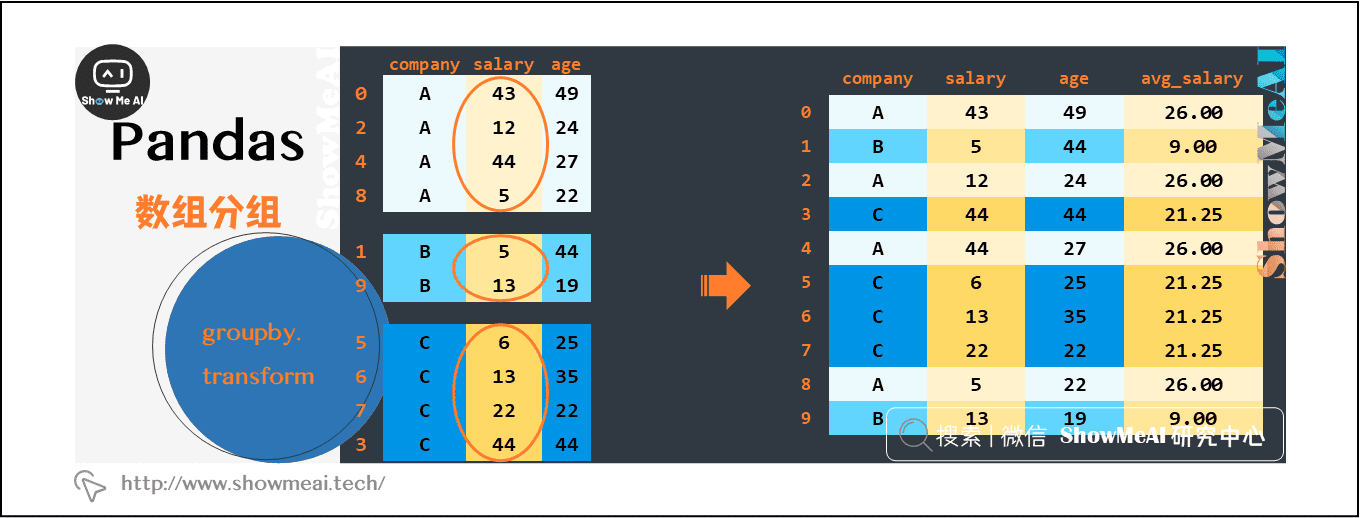
注意图中大方框,展示了transform和agg不一样的计算过程:
- agg:会计算得到A,B,C公司对应的均值并直接返回
- transform:会对每一条数据求得相应的结果,同一组内的样本会有相同的值,组内求完均值后会按照原索引的顺序返回结果
2.4 apply方法
之前我们介绍过对Dataframe使用apply进行灵活数据变换操作处理的方法,它支持传入自定义函数,实现复杂数据操作。apply除了之前介绍的用法,也可以用在groupby后,我们一起来学习一下。
对于groupby后的apply,实际上是以分组后的子DataFrame作为参数传入指定函数的,基本操作单位是DataFrame,而之前介绍的apply的基本操作单位是Series。我们通过一个案例来理解一下。
加入我们需要获取各个公司年龄最大的员工的数据,可以通过以下代码实现:
def get_oldest_staff(x):
df = x.sort_values(by = 'age',ascending=True)
return df.iloc[-1,:]
oldest_staff = data.groupby('company',as_index=False).apply(get_oldest_staff)
oldest_staff
我们对上面的过程图解帮助理解:

本例中的apply传入函数的参数由Series变成这里的分组DataFrame。相比于agg和transform,apply方法拥有更大的灵活性,但它的运行效率会比agg和transform慢。所以,groupby之后怼数据做操作,优先使用agg和transform,其次再考虑使用apply进行操作。
一键运行所有代码
图解数据分析系列 配套的所有代码,可前往ShowMeAI 官方 GitHub,下载后即可在本地 Python 环境中运行。能访问 Google 的宝宝也可以直接借助 Google Colab一键运行与交互学习!
下载数据分析速查表
Awesome cheatsheets | ShowMeAI速查表大全 系列包含『编程语言』『AI技能知识』『数据科学工具库』『AI垂直领域工具库』四个板块,追平到工具库当前最新版本,并跑通了所有代码。点击 官网 或 GitHub 获取~

👇 数据分析相关速查表(部分):
| 内容 | 速查表(部分) | Github代码 |
|---|---|---|
| Python 3速查表 |  | 一键运行速查表代码 - Python |
| Numpy 速查表 |  | 一键运行速查表代码 - Numpy |
| Pandas 速查表 |  | 一键运行速查表代码 - Pandas |
| Matplotlib 速查表 |  | 一键运行速查表代码 - Matplotlib |
| Seaborn 速查表 |  | 一键运行速查表代码 - Seaborn |
拓展参考资料
- 利用Python进行数据分析·第2版
- w3schools pandas tutorial
- Kaggle的Pandas入门教程
- 十分钟入门 Pandas
- Pandas可视化教程
- Pandas官方教程
- Seaborn官方教程
ShowMeAI图解数据分析系列推荐(数据科学家入门)
- 图解数据分析(1) | 数据分析介绍
- 图解数据分析(2) | 数据分析思维
- 图解数据分析(3) | 数据分析的数学基础
- 图解数据分析(4) | 核心步骤1 - 业务认知与数据初探
- 图解数据分析(5) | 核心步骤2 - 数据清洗与预处理
- 图解数据分析(6) | 核心步骤3 - 业务分析与数据挖掘
- 图解数据分析(7) | 数据分析工具地图
- 图解数据分析(8) | Numpy - 统计与数据科学计算工具库介绍
- 图解数据分析(9) | Numpy - 与1维数组操作
- 图解数据分析(10) | Numpy - 与2维数组操作
- 图解数据分析(11) | Numpy - 与高维数组操作
- 图解数据分析(12) | Pandas - 数据分析工具库介绍
- 图解数据分析(13) | Pandas - 核心操作函数大全
- 图解数据分析(14) | Pandas - 数据变换高级函数
- 图解数据分析(15) | Pandas - 数据分组与操作
- 图解数据分析(16) | 数据可视化原则与方法
- 图解数据分析(17) | 基于Pandas的数据可视化
- 图解数据分析(18) | 基于Seaborn的数据可视化
ShowMeAI系列教程精选推荐
- 大厂技术实现:推荐与广告计算解决方案
- 大厂技术实现:计算机视觉解决方案
- 大厂技术实现:自然语言处理行业解决方案
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读
















 1331
1331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











