







深度学习之卷积神经网络
文章目录
卷积神经网络模型结构图
输入层(Input layer)
卷积层(convolution layer)
池化层(pooling layer)
输出层(全连接层+Softmax layer)

- 为什么要有卷积层?
卷积不需要展开,保留了三维的结构,但是计算的时候其实也是展开计算的
- 全连接层的计算方式?
全连接层是展开计算,y=wx+b
一、卷积层
1、提取特征。压缩提纯。
2、卷积层级之间的神经元是局部连接和权值共享,这样大大减少了(w,b)的数量,加快了训练。
卷积核映射到卷积层的过程:

上图中中间的这一层是卷积核,就是一个w的矩阵。最左边的可以看作是一个输入层,卷积核与其所覆盖的区域的数进行点积,将结果映射到卷积层。
例如上图的例子:
卷积核是 :
-1,-2,-1
0, 0, 0
1, 2, 1
卷积核覆盖的区域的数是:
0, 0, 75
0, 75, 80
0, 75, 80
所以点积(对应位置相乘再相加)后的结果为155
局部连接和权值共享
局部连接:不是全连接
权值共享:如下图,只用了三个权值,这样就大大减少了我们的计算量。

二、池化层
池化层可以理解为对卷积层输出的特征图进一步特征抽样,通常有两种。Max pooling和Average pooling.
如下图:

三、Softmax层
softmax层每一个节点都有一个激活函数,可以理解为每个节点输出的一个概率,所有节点概率和为1。
这样输出的最大概率对应的标签就是这张待分类图所对应的标签。

四、超参
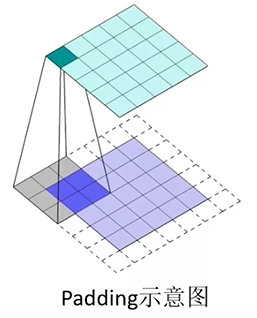
padding:补充边界,在边界补一圈0或1.
1、为了保持边界信息,倘若不填充,边界信息被卷积核扫描的次数远比不上中间信息的扫描次数,这样就降低了边界信息的参考价值了。
2、输入图片的尺寸可能参差不齐,通过padding来使图片的尺寸一致。
Stride 步幅
定义:卷积核每次移动的大小,默认为1。步幅越大,相对越粗糙。















 86
86











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









