







来这里人应该都知道redis是缓存数据库,它是以Key-Value的形式存储数据的,所以如何根据自己的系统选择合适的数据结构及其重要,合理的设计才会让redis充分发挥它的优势。
一、首先,我们来看看Key键的设计:
Key是字符串类型, 不能太长,比如1024字节,但也不能太短如”u:1000:pwd”,要表达清楚意思才好。私人建议用”:”分隔域,用”.”作为单词间的连接。
即:KEY(表名/业务名:数据类型:filed.id)
如”dict:json:dictid.600101”,表示字典表中ID为600101的对象,对象使用json字符串表示。
二、Value
1、在谈value之前,先来了解一下redis常用的数据类型,这个很重要,Redis最为常用的数据类型主要有以下:
1. String
2. Hash
3. List
4. Set
5. Sorted set
6. pub/sub
7. Transactions
关于Redis内部内存管理中是如何描述这些不同数据类型的,可以参考下图理解
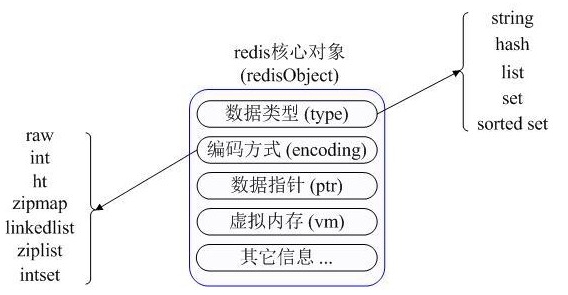
2、了解各种数据类型应用场景和实现方式:
有一篇文章介绍得不错,在此借用一下,我就不写了,^_^
http://blog.csdn.net/isoleo/article/details/46484127
大家可以仔细阅读一下,我们一般用得比较多的,是hash,它特别适合存储对象,比如说我们要在系统启动时加载数据字典表,我们可设计为
Key:dict:map:object.id
Value:map[id,objectJson]
Dict对象转成JSON字符串处理,也可以将实体对象序列化后保存,这里使用JSON:
String jsonValue = JSON.toJSONString(entity);
jedisCluster.hset(key, mapKey, jsonValue);项目刚刚开始,应用的场景还不是很丰富,后期会观察业务使用情况,评估需要采用redis的场景,改造项目,还有个小原则补充一下:
1、重要的数据:先存到数据库,然后存到redis
2、要求响应速度很高的的数据:先写缓存,然后通过消息队列再写入数据库
好了,这一章就先写到这里,后期会对这一章继续深化,分析应用场景,优化数据结构设计;
下一篇将讨论使用Spring aop技术来整合redis,这样就可以使用注解的方式,无缝无侵入式完成对redis的整合。















 767
767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









