







今天我们将结合SPSS软件,向大家介绍在回归模型中何如实现哑变量的设置,并对引入哑变量后的模型结果进行解读。
Logistic /Cox回归
在SPSS中,Logistic回归和Cox回归设置哑变量的方式是一致的,因此本文以Logistic回归为例进行说明。
一、研究实例
某研究人员拟探讨不同种族人群中某疾病发病风险有无差异,收集了4种不同种族人群的相关数据资料(1=Black美国黑人,2=White美国白人,3=Indian美国印第安人,4=Asian亚裔美国人)。
根据数据类型判断,种族为无序多分类资料,需要将种族转化为哑变量后,进行Logistic回归。
二、SPSS操作
1. Analyze → Regression → Binary Logistic,进入到Logistic回归模块
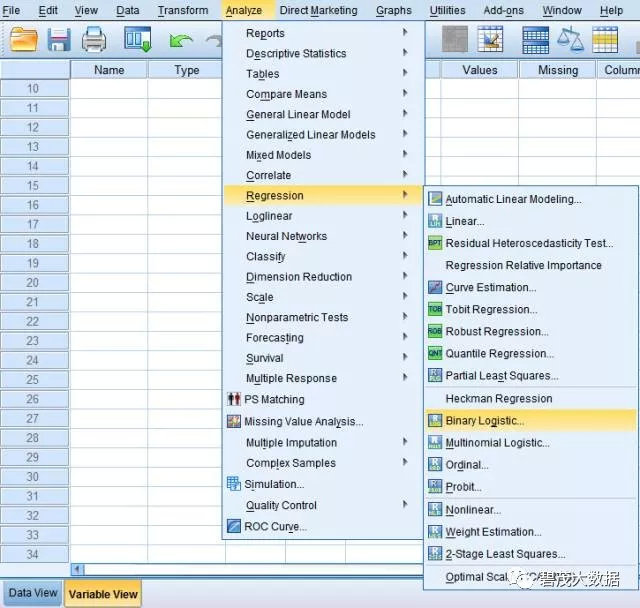
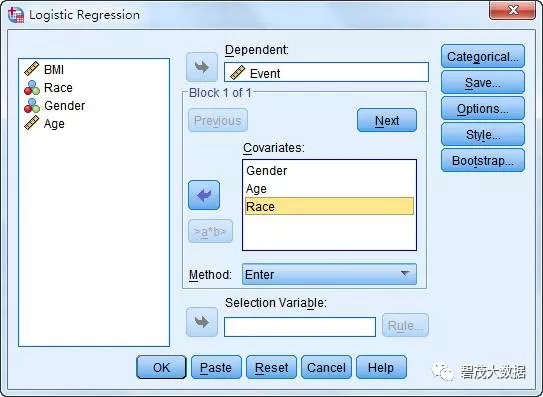
2. 将Event选入Dependent框中,将Gender、Age、Race选入Covariates框中
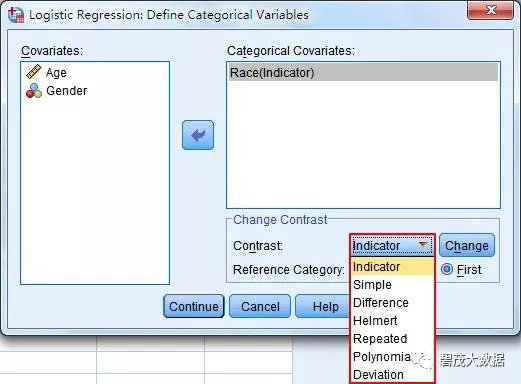
3. 点击Categorical进入定义分类变量的对话框,将需要转化的变量Race选入Categorical Covariates框中,点击Contrast旁的下拉框选择Indicator,Reference Category设置为First,即设定第一个分类为参照。
在本次研究中,Race=1为黑人,即我们选择黑人作为参照。最后再点击Change确认更改为Race(Indicator(first))。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 7711
7711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











