






Spark(二)
一、Spark 核心编程
Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
- ➢ RDD : 弹性分布式数据集
- ➢ 累加器:分布式共享只写变量
- ➢ 广播变量:分布式共享只读变量
1、 RDD
1.1、什么是 RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合
➢ 弹性
- 存储的弹性:内存与磁盘的自动切换;
- 容错的弹性:数据丢失可以自动恢复;
- 计算的弹性:计算出错重试机制;
- 分片的弹性:可根据需要重新分片。
➢ 分布式:数据存储在大数据集群不同节点上
➢ 数据集:RDD 封装了计算逻辑,并不保存数据
➢ 数据抽象:RDD 是一个抽象类,需要子类具体实现
➢ 不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
➢ 可分区、并行计算
1.2、核心属性

➢ 分区列表
RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。

➢ 分区计算函数
Spark 在计算时,是使用分区函数对每一个分区进行计算

➢ RDD 之间的依赖关系
RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系

➢ 分区器(可选)
当数据为 KV 类型数据时,可以通过设定分区器自定义数据的分区
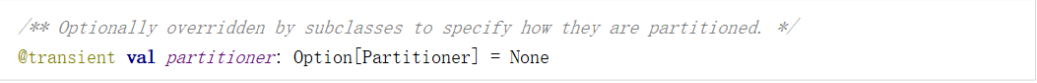
➢ 首选位置(可选)
计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算

1.3、执行原理
从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合。
Spark 框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果
RDD 是 Spark 框架中用于数据处理的核心模型
- 启动 Yarn 集群环境

2) Spark 通过申请资源创建调度节点和计算节点

3) Spark 框架根据需求将计算逻辑根据分区划分成不同的任务

4) 调度节点将任务根据计算节点状态发送到对应的计算节点进行计算

从以上流程可以看出 RDD 在整个流程中主要用于将逻辑进行封装,并生成 Task 发送给Executor 节点执行计算,接下来我们就一起看看 Spark 框架中 RDD 是具体是如何进行数据处理的
1.4、基础编程
~1、 RDD 创建
在 Spark 中创建 RDD 的创建方式可以分为四种:
1) 从集合(内存)中创建 RDD
从集合中创建 RDD,Spark 主要提供了两个方法:parallelize 和 makeRDD
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark_RDD_Memory {
def main(args: Array[String]): Unit = {
//TODO 准备环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc: SparkContext =new SparkContext(sparkConf)
//TODO 创建RDD
//从内存中创建RDD,将内存中集合的数据作为梳理的数据源
val seq: Seq[Int] =Seq[Int](1,2,3,4)
//val rdd:RDD[Int] = sc.parallelize(seq)
//parallelize:并行
//或用
val rdd:RDD[Int] = sc.makeRDD(seq)
//makeRDD方法在底层实现时其实就是调用了rdd对象的parallelize方法
rdd.collect().foreach(println)
//TODO 关闭环境
sc.stop()
}
}
从底层代码实现来讲,makeRDD 方法其实就是 parallelize 方法
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
2) 从外部存储(文件)创建 RDD
由外部存储系统的数据集创建 RDD 包括:本地的文件系统,所有 Hadoop 支持的数据集,比如 HDFS、HBase 等
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark_RDD_File {
def main(args: Array[String]): Unit = {
//TODO 准备环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc: SparkContext =new SparkContext(sparkConf)
//TODO 创建RDD
//从文件中创建RDD,将文件的数据作为处理的数据源
//path路径默认以当前的根路径为基准。可以写绝对路径,也可以写相对路径
//path路径可以是文件的具体路径,也可以时目录名称
sc.textFile("datas/1.txt")
//sc.textFile("datas") //目录中的路径都会读取
//path路径还可以时通配符
sc.textFile("datas/1*.txt")
//path还可以是分布式存储系统:HDFS
sc.textFile("hdfs://hadoop102:9000/test.txt")
//wholeTextFile:以文件为单位读取数据
//读取的结果表示为元组,第一个元素表示文件路径,第二个元素表示文件内容
val rdd: RDD[(String, String)] =sc.wholeTextFiles("datas");
rdd.collect().foreach(println)
sc.stop()
}
}
3) 从其他 RDD 创建
主要是通过一个 RDD 运算完后,再产生新的 RDD。详情请参考后续章节
4) 直接创建 RDD(new)
使用 new 的方式直接构造 RDD,一般由 Spark 框架自身使用。
~2、RDD 并行度与分区
默认情况下,Spark 可以将一个作业切分多个任务后,发送给 Executor 节点并行计算,而能 够并行计算的任务数量我们称之为并行度。这个数量可以在构建 RDD 时指定
集合数据源分区
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark_RDD_Memory_Par {
def main(args: Array[String]): Unit = {
//TODO 准备环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
//sparkConf.set("spark default.parallelism", "5")
val sc: SparkContext =new SparkContext(sparkConf)
//TODO 创建RDD
//rdd的并行度&分区
//makeRDD方法可以传递第二个参数,这个参数表示分区的数量
//第二个参数可以不传递,那么makeRDD方法会使用默认值:defaultParallelism
//如果获取不到,那么使用totalCores属性,这个属性取值为当前运行环境的最大可用核数
val rdd = sc.makeRDD(List(1, 2, 3, 4),2)
//将处理的数据保存成分区文件
rdd.saveAsTextFile("output")
rdd.collect().foreach(println)
//TODO 关闭环境
sc.stop()
}
}
文件数据源分区
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark_RDD_File_Par {
def main(args: Array[String]): Unit = {
//TODO 准备环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc: SparkContext =new SparkContext(sparkConf)
//TODO 创建RDD
//textFile可以将文件作为数据处理的数据源,默认也可以设定分区
sc.textFile("datas/1.txt")
//如果不想使用默认分区数量,可以通过第二个参数指定分区数
//Spark读取文件,底层其实使用的就是hadoop的读取方式
//minPartitions:最小分区数量
//math.min(defaultParallelism,2)
//数据为1,2,3
val rdd: RDD[String] = sc.textFile("datas/1.txt",2)
//分区的数量与文件的字节数有关
rdd.saveAsTextFile("output")
//分区
//7byte /2 =3byte
//7 / 3=2..1
//1/3>0.1
//分区为7/3+1=3
//1.数据以行为单位进行读取
// spark读取文件,采用的是hadoop的方式读取,所以一行一行读取,和字节数无关
//2.数据读取时以偏移量为单位,偏移量不会被重复读取
//3.数据分区的偏移量范围的计算
//0=>[0,3]=>1,2
//1=>[3,3]=>3
//2=>[6,7]=>
rdd.collect().foreach(println)
sc.stop()
}
}
~3、RDD转换算子
RDD 根据数据处理方式的不同将算子整体上分为 Value 类型、双 Value 类型和 Key-Value类型
~3.1、map
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Operate")
val sc: SparkContext =new SparkContext(sparkConf)
val rdd: RDD[Int] =sc.makeRDD(List(1,2,3,4))
//1,2,3,4
//2,4,6,8
//转换函数
val mapRDD: RDD[Int] = rdd.map(num=>num*2)
mapRDD.collect()
mapRDD.foreach(println)
sc.stop()
}
}
//1、rdd的计算一个分区的数据是一个一个执行逻辑
// 只有前面一个数据全部的逻辑执行完毕后,才会执行下一个数据
// 分区内的数据执行是有序的
//2、不同分区内数据的执行是无序的
~3.2、mapPartitions
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark02_RDD_Operate_Transform {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Operate")
val sc: SparkContext =new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
//mapPartitions:可以以分区为单位进行数据的转换操作
//但是会将整个分区的数据加载到内存中进行引用
// 处理完的数据是不会被释放掉,存在对象的应用
// 在内存较小,数据量较大的场合下,容易出现内存溢出
val mapRDD = rdd.mapPartitions(
iter => {
println(">>>>>>>>>>>>>>>>")
iter.map(_ * 2)
})
mapRDD.collect()
mapRDD.foreach(println)
sc.stop()
}
}
map 和 mapPartitions 的区别?
➢ 数据处理角度
Map 算子是分区内一个数据一个数据的执行,类似于串行操作。而 mapPartitions 算子是以分区为单位进行批处理操作
➢ 功能的角度
Map 算子主要目的将数据源中的数据进行转换和改变。但是不会减少或增多数据。MapPartitions 算子需要传递一个迭代器,返回一个迭代器,没有要求的元素的个数保持不变,所以可以增加或减少数据
➢ 性能的角度
Map 算子因为类似于串行操作,所以性能比较低,而是 mapPartitions 算子类似于批处理,所以性能较高。但是 mapPartitions 算子会长时间占用内存,那么这样会导致内存可能不够用,出现内存溢出的错误。所以在内存有限的情况下,不推荐使用。使用 map 操作
~3.3、mapPartitionsWithIndex
函数说明 将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处 理,哪怕是过滤数据,在处理时同时可以获取当前分区索引
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark03_RDD_Operate_Transform {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Operate")
val sc: SparkContext =new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
val mapRDD: RDD[(Int, Int)] = rdd.mapPartitionsWithIndex(
(index, iter) => {
iter.map(num=>(index,num))
}
)
mapRDD.foreach(println)
sc.stop()
}
}
~3.4、flatMap
将处理的数据进行扁平化后再进行映射处理,所以算子也称之为扁平映射
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object FlatMapTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("flatMap")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(List(1, 2, 3), 4, List(5, 6)))
val flatRDD = rdd.flatMap(
data => {
data match {
case list: List[_] => list
case dat => List(dat)
}
}
)
flatRDD.collect().foreach(println)
sc.stop()
}
}
~3.5、glom
将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("flatMap")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1,2,3,4,5),2)
val glomRDD = rdd.glom()
glomRDD.collect().foreach(data=>println(data.mkString(",")))
}
~3.6、groupBy
将数据根据指定的规则进行分组, 分区默认不变,但是数据会被打乱重新组合,我们将这样 的操作称之为 shuffle。极限情况下,数据可能被分在同一个分区中
~3.7、filter
将数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃。 当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出 现数据倾斜
import org.apache.spark.{SparkConf, SparkContext}
object FilterTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operate")
val sc = new SparkContext(sparkConf)
val rdd = sc.textFile("datas/apache.log")
rdd.filter(line=>{
val datas=line.split(" ")
val time=datas(3)
time.startsWith("17/05/2015")
}).collect().foreach(println)
sc.stop()
}
}
~3.8、sample
根据指定的规则从数据集中抽取数据
import org.apache.spark.{SparkConf, SparkContext}
object SampleTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operate")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9,10))
//sample算子需要传递三个参数
//1、第一个参数表示,抽取数据后是否将数据返回true(返回),false(丢弃)
//2、第二个参数表示,
// 如果抽取不放回的场合:数据源中每条数据被抽取的概率
// 如果抽取放回的场合:表示数据源中的每条数据被抽取的可能次数
//3、第三个参数表示,抽取数据时随机算法的种子
// 如果不传入第三个参数,那么使用的是当前系统时间
// println(rdd.sample(false,0.4,1).collect().mkString(","))
//
println(rdd.sample(true,3,1).collect().mkString(","))
}
}
~3.9、distinct
将数据集中重复的数据去重
import org.apache.spark.{SparkConf, SparkContext}
object DistinctTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1, 2, 3, 4, 1, 2, 3))
val rdd1 = rdd.distinct()
rdd1.collect().foreach(println)
}
}
~3.10、coalesce
根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率 当 spark 程序中,存在过多的小任务的时候,可以通过 coalesce 方法,收缩合并分区,减少 分区的个数,减小任务调度成本
import org.apache.spark.{SparkConf, SparkContext}
object CoalesceTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(conf)
val rdd=sc.makeRDD(List(1,2,3,4),4)
//默认情况下,不会将数据打乱组合,可能导致数据不均衡
//val newRDD=rdd.coalesce()
//如果想要让数据均衡,可以进行shuffle处理
val newRDD=rdd.coalesce(2,true)
}
}















 80
80











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









