






1. 导读
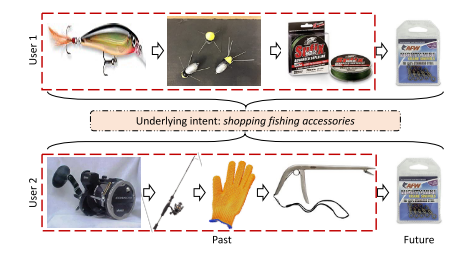
用户与物品的互动是由各种意图驱动的(例如,准备节日礼物、购买捕鱼设备等)。然而,用户的潜在意图往往是不被观察到/潜在的,因此很难利用这些潜在意图进行序列推荐(SR)。本文提出了意图对比学习(ICL),通过聚类将潜在意图变量引入SR。其核心思想是从未标记的用户行为序列中学习用户的意图分布函数,并通过考虑学习的意图来优化SR模型,从而改进推荐模型。
本文主要是针对用户的兴趣表征进行聚类,然后以簇中心代表用户意图,根据用户意图和用户兴趣表征构建损失函数,并且结合原有的序列损失函数和对比学习损失函数构建多任务损失函数。
2. 基础
2.1 问题定义
用户集合U,商品集合V,每个用户有一个交互序列
,
表示在时间步t时,用户u交互的商品。令
表示序列的embedding,即对序列中的每个商品进行编码,得到对应的embedding的集合。在实践中,固定长度T,序列长了就裁剪,短了就补全。模型目标是预测第|
|+1个交互的商品。
2.2 序列模型
深度序列推荐模型,通常是将交互序列embedding集合进行编码,发掘用户的兴趣表征
,H中的每个元素表达用户在位置t时的兴趣。序列模型建模时,通常是对一个序列中,每次前t个构成的子序列来预测第t+1个商品,因此可以建模如下,其中负样本
为随机采样得到。
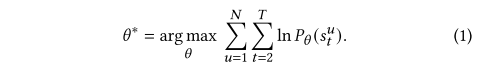
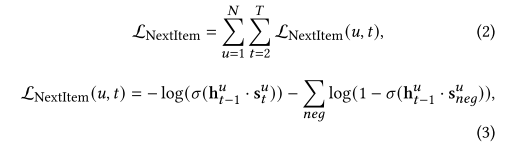
2.3 推荐中的对比自监督学习
本文利用的对比学习自监督相关方法是,按照互信息最大化(MIM)原则,融合一个序列不同视图之间的相关性。给定一个序列和预先定义的函数集合G,构建两个正样本的视角(positive view),公式如下,其中g是从G中采样得到的转换函数(转换方式包括对序列加掩码,裁剪和重排序等),通常,从同一序列创建的视图被视为正对,任何不同序列的视图都被视为负对。
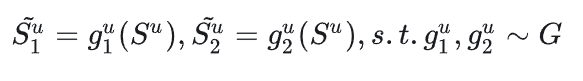
构建的新序列,经过编码器得到对应的序列兴趣表征集合,
,将其聚合后得到兴趣向量表示当前整个序列的表征\,文中采用的聚合方式是拼接。然后根据infoNCE来构建损失函数,sim()表示内积,hneg表示负视角构建的兴趣表征。
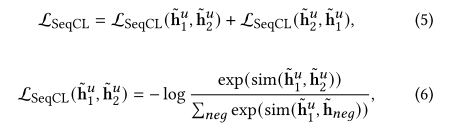
3. 方法
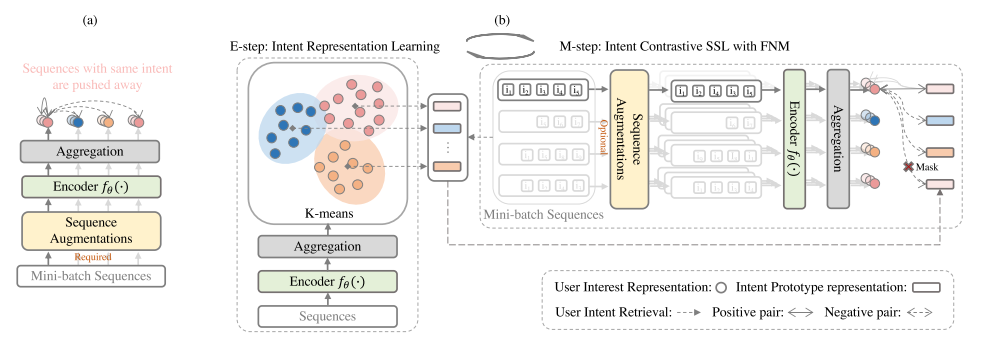
上图为总体框架图。通过EM算法交替执行E步和M步来估计意图变量c的分布函数 并对模型参数进行了优化 . 在E-step中,它通过聚类估计 ( ) 。在M-step中,它通过梯度下降进行优化 。
- E步,进行聚类,得到不同簇反映的用户意图
- M步,根据用户意图和兴趣表征,进行损失函数的计算以及参数更新。
3.1 ICL
3.1.1 建模潜在意图
假设用户存在K个意图{ci}i=1K,则优化目标可以改写为下式,通常的RS是不考虑用户意图,直接通过交互序列embeddingstu进行第t+1的预测,具体公式可以看2.2,而ICL中,考虑用户意图,计算每个意图与第t次交互embedding的关系,然后将所有关系求期望后,在根据常用的流程往下计算损失。
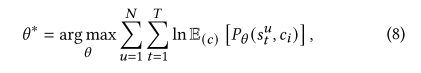
上述公式求解很复杂,因此根据EM算法,构造上式的下界,通过最大化下界来最大化上式,假设意图c满足分布Q(c),∑cQ(ci)=1,并且Q(c)≥0,可以得到下式,等式右边第一个是求期望,第二个是乘上Q()/Q(),值不变。
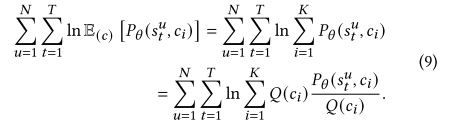
根据jensen不等式,可得下式,
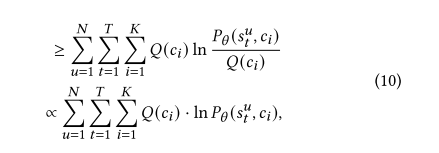
前面我们提到序列推荐中,每次都用前t个子序列来预测第t+1时的商品,为了简化ICL损失函数的计算,只考虑最后一步的下界,则可以去掉上式的中间的求和,公式如下,
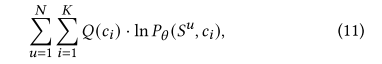
3.1.2 意图表征学习
为了学习意图分布Q(c),将所有序列{Su}u=1|U|通过编码器编码得到表征{hu}u=1|U|,然后在这些表征上做kmeans聚类,从而得到上式中得Pθ(ci|Su),如下式,
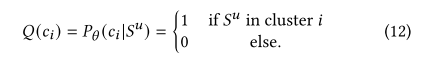
我们将ci表示为意图ci的向量表征 , 他们是簇的中心,使用平均池化,即求簇中表征的均值来得到。
3.1.3 意图对比学习
在得到Q(c)之后,想要最大化下界还需要知道Pθ(Su,ci)。假设意图的先验满足均匀分布,并且给定意图c时Su的条件分布和L2标准化的高斯分布同向,则可以该写成下式,其中hu为Su的表征。
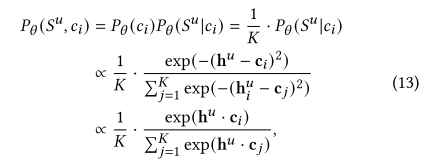
则最终最大化的公式可以改写为最小化下式,其中sim()为内积,该公式最大化序列和意图之间的互信息。
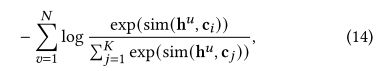
对每一个batch中的训练序列{Su}u=1N,构建两个正视角的序列分别得到两个表征h~1u和h~2u,然后构建以下损失函数,其中cneg表示给定batch中的所有意图。
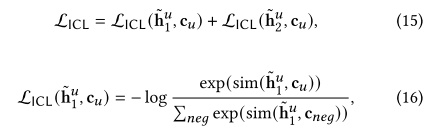
但是直接优化上式存在一个问题,就是不同的用户可能存在相同的意图,如果直接优化,可能会把相同意图的也作为负样本,即假阴性。最终修改损失函数如下,其中F表示具有相同意图的用户集合。把这个叫做FNM,缓解假阴性。
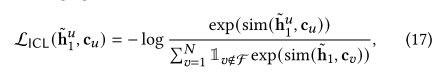
3.2 多任务
![]()
如上式所示,最终将原始的序列损失函数,加入用户意图的ICL损失函数和序列级别的自监督损失函数来构成多任务损失函数。
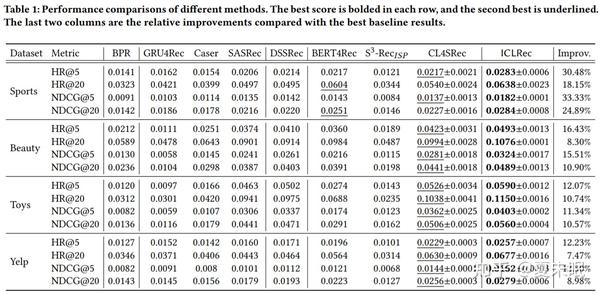
4. 结果

















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









