







Spark Core
二、Spark Core
2.1 Spark core与MapReduce
MapReduce能够完成的各种离线批处理功能,以及常见算法(比如二次排序、topn等),基于Spark RDD的核心编程,都可以实现,并且可以更好地、更容易地实现。而且基于Spark RDD编写的离线批处理程序,运行速度是MapReduce的数倍,速度上有非常明显的优势。
Spark相较于MapReduce速度快的最主要原因就在于,MapReduce的计算模型必须是map-reduce模式,有时候即使完成一些诸如过滤之类的操作,也必须经过map-reduce过程,这样就必须经过shuffle过程。而MapReduce的shuffle过程是最消耗性能的,因为shuffle中间的过程必须基于磁盘来读写。而Spark的shuffle虽然也要基于磁盘,但是其大量transformation操作,比如单纯的map或者filter等操作,可以直接基于内存进行pipeline操作,速度性能自然大大提升。
但是Spark也有其劣势。由于Spark基于内存进行计算,虽然开发容易,但是真正面对大数据的时候(比如一次操作针对10亿以上级别),在没有进行调优的情况下,可能会出现各种各样的问题,比如ROOM内存溢出等等。导致Spark程序可能都无法完全运行起来,就报错挂掉了,而MapReduce即使是运行缓慢,但是至少可以慢慢运行完。
2.2 RDD的定义
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。其中:
Resilient:存储的弹性,内存与磁盘的自动切换;容错的弹性,数据丢失可以自动恢复;计算的弹性,计算出错重试机制;分片的弹性,可根据需要重新分片。
Distributed:它里面的元素是分布式存储的,可以用于分布式计算。
Dataset:它是一个集合,可以存放很多元素,并且RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创 建新的RDD。
2.3 RDD的作用
在许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘中,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,之前的 MapReduce 框架采用非循环式的数据流模型,把中间结果写入到 HDFS 中,带来了大量的数据复制、磁盘 IO 和序列化开销。且这些框架只能支持一些特定的计算模式(map/reduce),并没有提供一种通用的数据抽象。
RDD 提供了一个抽象的数据模型,让我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换操作(函数),不同 RDD 之间的转换操作之间还可以形成依赖关系,进而实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘 IO 和序列化开销,并且还提供了更多的 API(map/reduce/filter/groupBy)。
RDD典型的执行过程如下,该处理称为一个Lineage(血缘关系),即DAG拓扑排序的结果:
(1)RDD读入外部数据源进行创建;
(2)RDD经过一系列的转换(Transformation)操作,每一次都会产生不同的RDD,供给下一个转换(Transformation)操作使用;
(3)最后一个RDD经过动作(Action)操作进行转换,并输出到外部数据源。
使用RDD的优点:惰性调用、管道化、避免同步等待、不需要保存中间结果、操作简单。
Spark采用RDD以后能够实现高效计算的原因主要在于:
(1)高容错性:血缘关系、重新计算丢失分区、无需回滚系统、重算过程在不同节点之间并行、只记录粗粒度的操作;
(2)中间结果持久化到内存:数据在内存中的多个RDD操作之间进行传递,避免了不必要的读写磁盘开销;
(3)存放的数据是Java对象:避免了不必要的对象序列化和反序列化。
2.4 RDD依赖关系
Spark通过分析各个RDD的依赖关系生成了DAG,并根据RDD依赖关系把一个job分成多个stage。stage划分的依据是窄依赖和宽依赖,窄依赖可以实现流水线优化,宽依赖包含Shuffle过程,无法实现流水线方式处理。
窄依赖表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区;宽依赖则表现为存在一个父RDD的一个分区对应一个子RDD的多个分区,如图2.1所示。
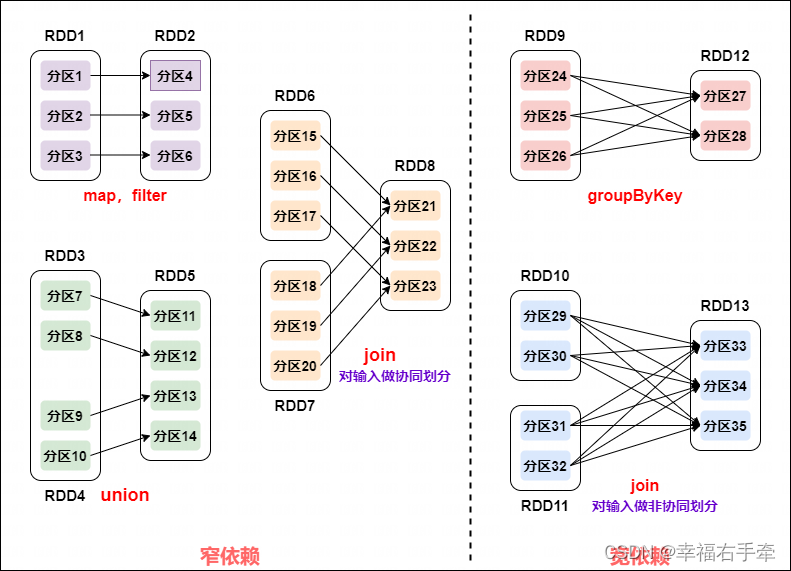
图2.1 窄依赖和宽依赖在RDD分区中的对应关系
逻辑上每个RDD 操作都是一个fork/join(一种用于并行执行任务的框架),把计算fork 到每个RDD 分区,完成计算后对各个分区得到的结果进行join操作,然后fork/join下一个RDD操作。
RDD Stage划分:Spark通过分析各个RDD的依赖关系生成DAG,再通过分析各个RDD中的分区之间的依赖关系来决定如何划分Stage,如图2.2所示,具体方法:
(1)在DAG中进行反向解析,遇到宽依赖就断开;
(2)遇到窄依赖就把当前的RDD加入到Stage中;
(3)将窄依赖尽量划分在同一个Stage中,可以实现流水线计算。
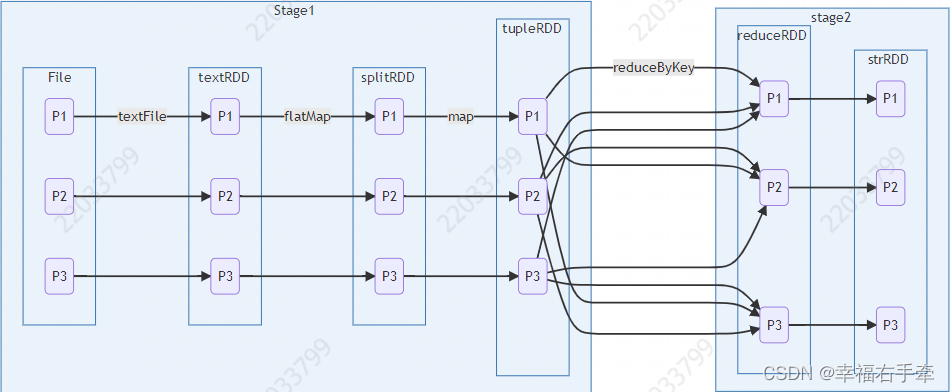
图2.2 宽窄依赖与stage划分
2.5 RDD的运行过程
RDD在Spark架构中的运行过程:
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAG Scheduler负责把DAG图分解成多个Stage,每个Stage是一个TaskSet,其中包含了多个Task,分发给TaskScheduler;
(4)每个Task会被TaskScheduler分发给各个WorkerNode上的Executor去执行。
2.6 RDD的创建
RDD的创建是依赖于SparkContext的,可以从从文件系统中加载数据创建,或者通过并行集合(数组)创建RDD。Spark采用textFile()方法来从文件系统中加载数据创建RDD,该方法把文件的URI作为参数,这个URI可以是本地文件系统的地址,或者是分布式文件系统HDFS的地址。
(1)从本地文件系统中加载数据:
% sc = SparkContext('local', 'log'),在shell中sc可直接用,不用配置
val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
(2)从HDFS中加载据:
val lines = sc.textFile("hdfs://localhost:9000/user/hadoop/word.txt")
(3)可以调用SparkContext的parallelize方法,在Driver中一个已经存在的集合(数组)上创建。
val array = Array(1,2,3,4,5)
val rdd = sc.parallelize(array)
(4)或者从列表中创建:
val list = List(1,2,3,4,5)
val rdd = sc.parallelize(list)
2.7 RDD的操作(Transformation与Action)
RDD可以被看作Spark的一个对象,它本身运行于内存中,如读文件是一个RDD,计算文件是一个RDD,结果集也是一个RDD,不同的分片,数据之间的依赖,key-value类型的map数据都可以被看作RDD。
**Spark针对RDD的操作包括RDD的转化操作(创建RDD)和行动操作,也就是说RDD的操作分为“转换(Transformation)和行动(Action)”两种操作类型,这也是两个操作阶段。**这两类操作的主要区别是:Transformation操作接收RDD并返回RDD,Action操作接收RDD,但返回非RDD(输出一个值或者一个结果)。RDD操作是一种‘惰性操作’,延迟执行,在转换操作阶段没有实施真正的计算,在行动阶段才将转换操作真正实施,这样可以在 Action 时对 RDD 操作形成 DAG 有向无环图,从而进行 Stage 的划分和并行优化,这种设计让 Spark 更加有效率地运行。
对于RDD而言,每一次转换操作都会产生不同的RDD,以供给下一个转换使用。转换得到的RDD是“惰性”求值的,也就是说,整个转换过程只记录了转换的轨迹,并不发生真正的计算,只有遇到行动操作时才会发生真正的计算。常用的Transformation操作如表2.1所示。
表2.1 常用的Transformation操作
| 转换函数 | 含义 |
|---|---|
| map(func) | 返回一个新的RDD,该RDD由每个输入元素经过func函数转换后组成 |
| filter(func) | 返回一个新的RDD,该RDD经由func函数计算后返回值为true的输入元素组成 |
| flatMap(func) | 类似于map(func),但是每个输入元素可以被映射为0或多个输出元素(所以func函数应该返回一个序列,而不是单个元素) |
| groupByKey() | 在一个(K,V)的RDD上调用,返回一个(K,Iterator[V])的RDD |
| reduceByKey(func,[numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将key相同的值聚合在一起,与groupByKey()类似,reduce任务的个数可以通过第二个可选参数来设置 |
| sortByKey([ascending],[numTasks]) | 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key值进行排序的(K,V)的RDD |
| mapValues(func) | 对键值对每个value应用函数func,key不变 |
行动操作是真正触发计算的操作。Spark程序执行到行动操作时才会执行真正的计算,从文件或数组中加载数据,完成一次又一次的转换操作,直至得到结果。常用的Action操作如表2.2所示。
表2.2 常用的Action操作
| 行动(方法) | 含义 |
|---|---|
| count() | 返回RDD数据集中的元素个数 |
| collect() | 以数组的形式返回RDD数据集中的所有元素 |
| first() | 返回RDD数据集中的第一个元素 |
| take(n) | 以数组的形式返回RDD数据集中的前n个元素 |
| reduce(func) | 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素 |
| foreach(func) | 将RDD数据集中的每个元素传递到函数func中运行 |
操作举例
【map】计算RDD中各值的平方。
from pyspark import SparkContext
sc = SparkContext('local[*]','test1')#第一个参数表示本地cpu资源
nums = sc.parallelize([1,2,3,4,5])#parallelize转换操作,创建RDD
squared = nums.map(lambda x : x * x).collect()#map转换以及collect行动操作返回列表
for num in squared:
print(num,end=' ')
print('')
【filter】从列表[1,2,3,4]中获得大于2的值。
from pyspark import SparkContext
sc = SparkContext('local[*]','test2')
nums = sc.parallelize([1,2,3,4,5])
squared = nums.filter(lambda x : x > 2).foreach(print)
【flatMap】切分单词。
from pyspark import SparkContext
sc = SparkContext('local[*]','test3')
words = sc.textFile('./input/word.txt')
word = words.flatMap(lambda line : line.split(" "))
word.foreach(print)
【reduceByKey】使用func函数合并具有相同键的值
from pyspark import SparkContext
sc = SparkContext('local[*]','test4')
words = sc.parallelize(['hello word','hadoop','i love hadoop','spark','i love spark','spark is fast then hadoop'])
word = words.flatMap(lambda line : line.split(" ")).map(lambda word : (word,1))
#word.foreach(print)
word.reduceByKey(lambda a,b : a+b).foreach(print)
【groupByKey】对具有相同键的值进行分组。
from pyspark import SparkContext
sc = SparkContext('local[*]','test3')
words = sc.textFile('./input/word.txt')
word = words.flatMap(lambda line : line.split(" ")).map(lambda word : (word,1))
#word.foreach(print)
result = word.groupByKey().collect()
res = [(x,sorted(y)) for (x,y) in result]
print('groupbykey:')
word.groupByKey().foreach(print)
print('zc:\n{}'.format(res))
【keys,values,count】返回键值对RDD中的键,值,形成一个新的RDD,返回一个int值,RDD的元素个数。
from pyspark import SparkContext
sc = SparkContext('local[*]','test3')
list = [('spark',1),('hadoop',3),('spark',2),('hadoop',4),('gu',8)]
rdd = sc.parallelize(list)
#rdd.foreach(print)
rdd.keys().foreach(print)
rdd.values().foreach(print)
print(rdd.count())
for n in rdd.mapValues(lambda x:x+1).collect():
print(n)
2.8 RDD持久化
Spark RDD采用惰性求值的机制,但是每次遇到行动操作都会从头开始执行计算,每次调用行动操作都会触发一次从头开始的计算,这对于迭代计算而言代价是很大的,迭代计算经常需要多次重复使用同一组数据:
无持久化语句:
val list = List("Hadoop","Spark","Hive")
val rdd = sc.parallelize(list)
println(rdd.count()) //行动操作,触发一次真正从头到尾的计算
println(rdd.collect().mkString(",")) //行动操作,触发一次真正从头到尾的计算
可以通过持久化(缓存)机制避免这种重复计算的开销,可以使用persist()方法对一个RDD标记为持久化,之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化,持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用。
persist()的圆括号中是持久化级别参数,persist(MEMORY_ONLY)表示将RDD作为反序列化的对象存储于JVM中,如果内存不足就按照LRU原则替换缓存中的内容;persist(MEMORY_AND_DISK) 表示将RDD作为反序列化的对象存储在JVM中,如果内存不足,超出的分区将会被存放在硬盘上;一般而言,使用cache()方法时,会调用persist(MEMORY_ONLY),同时可以使用unpersist()方法手动地把持久化的RDD从缓存中移除。
针对上面的实例,增加持久化语句以后的执行过程如下:
val list = List("Hadoop","Spark","Hive")
val rdd = sc.parallelize(list)
rdd.cache() //会调用persist(MEMORY_ONLY),但是,语句执行到这里,并不会缓存rdd,因为这时rdd还没有被计算生成
println(rdd.count()) //第一次行动操作,触发一次真正从头到尾的计算,这时上面的rdd.cache()才会被执行,把这个rdd放到缓存中
println(rdd.collect().mkString(",")) //第二次行动操作,不需要触发从头到尾的计算,只需要重复使用上面缓存中的rdd
2.9 RDD分区
RDD是弹性分布式数据集,通常RDD很大,会被分成很多个分区分别保存在不同的节点上,分区的作用:增加并行度,减少通信开销。
RDD分区原则是使得分区的个数尽量等于集群中的CPU核心(core)数目,对于不同的Spark部署模式而言(本地模式、Standalone模式、YARN模式、Mesos模式),都可以通过设置spark.default.parallelism 这个参数的值,来配置默认的分区数目。
一般而言:
(1)本地模式:默认为本地机器的CPU数目,若设置了local[N],则默认为N;
(2)Standalone或YARN:在“集群中所有CPU核心数目总和”和“2”二者中取较大值作为默认值。
(3)Mesos 模式:默认的分区数是8。
设置分区的个数有两种方法:
(1)创建RDD时手动指定分区个数,使用reparititon方法重新设置分区个数;
(2)创建RDD时手动指定分区个数,在调用textFile()和parallelize()方法的时候手动指定分区个数即可,语法格式如 sc.textFile(path, partitionNum),其中path参数用于指定要加载的文件的地址,partitionNum参数用于指定分区个数。
parallelize方法手动指定分区个数:
val array = Array(1,2,3,4,5)
val rdd = sc.parallelize(array,2) //设置两个分区
reparititon方法重新设置分区个数:通过转换操作得到新RDD时,直接调用repartition方法即可:
val data = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt",2)
data.partitions.size //显示data这个RDD的分区数量
val rdd = data.repartition(1) //对data这个RDD进行重新分区
rdd.partitions.size
res4: Int = 1















 915
915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









