






本文主要包括了以下 4 篇文章:
- 【SR-GNN | AAAI 2019】:Session-Based Recommendation with Graph Neural Networks:基于图神经网络的会话推荐
- 【GC-SAN | IJCAI 2019】:Graph Contextualized Self-Attention Network for Session-based Recommendation:基于图上下文自我注意力网络的会话推荐
- 【CA-TAN | ICDM 2020】:Cross-Session Aware Temporal Convolutional Network for Session-based Recommendation:基于跨会话感知时序卷积网络的会话推荐
- 【GCE-GNN | SIGIR 2020】:Global Context Enhanced Graph Neural Networks for Session-based Recommendation:基于全局上下文增强图神经网络的会话推荐
1 SR-GNN
这篇文章首先提出了将会话信息映射为图结构,并通过GNN来获得物品之间的转移信息。
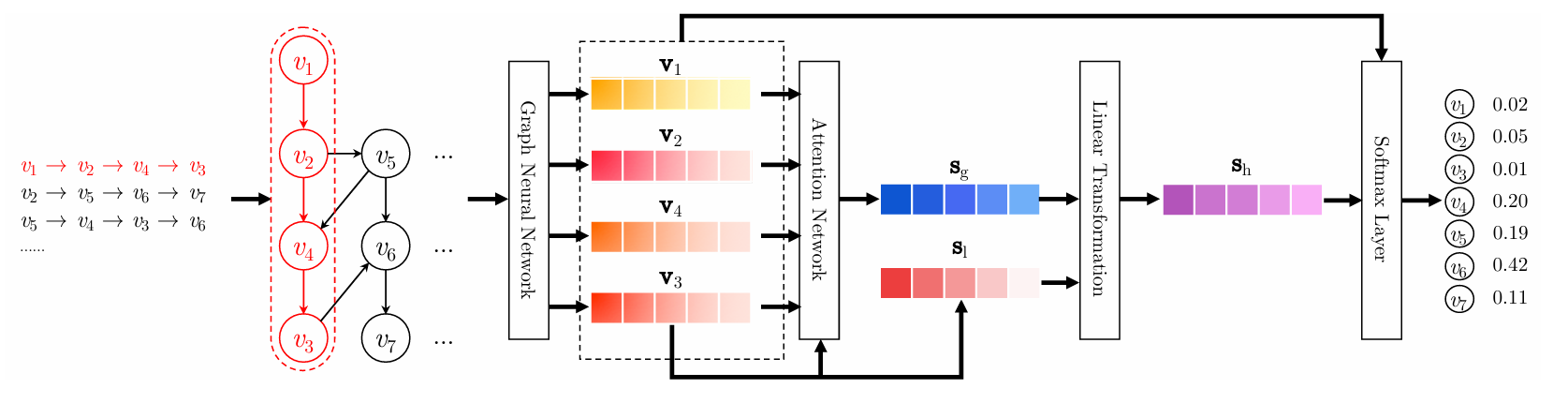
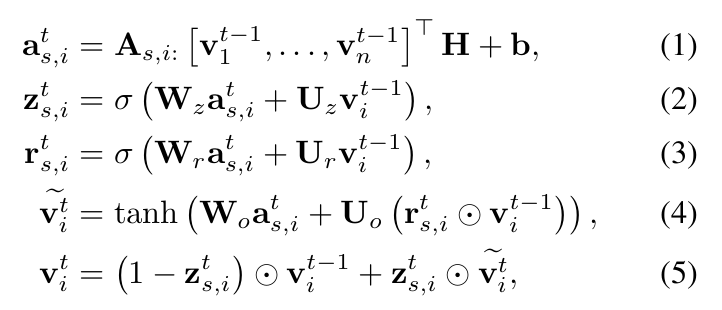
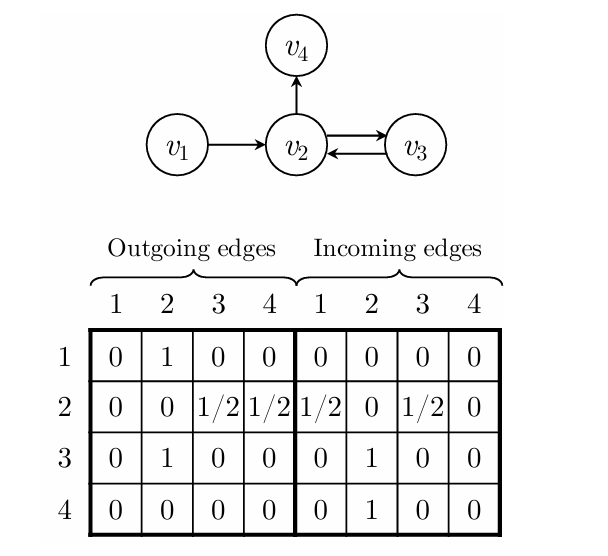
第一个等式表示从邻居节点汇聚信息, 由两个邻接矩阵
和
拼接而成,
表示节点
在
中相应的两列。后面就是GRU的过程。
在获得物品表示后,分别计算会话的局部表示(local)和全局表示(global),分别表示用户的当前兴趣和长期兴趣。
其中局部表示为:为会话的最后一个物品)
而全局表示需要计算权重,论文使用了软注意力(soft-attention mechanism):
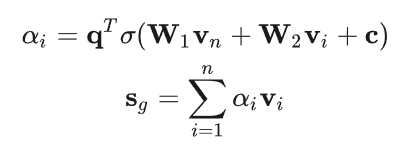
最后拼接做线性变换:
SR-GNN并没有考虑跨会话信息,因为它只针对单会话建图。
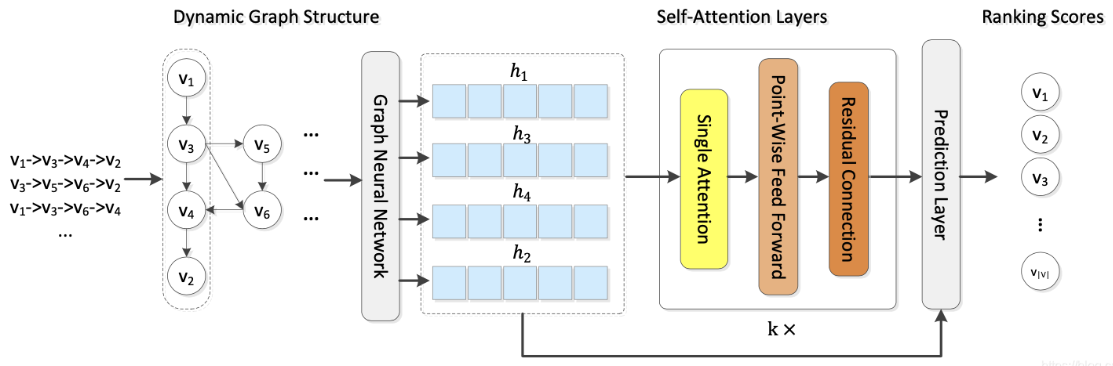
2 GC-SAN
GC-SAN和SR-GNN比较相似,也是构建了两个邻接矩阵 :
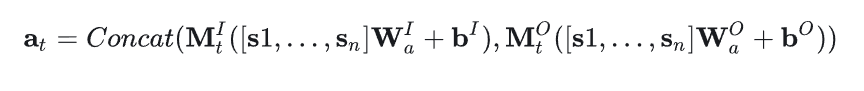
其中是节点 st 在两个邻接矩阵中对应第 t 行。

基本和SR-GNN一样,SR-GNN邻接矩阵拼接起来计算,GC-SAN分开计算,最后再拼接。后面就都是套GRU了。
接下来的工作其实就是对一个会话经过多层的自我注意力层,以获得用户的长期兴趣,最后通过门控机制将长期兴趣和短期兴趣(会话最后一个物品的表示)结合起来以获得会话最后的表示。
这部分也没啥创新的地方,就是一个self-attention的使用。
3 CA-TCN
CA-TCN是美团发表于ICDM workshop 2020的一篇论文,关于该模型,美团技术团队已经做了详尽的介绍:
美团技术团队:ICDM论文:探索跨会话信息感知的推荐模型17 赞同 · 15 评论文章编辑
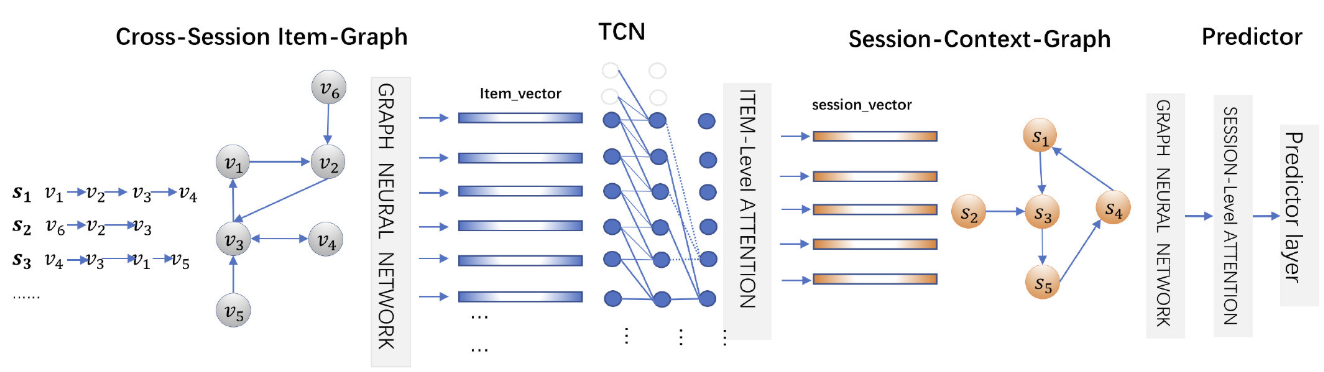 CA-TCN构建的跨会话图结构是有向图,根据物品之间的共现频率来设置边权重,得到
CA-TCN构建的跨会话图结构是有向图,根据物品之间的共现频率来设置边权重,得到 和
两个权重矩阵。
经过GNN,得到物品的全局表示,其传播聚合的过程为:
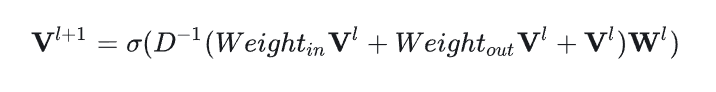
得到物品表示后,进而计算会话表示,分为局部表示和全局表示,局部表示为时序卷积网络中最后一个物品的输出,全局表示通过会话中所有的物品表示加权求和得到,也是软注意力。
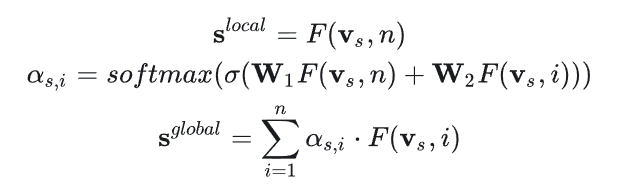
模型中还有Session-Context-Graph,这是为了考虑其他会话信息,方法就是注意力机制:
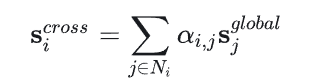
最后通过门控机制结合起来:
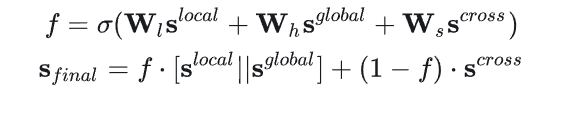
4 GCE-GNN
和上面不同的是,这篇文章分别构建了会话图(Session Graph)和全局图(Global Graph)。
- 会话图针对单个会话建图,其为有向图,将会话中相邻的节点相连,并且添加自连接。所以存在四种边关系,
。
- 全局图针对所有会话见图,其为带权无向图,将会话中相邻距离在 ε 之内的节点相连,其权重根据节点在所有会话共现的频率决定。最后对于每个节点来说,只保留其权重最大的Top-N条边(一方面可以降低计算复杂度,另一方面应该也可以去除噪声)。
- 总结一下,前者只提取一阶节点信息,而后者提取 ε 阶节点信息。
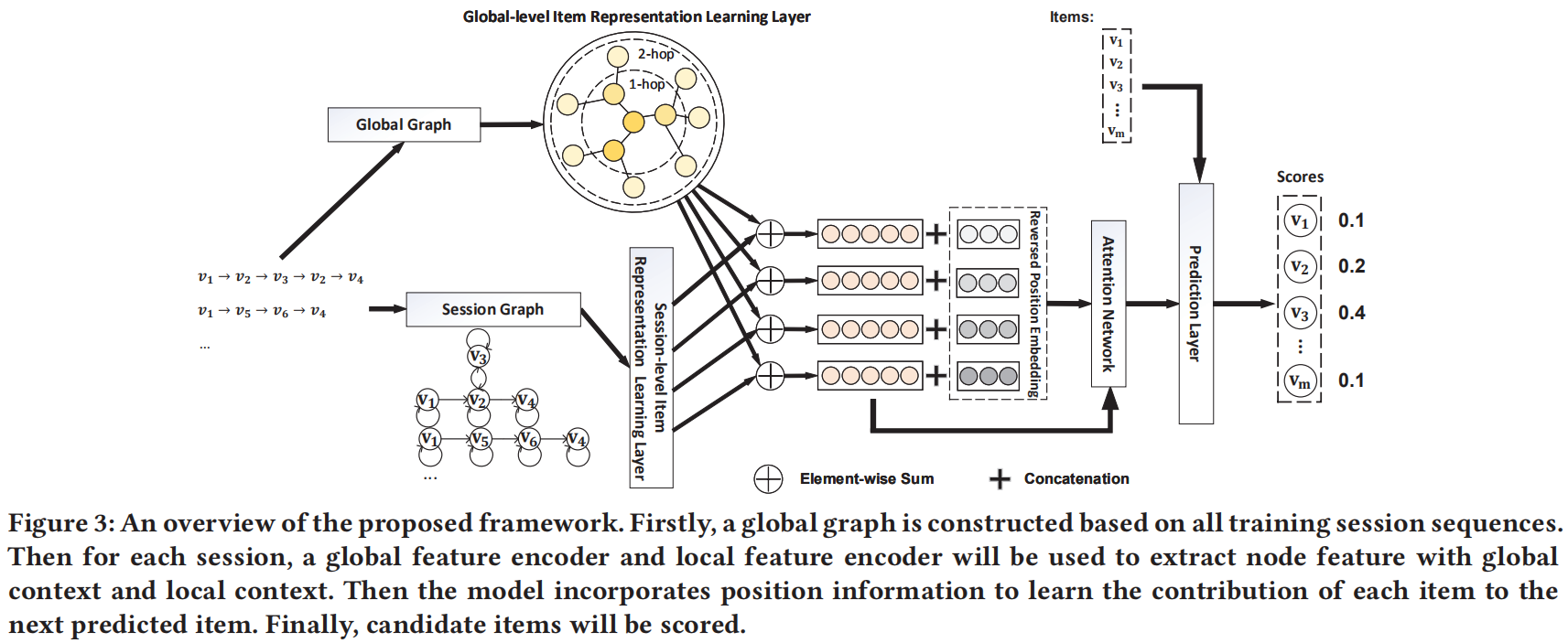 全局级物品表示学习层
全局级物品表示学习层
获得物品 v 的一阶邻居表示,最简单的方法就是加和平均,但是和物品v相关的物品不一定和当前会话相关,所以使用注意力来加权求和。 hNvig 是邻居节点的表示。
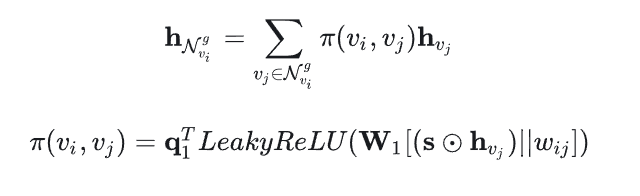
其中 s 就是序列中节点的平均池化 ,上述得到的结果得需要再经过一个
进行归一化。
我觉得这个考虑点还是挺有道理的,比如说现在用户的点击序列都是华为的产品,其中包括了笔记本电脑,那在其他会话中出现的笔记本比如苹果、联想等等,尽管它们都是笔记本很相似,但对于当前的会话来说,用户可能想要的是华为的产品。
然后在计算的时候,既考虑到了会话 s 和物品 vj 之间的相似度,还包括了 vi 和 vj 之间的边权重 wij ,如果该值大的话,说明这两个物品经常同时出现,既然共现的概率很大,那也可以不讲道理推荐一波。
接下来就是简单的聚合过程了:
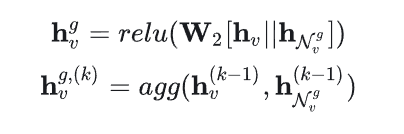
4.2 会话级物品表示学习层
毫无疑问,这里也是要使用注意力的,由于在会话图中存在四种不同的边,所以在计算的时候需要考虑进去:
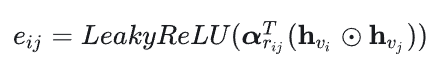
表示边的类别,所以 α 就是四种边的权重参数。
表示的是
对
的重要性。
为了系数具有可比性,需经过一个
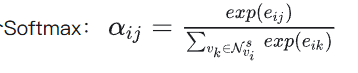
最后得到物品的会话级表示:
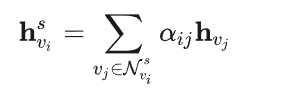
4.3 会话表示学习层
经过前面两层的学习,使用dropout防止过拟合,然后将全局级物品表示和会话级物品表示相加。
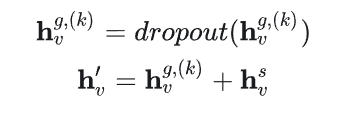
上面的文章中在计算会话表示时没有考虑位置信息,而这篇文章则加入了反向位置信息,越靠近末尾的物品应该越重要。
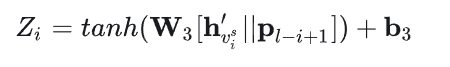
为什么采用反向位置信息呢?因为会话的长度是不固定的,前向位置信息无法衡量当前物品和预测物品之间的距离,但反向位置信息可以。
通过平均池化来得到会话信息:
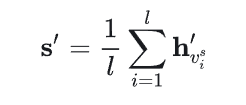
最后软注意力机制计算权重:
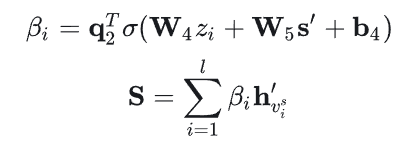
会话表示总体上和之前的文章差不多,之前的做法是取会话的最后一个物品输出来作为会话信息,但这篇文章是平均池化,考虑了所有物品。另外就是注意力机制的时候加入了位置信息。
预测层
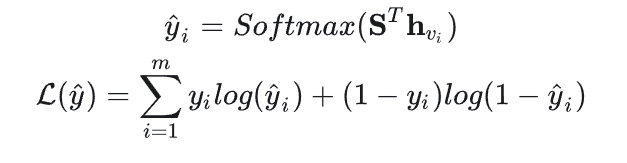
总结
这几篇文章看下来,感觉值得借鉴的地方有:
- 其中3篇文章都使用到了软注意力机制,来获取会话的全局表示。
- 在GCE-GNN文章中考虑了位置信息,并加入了反向位置信息。
- 在图结构中,为不同的边考虑不同的权重参数。
- 在GCE-GNN文章中使用注意力机制来从全局图中提取适合当前会话的信息。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









