







2025年4月1日,OpenAI宣布其最新的 GPT-4o 模型正式对免费用户开放强大的“文生图”功能!这一功能不仅重新定义了 AI 生成内容的边界,还在全球范围内引发了用户量的爆炸式增长。
一、吉卜力风格漫画:GPT-4o破圈关键
GPT-4o文生图功能上线后迅速引发全球热潮,仅“吉卜力风格”图片就已刷屏社交媒体。用户只需简单描述,即可生成高质量创意图像,这种便捷性吸引了大量新用户。
只需要输入提示词:吉卜力漫画风格,中间写着OpenAI和GPT-4o。GPT-4o的字体略小。

也可以生成统一风格的吉卜力漫画。如果需要对图片进行多次调整,可以利用 GPT-4o 的多轮对话能力,通过文字指令一步步“调教”出理想效果。

或者直接上传图片,然后让GPT-4o转换成吉卜力。这种风格转换在国内外都被广泛使用。


甚至还有用户通过GPT-4o+快手可灵生成了一个吉卜力风格的《指环王》预告片
sinokap
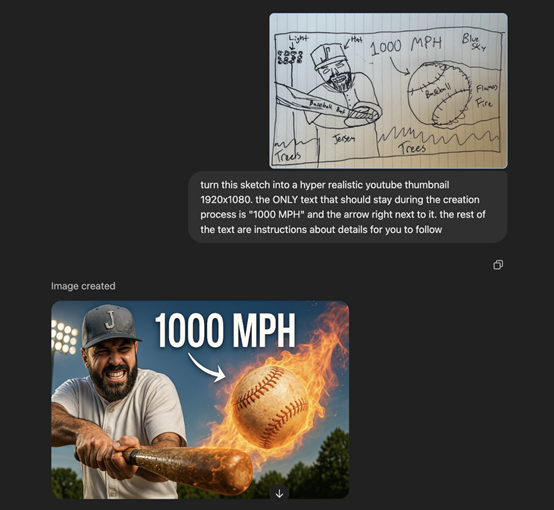
除了风格变换之外,GPT-4o 还能够将草图直接转化为成品图片,对设计师而言可节省大量时间。例如,上传一张草图,然后提示:将这幅草图转化为一张超写实的YT缩略图,尺寸为 1920x1080。在创作过程中唯一应保留的文字是 “1000 MPH” 以及它旁边的箭头,其余的文字都是供你遵循的关于细节方面的指示。
也可以秒出设计图,比如上传一张随机的鞋子图片,并提示:80 年代的创意广告,阿迪达斯风格。

看了这些示例是不是心动了呢?感兴趣的小伙伴可以亲自尝试一下!需要提醒的是,虽然 GPT-4o 支持中文提示,但为了更精准地呈现文本需求,最好使用英文描述哦。
二、GPT-4o多模态AI的关键时间节
2024年5月13日 - May 13, 2024
OpenAI 发布 GPT-4o 模型,标志着多模态 AI 技术的全新突破。该模型可处理文本、图像、音频和视频等多种形式的输入。作为核心亮点之一,“文生图”功能也在同日上线,但最初仅面向付费用户。
2025年3月25日 - March 25, 2025
OpenAI推出GPT-4o的原生图像生成功能,允许用户通过自然语言提示创建或编辑图片。这一功能进一步优化了文本与图像的结合能力,吸引了大量创作者和企业用户。
2025年4月1日 - April 1, 2025
OpenAI宣布GPT-4o文生图功能向免费用户开放,但每天仅限生成三张图片。此举进一步扩大了用户群体,推动了ChatGPT的活跃用户数突破5亿。

三、GPT-4o文生图功能:从DALL-E到全新突破
在图像生成领域,OpenAI 此前推出的 DALL-E 系列模型已成为行业标杆。然而,GPT-4o 的文生图功能并非 DALL-E 系列的简单升级版,而是一次彻底的技术革新。与 DALL-E 系列相比,GPT-4o 在多方面都有显著提升。

GPT-4o采用自回归生成技术,将语言理解与图像生成整合为一个过程。这种架构使其能够在对话中保持上下文一致性,并根据用户反馈实时优化图片。相比之下,DALL-E 3虽然改进了图像质量,但仍局限于模块化流程,无法实现自然交互。
四、GPU短缺:AI行业的新瓶颈
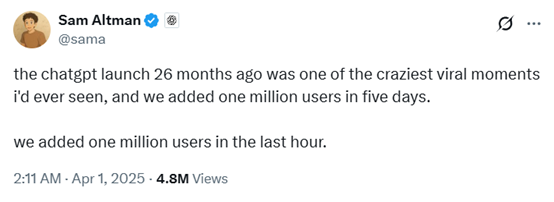
2025年4月1日,OpenAI 联合创始人兼首席执行官 Sam Altman 在社交媒体上提到:“26个月前推出的 ChatGPT 是我见过的最疯狂的病毒式传播事件之一。我们在五天内就新增了100万用户,而就在过去的一个小时里,我们又新增了 100 万用户。“
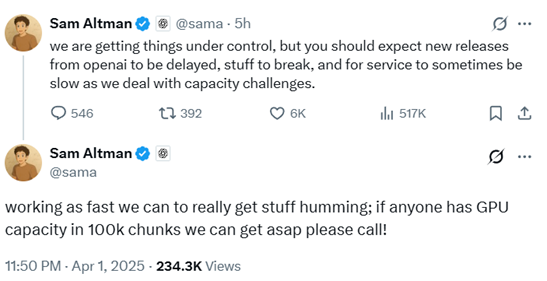
随后,他宣布 GPT-4o 的文生图功能再次免费开放,然而其火爆程度依旧远超预期。这种爆炸式增长使得 OpenAI 的算力资源面临前所未有的挑战。随着用户需求激增,OpenAI 不得不应对 GPU 资源短缺的问题。Sam Altman 在社交媒体上紧急呼吁供应商提供 10 万块 GPU 以缓解困境,否则新功能的上线进度可能被延缓,已有的服务也可能面临速度减慢的风险。
ChatGPT培训服务申请
想让团队快速掌握 ChatGPT 技能,并将其应用于企业的各个业务场景吗?Sinokap 始终致力于为企业提供高效、全面的 IT 服务解决方案,包括 IT 工程师驻场服务、企业软件开发、系统集成、硬件采购及 IT 咨询 等全方位支持。同时,我们还推出了一系列增值培训服务,帮助企业员工从零基础到高级应用,全面掌握 ChatGPT 相关技能,让 “文生图” 等 AI 功能在实际工作中充分发挥价值。
如果您正考虑将 GPT-4o 文生图功能或其他 AI 技术引入企业,欢迎随时与我们联系,Sinokap与您共同挖掘 AI 时代的新机遇,为您的企业开启数字化转型的全新篇章。


















 1088
1088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









