






《Transfer Joint Matching for Unsupervised Domain Adaptation》学习
IEEE Conference on Computer Vision & Pattern Recognition
文章目录
摘要
以往的研究大多探索了两种独立的领域适应学习策略:特征匹配和实例重新加权。
在本文中,我们证明了当域差异很大时,这两种策略都是重要且不可避免的。
因此,我们提出了一种新的传输联合匹配(TJM)方法,在统一的优化问题中对其进行建模。
具体而言,TJM旨在通过联合匹配特征并在主降维过程中重新加权跨域实例来减少域差异,并构建新的特征表示,该表示对分布差异和无关实例都是不变的。
一、介绍
在跨域问题中,源数据和目标数据通常从不同的概率分布中采样。
最近的大多数研究都探索了两种独立的领域适应学习策略:
- 特征匹配,通过共同减小分布差异和保留输入数据的重要属性来发现共享的特征表示
- 实例加权,通过对源数据进行加权,使分布差异最小化,然后在加权后的源数据上训练分类器
图1展示了一个困难的设置:当域差异很大时,总是存在一些与目标实例无关的源实例,即使在特征匹配子空间中也是如此。
最近的工作还探索了联合特征重加权和子空间学习,其中不相关的特征被降权。
然而,在视觉域适应中,域差异很大,很难定义原始特征与不同域的相关性。
因此,我们提出了一种新的域适应解决方案,称为迁移联合匹配(TJM),在一个有原则的降维过程中,联合执行跨域的特征匹配和实例加权。
具体地说,我们通过在无限维再生核希尔伯特空间(RKHS)中,最小化非参数最大平均偏差(MMD)来实现特征匹配。
通过最小化源实例上的
l
2
,
1
l_{2,1}
l2,1范数结构化稀疏惩罚来实现实例的权重调整。
我们将MMD的最小化和
l
2
,
1
l_{2,1}
l2,1范数与主成分分析(PCA)相结合,构建了有效的域不变量特征表示,用于显著的域差异。
针对TJM优化问题,提出了一种具有收敛性分析的学习算法。
我们的结果揭示了联合特征匹配和实例加权在领域适应方面的显著效果。
二、相关工作
根据文献的调查,现有的域适应方法大致可以分为两类:特征匹配和实例加权。
特征匹配方法是通过学习一种新的特征表示来减小分布差异。
特征表示可以通过:
- 提取域不变潜因子
- 最小化适当的距离测量
- 利用稀疏促进正则化对相关特征进行加权
实例权重调整方法的目的是根据源实例与目标实例的相关性来调整源实例的权重,从而减少分布差异。
据我们所知,我们的工作是视觉领域适应的第一次尝试,它在一个有原则的降维过程中执行联合特征匹配和实例重加权。
三、迁移联合匹配
在本节中,我们提出了传输联合匹配(TJM)方法,以有效和鲁棒的域适应。
3.1问题定义
为了清晰起见,表1总结了常用的符号

对于矩阵
A
∈
R
n
×
k
A\in \mathbb{R}^{n\times k}
A∈Rn×k,表示第i行为
a
i
a^i
ai,第j列为
a
j
a_j
aj,Frobenius范数为
∥
A
∥
F
=
∑
i
=
1
n
∥
a
i
∥
2
2
\|A\|_F=\sqrt{\sum^n_{i=1}\|a^i\|^2_2}
∥A∥F=∑i=1n∥ai∥22,
l
2
,
1
l_{2,1}
l2,1范数为
∥
A
∥
2
,
1
=
∑
i
=
1
n
∥
a
i
∥
2
\|A\|_{2,1}=\sum^n_{i=1}\|a^i\|_2
∥A∥2,1=∑i=1n∥ai∥2
定义1(域)。
域
D
D
D由m维特征空间
X
X
X和边际概率分布
P
(
X
P (X
P(X)组成,即
D
=
{
X
,
P
(
X
)
}
D = \{X, P (X)\}
D={X,P(X)},其中
x
∈
X
x\in X
x∈X。
定义2(任务)。
给定域
D
D
D,任务
T
T
T由c -基数标签集
Y
Y
Y和分类器
f
(
x
)
f(x)
f(x)组成,即
T
=
{
Y
,
f
(
x
)
}
T = \{Y, f(x)\}
T={Y,f(x)},其中
y
∈
Y
y\in Y
y∈Y,
f
(
x
)
=
Q
(
Y
∣
x
)
f(x) = Q(Y |x)
f(x)=Q(Y∣x)可以解释为条件概率分布。
问题1(迁移联合匹配)。
给定一个标记源域
D
s
=
{
(
x
1
,
y
1
)
,
…
,
(
x
n
s
,
y
n
s
)
}
D_s = \{(x_1, y_1),\dots, (x_{n_s}, y_{n_s})\}
Ds={(x1,y1),…,(xns,yns)}和一个未标记的目标域
D
t
=
{
x
n
s
+
1
,
…
,
x
n
s
+
n
t
}
D_t = \{x_{n_s+1},\dots, x_{n_s+n_t}\}
Dt={xns+1,…,xns+nt}在
X
s
=
X
t
,
Y
s
=
Y
t
,
P
s
(
X
s
)
≠
P
t
(
X
t
)
,
Q
s
(
Y
s
∣
X
s
)
≠
Q
t
(
Y
t
∣
X
t
)
X_s = X_t, Y_s = Y_t, P_s(X_s) \ne P_t(X_t), Q_s(Y_s | X_s) \ne Q_t(Y_t | X_t)
Xs=Xt,Ys=Yt,Ps(Xs)=Pt(Xt),Qs(Ys∣Xs)=Qt(Yt∣Xt)下,通过联合(1)匹配特征分布和(2)跨域重加权源实例,学习一种新的特征表示来减少域差异。
3.2提出方法
在本文中,我们提出通过特征变换T来适应不同的域,以便
- 通过距离最小化来跨域匹配特征
- 通过结构化稀疏性对源实例重新加权:
min T ∈ H ∥ E p ( x s ) [ T ( x s ) ] − E p ( x t ) [ T ( x t ) ] ∥ 2 + λ ∥ T ∥ 2 , 1 (1) \min_{T\in \mathcal{H}}\|\mathbb{E}_{p(x_s)}[T(x_s)]-\mathbb{E}_{p(x_t)}[T(x_t)]\|^2+\lambda\|T\|_{2,1}\tag{1} T∈Hmin∥Ep(xs)[T(xs)]−Ep(xt)[T(xt)]∥2+λ∥T∥2,1(1)
有两个关键因素决定了该方法:
- 特征匹配应在再生核希尔伯特空间(RKHS) H \mathcal{H} H中进行,以匹配一阶和高阶统计量;
- 结构化稀疏性应该在实例空间而不是特征空间中进行,否则我们会进行特征的权重调整而不是实例的权重调整。
3.2.1降维
降维方法通过最小化输入数据的重构误差来学习转换后的特征表示。
为了简单和通用性,我们将选择主成分分析(Principal Component Analysis, PCA)进行数据重构。
表示
X
=
[
x
1
,
…
,
x
n
]
∈
R
m
×
n
X = [x_1,\dots,x_n]\in\mathbb R^{m\times n}
X=[x1,…,xn]∈Rm×n为输入数据矩阵,
H
=
I
−
1
n
1
H = I−\frac{1} {n}1
H=I−n11为中心矩阵,其中
n
=
n
s
+
n
t
n = n_s + n_t
n=ns+nt,
1
1
1为
1
1
1的
n
×
n
n \times n
n×n矩阵,则协方差矩阵可计算为
X
H
X
T
XHX^T
XHXT。
PCA的学习目标是找到一个正交变换矩阵
V
∈
R
m
×
k
V\in \mathbb{R}^{m\times k}
V∈Rm×k,使嵌入数据方差最大化:
max
V
T
V
=
I
t
r
(
V
T
X
H
X
T
V
)
(2)
\max_{V^TV=I}tr(V^TXHX^TV)\tag{2}
VTV=Imaxtr(VTXHXTV)(2)
其中
t
r
(
⋅
)
tr(\cdot)
tr(⋅)表示矩阵的迹,通过特征分解
X
H
X
T
V
=
V
Φ
XHX^TV = V\Phi
XHXTV=VΦ,其中
Φ
=
d
i
a
g
(
ϕ
1
,
…
,
ϕ
k
)
∈
R
k
×
k
\Phi = diag(\phi_1,\dots, \phi_k)\in \mathbb{R}^{k\times k}
Φ=diag(ϕ1,…,ϕk)∈Rk×k是最大的k个特征值。然后我们用
Z
=
[
z
1
,
…
,
z
n
]
=
V
T
X
Z = [z_1,\dots, z_n] = V^TX
Z=[z1,…,zn]=VTX,找到最优的k维表示。
内核化: 要在
R
K
H
S
RKHS
RKHS中工作,请考虑内核映射
ψ
:
x
↦
ψ
(
x
)
\psi: x \mapsto \psi(x)
ψ:x↦ψ(x)或者
ψ
(
x
)
=
[
ψ
(
x
1
)
,
…
ψ
(
x
n
)
]
\psi(x) = [\psi(x_1),\dots\psi(x_n)]
ψ(x)=[ψ(x1),…ψ(xn)],内核矩阵
K
=
ψ
(
X
)
T
ψ
(
X
)
∈
R
n
×
n
K =\psi(X) ^T\psi(X)\in\mathbb{R}^{n\times n}
K=ψ(X)Tψ(X)∈Rn×n。
利用代表定理
V
=
ϕ
(
X
)
A
V = \phi (X) A
V=ϕ(X)A对PCA 进行核化
max
A
T
A
=
I
t
r
(
A
T
K
H
K
T
A
)
(3)
\max_{A^TA=I}tr(A^TKHK^TA)\tag{3}
ATA=Imaxtr(ATKHKTA)(3)
其中
A
∈
R
n
×
k
A\in \mathbb{R}^{n\times k}
A∈Rn×k是KernelPCA的变换矩阵,子空间嵌入变为
Z
=
A
T
K
Z = A^TK
Z=ATK。
3.2.2特征匹配
域适应的一个主要计算问题是,通过显式地最小化适当的距离度量,来减少特征分布的差异。
由于参数估计分布的概率密度是一个非平凡的问题,我们求助于匹配不同分布的一阶和高阶统计量。
在本文中,我们采用经验的最大平均偏差(Maximum Mean difference, MMD)作为非参数距离度量来比较RKHS中的不同分布。
MMD利用Kernel-PCA提取的k维嵌入计算源数据和目标数据的经验期望之间的距离:
∥
1
n
s
∑
i
=
1
n
s
A
T
k
i
−
1
n
t
∑
j
=
n
s
+
1
n
s
+
n
t
A
T
k
j
∥
H
2
=
t
r
(
A
T
K
M
K
T
A
)
(4)
\left\|\frac{1}{n_s}\sum^{n_s}_{i=1}A^Tk_i-\frac{1}{n_t}\sum^{n_s+n_t}_{j=n_s+1}A^Tk_j\right\|^2_{\mathcal{H}}=tr(A^TKMK^TA)\tag{4}
∥
∥ns1i=1∑nsATki−nt1j=ns+1∑ns+ntATkj∥
∥H2=tr(ATKMKTA)(4)
其中M为MMD矩阵,计算公式如下:
M
i
j
=
{
1
n
s
n
s
,
X
i
,
X
j
∈
D
s
1
n
t
n
t
,
X
i
,
X
j
∈
D
t
−
1
n
s
n
t
,
otherwise
\begin{equation} M_{ij}= \begin{cases} \frac{1}{n_sn_s},& \text{ $ X_i,X_j \in D_s$ } \\ \frac{1}{n_tn_t},& \text{ $ X_i,X_j \in D_t$ } \\ \frac{-1}{n_sn_t},& \text{ otherwise}\tag{5} \end{cases} \end{equation}
Mij=⎩
⎨
⎧nsns1,ntnt1,nsnt−1, Xi,Xj∈Ds Xi,Xj∈Dt otherwise(5)
通过最小化式(4)使式(3)最大化,在新的表示
Z
=
A
T
K
Z = A^TK
Z=ATK下匹配特征分布的一阶和高阶统计量。
请注意,我们只是将TJM开发为类似于TCA
3.2.3事例再加权
如果我们还需要匹配无限维RKHS中的特征分布,那么对源实例重新加权就不是件小事。
最近的工作通过核均值匹配、样本选择和共同训练来执行实例重加权。
但如何将它们与特征匹配相结合以获得更好的性能还不清楚
本文提出在变换矩阵A上引入
l
2
,
1
l_{2,1}
l2,1范数的结构化稀疏正则化器,使变换矩阵具有行稀疏性。
由于矩阵A的每一行对应一个实例,行稀疏性本质上可以促进自适应实例权重调整。
我们定义实例加权正则化器:
∥
A
s
∥
2
,
1
+
∥
A
t
∥
F
2
(6)
\|A_s\|_{2,1}+\|A_t\|^2_F\tag{6}
∥As∥2,1+∥At∥F2(6)
其中
A
s
:
=
A
1
:
n
s
,
:
A_s:= A_{1:n_s,:}
As:=A1:ns,:是源实例对应的转换矩阵,
A
t
:
=
A
n
s
+
1
:
n
s
+
n
t
,
:
A_t:= A_{n_s+1:n_s+n_t},:
At:=Ans+1:ns+nt,:是目标实例对应的转换矩阵。
我们只对源实例施加
l
2
,
1
l_{2,1}
l2,1范数正则化器,因为我们的目标是通过源实例与目标实例的相关性来重新加权。
通过最小化方程(6)使方程(3)最大化,与目标实例相关(不相关)的源实例在新的表示
Z
=
A
T
K
Z = A^TK
Z=ATK中自适应地重新加权,使其重要性更大(更小)。
有了这个正则化器,TJM对不相关实例引起的域差异具有鲁棒性。
在联合特征学习中,特征根据其与特定领域的相关性重新加权。
然而,在视觉域适应问题中,域差异很大,很难定义特征与不同域的相关性。
因此,联合特征学习方法可能不得不努力解决跨域图像识别问题。
3.2.4优化问题
将式(4)、(6)带入式(3),得到TJM优化问题:
min
A
T
K
H
K
T
A
=
I
t
r
(
A
T
K
M
K
T
A
)
+
λ
(
∥
A
s
∥
2
,
1
+
∥
A
t
∥
F
2
)
(7)
\min_{A^TKHK^TA=I}tr(A^TKMK^TA)+\lambda\left(\|A_s\|_{2,1}+\|A_t\|^2_F\right)\tag{7}
ATKHKTA=Imintr(ATKMKTA)+λ(∥As∥2,1+∥At∥F2)(7)
其中
λ
\lambda
λ是正则化参数,以权衡特征匹配和实例重加权。
为了突出它的功能,我们将
A
A
A称为后续中的适应性矩阵。
TJM的一个重要优势是,它能够同时匹配特征分布,在主降维过程中重新加权源实例。
3.3学习算法
根据约束优化理论,我们表示
Φ
=
d
i
a
g
(
ϕ
1
,
…
,
ϕ
k
)
∈
R
k
×
k
\Phi=diag(\phi _1,\dots,\phi _k)\in\mathbb{R}^{k\times k}
Φ=diag(ϕ1,…,ϕk)∈Rk×k作为拉格朗日乘子,导出问题(7)的拉格朗日函数为:
L
=
t
r
(
A
T
K
M
K
T
A
)
+
λ
(
∥
A
s
∥
2
,
1
+
∥
A
t
∥
F
2
)
+
t
r
(
(
I
−
A
T
K
H
K
T
A
)
Φ
)
(8)
\begin{aligned}L=tr(A^TKMK^TA)+\lambda\left(\|A_s\|_{2,1}+\|A_t\|^2_F\right)\\ +tr((I-A^TKHK^TA)\Phi)\tag{8} \end{aligned}
L=tr(ATKMKTA)+λ(∥As∥2,1+∥At∥F2)+tr((I−ATKHKTA)Φ)(8)
令
∂
L
∂
A
=
0
\frac{\partial L}{\partial A}=0
∂A∂L=0,我们得到了广义特征分解:
(
K
M
K
T
+
λ
G
)
A
=
K
H
K
T
A
Φ
(9)
(KMK^T+\lambda G)A=KHK^TA\Phi\tag{9}
(KMKT+λG)A=KHKTAΦ(9)
∥
A
s
∥
2
,
1
\|A_s\|_{2,1}
∥As∥2,1在0点是一个非光滑函数,因此,我们计算其子梯度为
∂
(
∥
A
s
∥
2
,
1
+
∥
A
t
∥
F
2
)
∂
A
=
2
G
A
\frac{\partial \left(\|A_s\|_{2,1}+\|A_t\|^2_F\right)}{\partial A} = 2GA
∂A∂(∥As∥2,1+∥At∥F2)=2GA,其中
G
G
G是一个对角子梯度矩阵,第
i
i
i个元素等于:
G
i
i
=
{
1
2
∥
a
i
∥
,
X
i
∈
D
s
,
a
i
≠
0
0
,
X
i
∈
D
s
,
a
i
=
0
1
,
X
i
∈
D
t
\begin{equation} G_{ii}= \begin{cases} \frac{1}{2\|a^i\|},& \text{ $ X_i\in D_s,a^i\ne 0$ } \\ 0,& \text{ $ X_i\in D_s,a^i= 0$ } \\ 1,& \text{ $ X_i\in D_t$} \tag{10} \end{cases} \end{equation}
Gii=⎩
⎨
⎧2∥ai∥1,0,1, Xi∈Ds,ai=0 Xi∈Ds,ai=0 Xi∈Dt(10)
寻优自适应矩阵A简化为求解式(9)的k个最小特征向量。
完整的过程总结在算法1中。

3.4计算复杂度
我们表示T为迭代次数,那么k的典型值不大于500,T不大于50,那么
k
≪
min
(
m
,
n
),
T
≪
min
(
m
,
n
)
k\ll \min(m,n),T\ll \min(m,n)
k≪min(m,n),T≪min(m,n)。
计算成本详细如下:
O
(
m
n
2
)
O (mn^2)
O(mn2)计算核矩阵,即第2行;
O
(
T
k
n
2
)
O (Tkn^2)
O(Tkn2)求解密集矩阵广义特征分解问题,即第5行;
O
(
T
n
2
)
O (Tn^2)
O(Tn2)计算子梯度矩阵,即第6行。
算法1的计算复杂度为
O
(
T
k
n
2
+
m
n
2
)
O (Tkn^2 + mn^2)
O(Tkn2+mn2)
采用低秩近似可以大大降低算法的复杂度。
3.5收敛性分析
证明了算法1中的交替优化过程收敛于优化问题对应的A的最优解。
引理1。
假设
{
v
τ
i
}
i
=
1
r
\{v^i_τ\}^r_{i=1}
{vτi}i=1r为非零向量,r为任意数,则下列不等式成立:
∑
i
=
1
r
(
∥
v
T
+
1
i
∥
−
∥
v
T
+
1
i
∥
2
2
∥
v
T
i
∥
)
≤
∑
i
=
1
r
(
∥
v
T
i
∥
−
∥
v
T
i
∥
2
2
∥
v
T
i
∥
)
(11)
\sum^r_{i=1}\left(\|v^i_{\mathcal{T}+1}\|-\frac{\|v^i_{\mathcal{T}+1}\|^2}{2\|v^i_\mathcal{T}\|}\right)\le\sum^r_{i=1}\left(\|v^i_\mathcal{T}\|-\frac{\|v^i_\mathcal{T}\|^2}{2\|v^i_\mathcal{T}\|}\right)\tag{11}
i=1∑r(∥vT+1i∥−2∥vTi∥∥vT+1i∥2)≤i=1∑r(∥vTi∥−2∥vTi∥∥vTi∥2)(11)
定理1。算法1中的迭代优化,即第4 ~ 7行,每次迭代可以单调地减小式(7)中的目标函数,直到收敛。
证明:
表示
A
T
A_\mathcal{T}
AT和
G
T
G_\mathcal{T}
GT为迭代中的变量
T
\mathcal{T}
T。注意,
A
T
A_\mathcal{T}
AT依赖于
G
T
−
1
G_\mathcal{T-1}
GT−1,
G
T
G_\mathcal{T}
GT依赖于
A
T
A_\mathcal{T}
AT。基于特征分解原理,第5行算法1中的
A
T
A_\mathcal{T}
AT的计算满足后续优化
A
T
=
arg min
A
T
K
H
K
T
A
=
I
t
r
(
A
T
(
K
M
K
T
+
λ
G
T
−
1
)
A
)
A_\mathcal{T}=\argmin_{A^TKHK^TA=I}tr(A^T(KMK^T+\lambda G_{\mathcal{T}-1})A)
AT=ATKHKTA=Iargmintr(AT(KMKT+λGT−1)A)
为清晰起见,表示
W
=
K
M
K
T
+
λ
G
t
W = KMK^T+\lambda G_t
W=KMKT+λGt,其中,如果
x
t
∈
D
t
x_t\in D_t
xt∈Dt,
(
G
t
)
i
i
=
1
(G_t)_{ii} = 1
(Gt)ii=1,否则
(
G
t
)
i
i
=
0
(G_t)_{ii} = 0
(Gt)ii=0。
然后我们可以推导:
tr
(
A
τ
T
(
W
+
λ
G
τ
−
1
)
A
τ
)
≤
tr
(
A
τ
−
1
T
(
W
+
λ
G
τ
−
1
)
A
τ
−
1
)
⇒
tr
(
A
τ
T
W
A
τ
)
+
λ
∑
i
=
1
n
S
∥
a
T
i
∥
2
2
∥
a
T
−
1
i
∥
≤
tr
(
A
τ
−
1
T
W
A
T
−
1
)
+
λ
∑
i
=
1
n
S
∥
a
T
−
1
i
∥
2
2
∥
a
T
−
1
i
∥
⇒
tr
(
A
τ
T
W
A
τ
)
+
λ
∑
i
=
1
n
S
∥
a
τ
i
∥
−
λ
∑
i
=
1
n
S
(
∥
a
T
i
∥
−
∥
a
τ
i
∥
2
2
∥
a
T
−
1
i
∥
)
≤
tr
(
A
τ
−
1
T
W
A
τ
−
1
)
+
λ
∑
i
=
1
n
s
∥
a
τ
−
1
i
∥
−
λ
∑
i
=
1
m
(
∥
a
τ
−
1
i
∥
−
∥
a
τ
−
1
i
∥
2
2
∥
a
τ
−
1
i
∥
)
\begin{aligned} &\operatorname{tr}\left(\mathbf{A}_{\tau}^{T}\left(\mathbf{W}+\lambda \mathbf{G}_{\tau-1}\right) \mathbf{A}_{\tau}\right) \leq \operatorname{tr}\left(\mathbf{A}_{\tau-1}^{T}\left(\mathbf{W}+\lambda \mathbf{G}_{\tau-1}\right) \mathbf{A}_{\tau-1}\right)\\ &\Rightarrow \operatorname{tr}\left(\mathbf{A}_{\tau}^{\mathrm{T}} \mathbf{W A}_{\tau}\right)+\lambda \sum_{i=1}^{n_{S}} \frac{\left\|\mathbf{a}_{T}^{i}\right\|^{2}}{2\left\|\mathbf{a}_{T-1}^{i}\right\|} \leq \operatorname{tr}\left(\mathbf{A}_{\tau-1}^{T} \mathbf{W A}_{T-1}\right)+\lambda \sum_{i=1}^{n_{S}} \frac{\left\|\mathbf{a}_{T-1}^{i}\right\|^{2}}{2\left\|\mathbf{a}_{T-1}^{i}\right\|}\\ &\Rightarrow \operatorname{tr}\left(\mathbf{A}_{\tau}^{\mathrm{T}} \mathbf{W} \mathbf{A}_{\tau}\right)+\lambda \sum_{i=1}^{n_{S}}\left\|\mathbf{a}_{\tau}^{i}\right\|-\lambda \sum_{i=1}^{n_{S}}\left(\left\|\mathbf{a}_{T}^{i}\right\|-\frac{\left\|\mathbf{a}_{\tau}^{i}\right\|^{2}}{2\left\|\mathbf{a}_{T-1}^{i}\right\|}\right)\\ &\leq \operatorname{tr}\left(\mathrm{A}_{\tau-1}^{\mathrm{T}} \mathbf{W A}_{\tau-1}\right)+\lambda \sum_{i=1}^{n_{s}}\left\|\mathbf{a}_{\tau-1}^{i}\right\|-\lambda \sum_{i=1}^{m}\left(\left\|\mathbf{a}_{\tau-1}^{i}\right\|-\frac{\left\|\mathbf{a}_{\tau-1}^{i}\right\|^{2}}{2\left\|\mathbf{a}_{\tau-1}^{i}\right\|}\right) \end{aligned}
tr(AτT(W+λGτ−1)Aτ)≤tr(Aτ−1T(W+λGτ−1)Aτ−1)⇒tr(AτTWAτ)+λi=1∑nS2∥
∥aT−1i∥
∥∥
∥aTi∥
∥2≤tr(Aτ−1TWAT−1)+λi=1∑nS2∥
∥aT−1i∥
∥∥
∥aT−1i∥
∥2⇒tr(AτTWAτ)+λi=1∑nS∥
∥aτi∥
∥−λi=1∑nS(∥
∥aTi∥
∥−2∥
∥aT−1i∥
∥∥
∥aτi∥
∥2)≤tr(Aτ−1TWAτ−1)+λi=1∑ns∥
∥aτ−1i∥
∥−λi=1∑m(∥
∥aτ−1i∥
∥−2∥
∥aτ−1i∥
∥∥
∥aτ−1i∥
∥2)
利用引理1和
∥
A
∥
2
,
1
\|A\|_{2,1}
∥A∥2,1的定义,我们得到
tr
(
A
τ
T
W
A
τ
)
+
λ
∥
A
τ
(
s
)
∥
2
,
1
≤
tr
(
A
τ
−
1
T
W
A
τ
−
1
)
+
λ
∥
A
τ
−
1
(
s
)
∥
2
,
1
\operatorname{tr}\left(\mathbf{A}_{\tau}^{\mathrm{T}} \mathbf{W A}_{\tau}\right)+\lambda\|\mathbf{A}_{\tau}^{(s)}\|_{2,1}\le \operatorname{tr}\left(\mathbf{A}_{\tau-1}^{\mathrm{T}} \mathbf{W A}_{\tau-1}\right)+\lambda\|\mathbf{A}_{\tau-1}^{(s)}\|_{2,1}
tr(AτTWAτ)+λ∥Aτ(s)∥2,1≤tr(Aτ−1TWAτ−1)+λ∥Aτ−1(s)∥2,1
公式(7)中的目标函数在算法1的更新下单调减小
四、实验
在本节中,我们对图像分类问题进行了广泛的实验,以评估TJM方法。
4.1数据准备
USPS+MNIST、MSRC+VOC2007和Office+Caltech256(见图2和表2)是视觉领域自适应算法广泛采用的六个基准数据集。
4.2基线方法
我们比较了我们的TJM方法与五种最先进的(相关的)基线方法的图像识别问题。

特别是TCA是与TJM关系最为密切的方法,而TJM与TCA不同的是,TJM在源数据上引入了
l
2
,
1
l_{2,1}
l2,1范数稀疏惩罚,可以利用联合特征匹配和实例重加权。
选择NN作为基分类器,因为它不需要调优交叉验证参数。
4.3实现细节
对标记好的源数据进行训练,对未标记的目标数据进行测试;对所有数据进行PCA、FSSL、TCA、GFK和TJM降维,然后对标记源数据训练NN分类器,对未标记的目标数据进行分类。
在我们的实验设置下,不可能使用交叉验证来调整最佳参数,因为标记和未标记的数据是从不同的分布中采样的。
因此,我们通过经验搜索参数空间以获得最佳参数设置来评估所有方法,并报告每种方法的最佳结果。
对于子空间学习方法,我们通过搜索
k
∈
[
10
,
20
,
.
.
.
,
200
]
k\in [10, 20, . . . , 200]
k∈[10,20,...,200]来设置#bases.
对于转移学习方法,我们通过搜索
λ
\lambda
λ来设置自适应正则化参数
λ
∈
{
0.01
,
0.1
,
1
,
10
,
100
}
\lambda \in \{0.01, 0.1, 1, 10, 100\}
λ∈{0.01,0.1,1,10,100}.
TJM方法只涉及两个模型参数:#subspace k和正则化参数
λ
\lambda
λ。
当与基线方法比较时,我们使用一组常见的参数设置:
k
=
20
k = 20
k=20和
λ
=
1.0
\lambda= 1.0
λ=1.0。
TJM收敛的迭代次数为T = 10。
我们使用高斯核,带宽设置为训练实例之间的中位数平方距离。我们不重复运行TJM,因为它适合常量初始化
我们用测试数据的分类精度作为评价指标,
A
c
c
u
r
a
c
y
=
∣
x
:
x
∈
D
t
∧
y
^
(
x
)
=
y
(
x
)
∣
∣
x
:
x
∈
D
t
∣
(12)
Accuracy=\frac{|x:x\in D_t\land\hat{y}(x)=y(x)|}{|x:x\in D_t|}\tag{12}
Accuracy=∣x:x∈Dt∣∣x:x∈Dt∧y^(x)=y(x)∣(12)
其中
D
t
D_t
Dt是测试数据集,
y
(
x
)
y(x)
y(x)是x的真值标签
y
^
(
x
)
\hat{y}(x)
y^(x)是分类算法预测的标签。
4.4实验结果
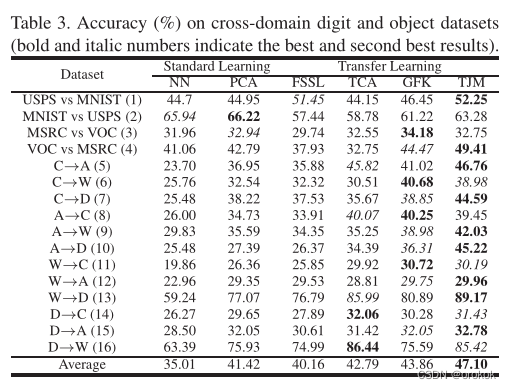
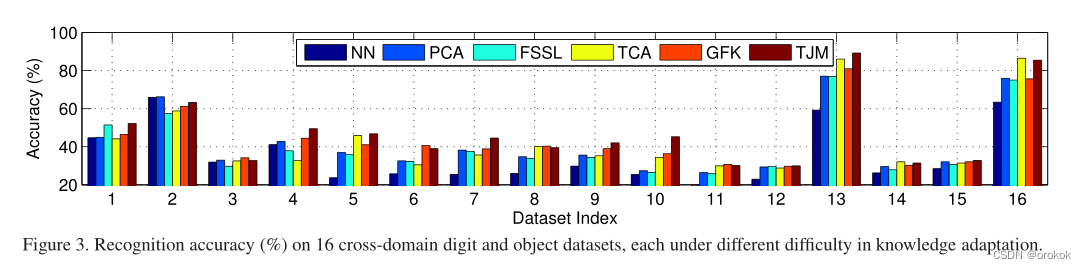
虽然TJM不能在所有数据集上都达到最好的性能,但它仍然是一种有效的、稳健的方法,
这是由于以下几个方面:
- 如果它的性能最好,那么它通常会大大超过最佳基线,例如在数据集 a → D a\rightarrow D a→D上;
- 它只比最佳基线略差。
验证了TJM可以为跨域图像识别问题构建更有效、鲁棒的表示。
FSSL进行联合特征选择和子空间学习,提取共享子空间,自动选择相关特征进行域适应
FSSL和多任务特征学习(Multi-Task Feature Learning, MTFL),只有在相关特征能够自适应选择的情况下才能表现良好。
其中一个成功的案例是数字识别,将图像背景的黑色像素定义为不相关的特征,并自动过滤掉。
另一个成功的案例是文本分类,提取一些语义相关的单词是很自然的。然而,特征选择策略并不能像实例加权那样有效地解决大量的计算机视觉问题。
TCA在可再生核希尔伯特空间(RKHS)中联合进行特征变换和特征匹配,优于PCA。
TJM通过在源实例上引入结构化稀疏惩罚来解决TCA的局限性,该惩罚可以根据源实例与目标实例的相关性自适应地调整源实例的权重。
在GFK中,子空间的维数应该足够小,以保证不同的子空间能够沿测地线流平滑地通过。
然后隐式提取这些无限个子空间,将源数据和目标数据编码为域不变表示。
值得注意的是,GFK在总体上优于TCA,而低于TJM。
这进一步验证了在域差很大的情况下,除了特征匹配外,实例权重的调整对于有效鲁棒的视觉域适应也是非常重要和不可避免的。
4.5有效性分析
通过检验分布距离和实例加权结果,进一步验证了TJM的有效性。
分布的距离:
我们对数据集
A
→
W
A\rightarrow W
A→W进行NN、PCA、TCA和TJM,并设置最佳参数。
然后用公式计算每种方法诱导嵌入的MMD距离
分布距离越小,特征表示的跨域泛化性能越好。
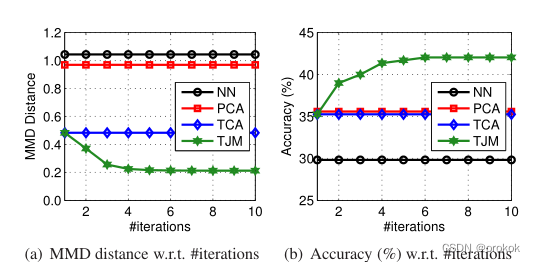
我们可以做这些观察。
- 在不学习特征表示的情况下,NN在原始特征空间中的分布距离最大。
- PCA可以学习到一种新的表示,其中分布距离略有减小,因此只能在一定程度上帮助跨域问题。
- TCA可以明显减小特征分布的差异,从而达到比PCA更好的分类精度。
- TJM可以显式减小特征空间和实例空间的差异,从而提取出分布距离最优最小化的最佳表示。
实例加权:
我们使用数据集
A
→
W
A\rightarrow W
A→W的最佳参数设置进行TCA和TJM。
然后我们根据
l
2
,
1
l_{2,1}
l2,1范数的定义,计算每个实例
x
i
x_i
xi在新特征子空间中的权重为
∥
a
i
∥
\|a^i\|
∥ai∥
注意,在适配矩阵A中,每一行对应一个实例,每一列对应一个子空间维度。
因此,A中每一行的
l
2
l_{2}
l2范数,即
∥
a
i
∥
\|a^i\|
∥ai∥,本质上可以表示每个实例在重构特征表示时的重要性权重。
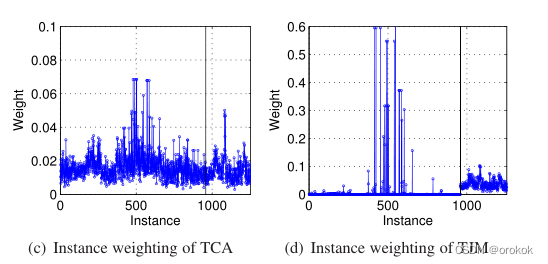
对于跨域问题,一个有效且稳健的表示要求
- 相关源实例应以更大的重要性重新加权
- 不相关的源实例应以较小的重要性重新加权。
从TCA到TJM的显著性能提升证明了,联合匹配特征和重权实例对于,有效鲁棒的视觉域适应是重要且不可避免的。
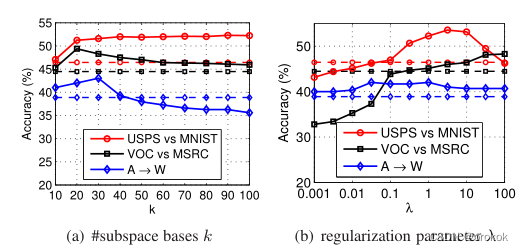
4.6参数敏感性
我们绘制分类精度,在图5(a)中,取
k
∈
[
10
,
50
]
k\in[10,50]
k∈[10,50]。
我们用不同的
λ
\lambda
λ值运行TJM。
直观地看,
λ
→
0
\lambda\rightarrow 0
λ→0时,TJM优化问题退化。
λ
→
∞
\lambda\rightarrow \infin
λ→∞时,不进行联合特征匹配和实例加权。
我们在图5(b)中绘制分类精度
λ
\lambda
λ的不同值,并选择
λ
∈
[
0.1
,
10.0
]
\lambda\in[0.1,10.0]
λ∈[0.1,10.0]。
4.7收敛和时间复杂度
我们用800个特征和1253张图片对数据集
A
→
W
A\rightarrow W
A→W进行了时间复杂度检查,结果如表4所示。
我们看到TJM迭代T次,比TCA更糟糕。

五、总结与未来工作
本文针对视觉域适应问题,提出了一种新的传输联合匹配(TJM)方法。
TJM的目标是在一个有原则的降维过程中,跨域联合匹配特性和重权实例。
TJM的一个重要优点是它对分布差异和无关实例都具有鲁棒性。
在未来,我们计划将联合匹配策略扩展到其他稀疏学习方法,例如稀疏编码。
Reference
Transfer Joint Matching for Unsupervised Domain Adaptation
IEEE Conference on Computer Vision & Pattern Recognition















 827
827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









