







 本文主要探讨了Linux系统中的进程间通信(IPC)机制,包括管道、信号、共享内存、信号量和消息队列,以及线程间通信机制,如互斥锁、条件变量和POSIX匿名信号量。内容参考了《深入分析linux内核源代码》等书籍,旨在理清系统编程和网络编程中的关键概念。请注意,书中分析的是2.4.16版本的内核,与最新内核可能存在差异。
本文主要探讨了Linux系统中的进程间通信(IPC)机制,包括管道、信号、共享内存、信号量和消息队列,以及线程间通信机制,如互斥锁、条件变量和POSIX匿名信号量。内容参考了《深入分析linux内核源代码》等书籍,旨在理清系统编程和网络编程中的关键概念。请注意,书中分析的是2.4.16版本的内核,与最新内核可能存在差异。
注:本分类下文章大多整理自《深入分析linux内核源代码》一书,另有参考其他一些资料如《linux内核完全剖析》、《linux c 编程一站式学习》等,只是为了更好地理清系统编程和网络编程中的一些概念性问题,并没有深入地阅读分析源码,我也是草草翻过这本书,请有兴趣的朋友自己参考相关资料。此书出版较早,分析的版本为2.4.16,故出现的一些概念可能跟最新版本内核不同。
此书已经开源,阅读地址 http://www.kerneltravel.net
一、管道
![]()
![]()
![]()
![]()
![]()
在Linux 中,管道是一种使用非常频繁的通信机制。从本质上说,管道也是一种文件,但
它又和一般的文件有所不同,管道可以克服使用文件进行通信的两个问题,具体表现如下所述。
• 限制管道的大小。实际上,管道是一个固定大小的缓冲区。在Linux 中,该缓冲区的
大小为1 页,即4KB,使得它的大小不像文件那样不加检验地增长。使用单个固定缓冲区也
会带来问题,比如在写管道时可能变满,当这种情况发生时,随后对管道的write()调用将
默认地被阻塞,等待某些数据被读取,以便腾出足够的空间供write()调用写。
• 读取进程也可能工作得比写进程快。当所有当前进程数据已被读取时,管道变空。当
这种情况发生时,一个随后的read()调用将默认地被阻塞,等待某些数据被写入,这解决了
read()调用返回文件结束的问题。
注意,从管道读数据是一次性操作,数据一旦被读,它就从管道中被抛弃,释放空间以
便写更多的数据。
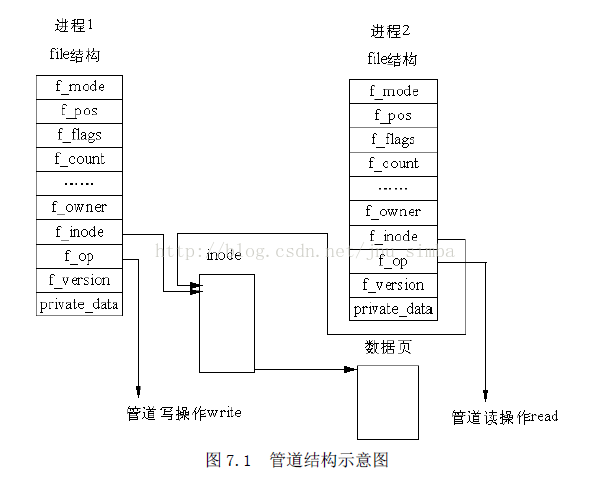
(一)、管道的结构
在Linux 中,管道的实现并没有使用专门的数据结构,而是借助了文件系统的file 结
构和VFS 的索引节点inode。通过将两个 file 结构指向同一个临时的 VFS 索引节点,而这
个 VFS 索引节点又指向一个物理页面而实现的。如图7.1 所示。
图7.1 中有两个 file 数据结构,但它们定义文件操作例程地址是不同的,其中一个
是向管道中写入数据的例程地址,而另一个是从管道中读出数据的例程地址。这样,用户
程序的系统调用仍然是通常的文件操作,而内核却利用这种抽象机制实现了管道这一特殊
操作。
一个普通的管道仅可供具有共同祖先的两个进程之间共享,并且
这个祖先必须已经建立了供它们使用的管道。
注意,在管道中的数据始终以和写数据相同的次序来进行读,这表示lseek()系统调用
对管道不起作用。
二、信号
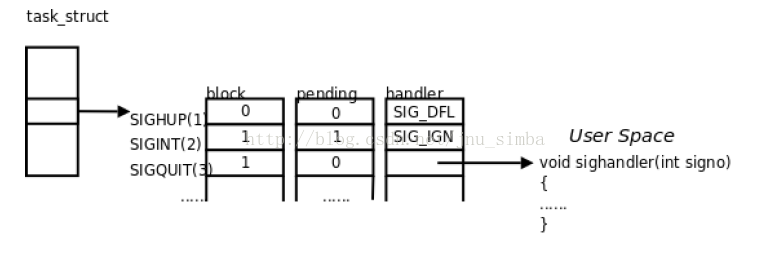
(一)、信号在内核中的表示
中断的响应和处理都发生在内核空间,而信号的响应发生
在内核空间,信号处理程序的执行却发生在用户空间。
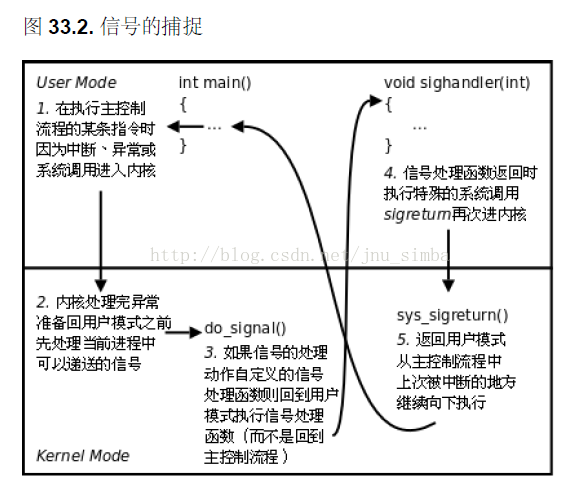
那么,什么时候检测和响应信号呢?通常发生在以下两种情况下:
(1)当前进程由于系统调用、中断或异常而进入内核空间以后,从内核空间返回到用户
空间前夕;
(2)当前进程在内核中进入睡眠以后刚被唤醒的时候,由于检测到信号的存在而提前返
回到用户空间。
当有信号要响应时,处理器执行路线的示意图如图33.2 所示。
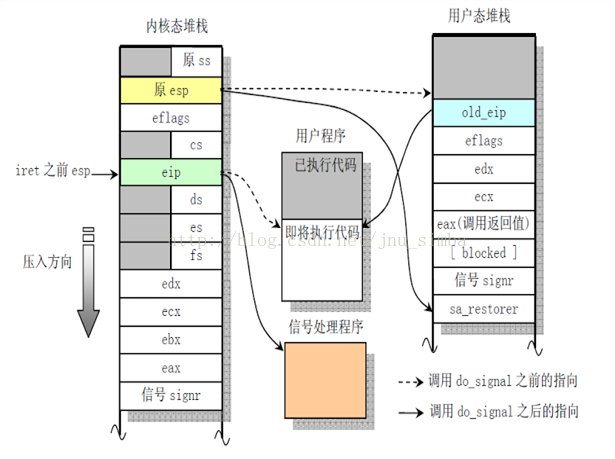
当用户进程通过系统调用刚进入内核的时候,CPU会自动在该进程的内核栈上压入下图所示的内容:
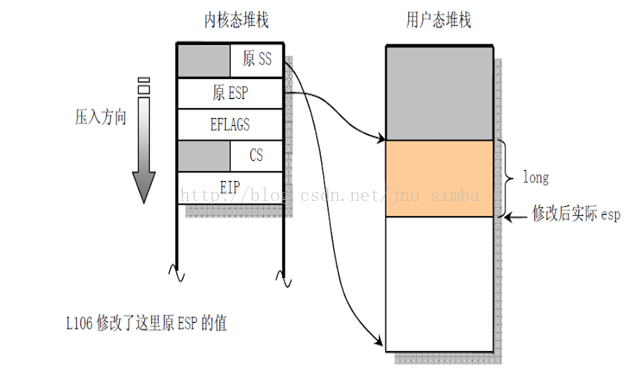
在处理完系统调用以后,就要调用do_signal()函数进行设置frame等工作。这时内核堆栈的状态应该跟下图左半部分类似(系统调用将一些信息压入栈了):
在找到了信号处理函数之后,do_signal() 函数首先把内核堆栈中存放返回执行点的eip保存为old_eip
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2607
2607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









