







学习来源:https://github.com/datawhalechina/team-learning/blob/master/机器学习算法基础/Task2%20bayes_plus.ipynb
知识点梳理:
1.相关概念(生成模型、判别模型)
2.先验概率、条件概率
3.贝叶斯决策理论
4.贝叶斯定理公式
5.极值问题情况下的每个类的分类概率
6.下溢问题如何解决
7.零概率问题如何解决?
8.优缺点
9.sklearn参数详解,Python绘制决策树
sklearn接口
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.model_selection import train_test_split
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)
clf = GaussianNB().fit(X_train, y_train)
print ("Classifier Score:", clf.score(X_test, y_test))sklearn参数详解:
1.高斯朴素贝叶斯算发是假设特征的可能性(即概率)为高斯分布。
class sklearn.naive_bayes.GaussianNB(priors=None)
参数:
priors:先验概率大小,如果没有给定,模型则根据样本数据自己计算(利用极大似然法)。
var_smooth:可选参数,所有特征的最大方差
class_prior:每个样本的概率
class_count:每个类别的样本数量
classes_:分类器已知的标签类型
theta_:每个类别中每个特征的均值
sigma_:每个类别中每个特征的方差
epsilon_:方差的绝对加值方法
贝叶斯的方法和其他模型的方法一致。
fit(X,Y):在数据集(X,Y)上拟合模型。
get_params():获取模型参数。
predict(X):对数据集X进行预测。
predict_log_proba(X):对数据集X预测,得到每个类别的概率对数值。
predict_proba(X):对数据集X预测,得到每个类别的概率。
score(X,Y):得到模型在数据集(X,Y)的得分情况。
根据李航老师的代码构建自己的朴素贝叶斯模型
这里采用**GaussianNB 高斯朴素贝叶斯,**概率密度函数为
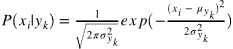
数学期望:
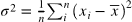
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
import math
# data
def create_data():
iris = load_iris( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









