







一、上次课回顾
-
https://blog.csdn.net/SparkOnYarn/article/details/105430370
-
主要讲了ERP的一些模块(基础信息维护、采购流程、销售、零售流程维护),仓库阈值、仓库盘点;数据仓库:一堆数据集合,挖掘有效价值,提供企业决策;设计大数据项目架构要考虑上游来的数据类型(log类型、DB类型);报表和实时大屏,底层存储数据一般只存储最小粒度的多维汇总数据;静态报表和动态报表的相辅相成;
-
离线的数仓分层,ODS(operation data store) 原始数据层–> DWD(data warehouse detail) 数据明细层 --> DWS(data warehouse service) 轻度汇总层 --> ADS(application data store)
数仓分层:
ODS(operation data store)原始数据层,存放原始数据,不做任何的处理
DWD(data warehouse detail)明细层,结构和粒度与ODS层是一致的,只做对ODS层的数据清洗
DWS(data warehouse service)轻度汇总层,以DWD层为基础,进行轻度汇总,使用join做一张大宽表
ADS(application data store)结果层,按照主题提供统计数据(group计算),少量可能做join
二、场景(业务表补updatetime字段)
- 在MySQL中的建表规范中有一个createtime和updatetime字段,MySQL业务表由于开发水平参差不齐,未加updatetime字段的话,会存在问题;
举例:MySQL --> Hive,存在如下数据:
- 12月10号的数据:
| MySQL | Hive |
|---|---|
| id、value、createtime | id、value、createtime |
| 1 100 2019-12-10 10:00:00 | 1 100 2019-12-10 10:00:00 |
- 12月11日早上10点对MySQL中的这条数据进行变更:
| MySQL | Hive |
|---|---|
| id、value、createtime | id、value、createtime |
| 1 200 2019-12-10 10:00:00 | 1 100 2019-12-10 10:00:00 |
-
这条数据是在12-10号发生的,但是我们在12-11号早上10点的时候对这条数据进行变更如下:1 200 2019-12-10 10:00:00,问题就出现了:
-
在12号零点的时候抽取的就是11号整天的数据,SQOOP根据createtime抽取的话无法抽取到我们在12月11号修改的这条在12月10号产生的数据;所以根据createtime就抽取不到12号的这条数据了。
-
SQL语句如下:(select * from t where createtime>=‘2019-12-10 00:00:00’ and createtime < ‘2019-12-11 00:00:00’),代表着的是从12月10号零点到12月11号零点之间产生的数据;
T+1模式:一天卡一天,11号只抽10号的数据,12号只抽11号的数据,其实就是一个sql把数据查出来。
小结:
updatetime字段:不影响业务,是数据库自己做,不需要上游代码sql做任何变更:
SQL如下:
-
alter table xxx
add column updatetime timestamp not null default current_timestamp on update current_timestamp; -
形象的去理解:
| id | value | createtime | updatetime |
|---|---|---|---|
| 1 | 100 | 2019-12-10 00:00:00 | 2019-12-10 00:00:00 |
| 1 | 200 | 2019-12-10 00:00:00 | 2019-12-11 10:00:00 |
所以生产上要使用updatetime字段进行抽取:
1、QA环境中测试使用一段时间再推到生产上;
2、生产上MySQL是主从架构部署:主节点 --> 写、从节点 --> 读 --> ,不影响主从架构的情况下再申请一个MySQL从从节点上加上updatetime字段;
3、如果第一、第二步都做不到的话,就需要每次sqoop抽取数据前先把Hive中的数据删除干净,全量拉取;
4、MySQL中有一个binlog二进制文件 --> canal、maxwell --> Kafka --> flume --> hive/hdfs (伪实时)
–> Spark/Flink --> hive/hbase (实时)
生产上删除数据后该怎么办?
1、delete from t where id = 100; 物理删除(思考在MySQL中使用物理删除之后,createtime和updatetime都没了,Hive中应该怎么删除???)
2、update t set delflag=1 where id = 100; 逻辑删除;数据还在,只不过是改了个标识。
2.1、数据建模-星型模型
- 数据建模的本质其实就是建立表结构,如果上游在设计表时很规范(主表、明细表、商品表、供应商表、商品类别表),下游就会很轻松;
维度建模:包含三种模型:
- 星型模型、雪花模型、星座模型:
1、星型模型如下:
- depotitem单据事实表:这张表就是ruozedata_depotitem;规范:一个fact事实表,多个dim表(维度表)
- 补充概念:
fact表:像订单这种事实产生的;
dim表:时间维表 供应商商家维表 仓库维表;
- 时间维表(数据不会发生变化的表,createtime一旦生成就是永远不会发生变化);
- 供应商维表(缓慢变化的表,比如供应商的名称,供应商银行卡号发生变化,供应商联系方式也发生变化)、仓库维表
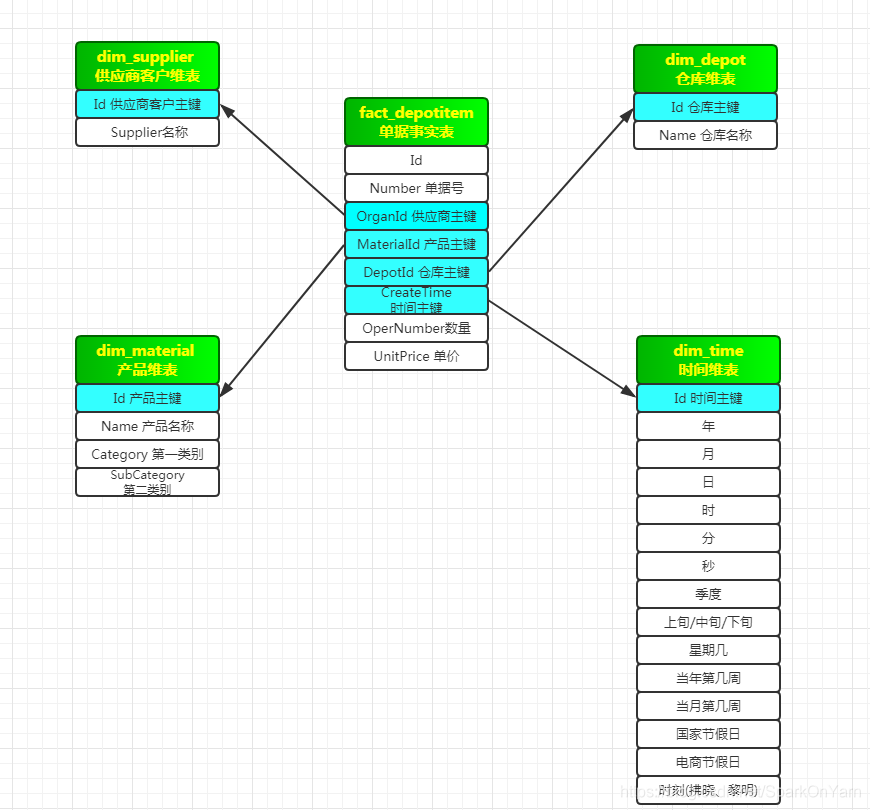
J总公司变态版星型模型:
fact_depotitem单据事实表:head主表+item明细表 --> 生成一张fact_depotitems,它是两张表join之后的一张表。
ruozedata_depotitem是没有createtime字段的,createtime字段是属于主表的
2.2、数据建模-雪花模型
- 仍然是一个事实表,多个dim表,是星型模型的扩展,不同的是维度表被规范化,进一步分解到附加表里;类比到erp数据库表:ruozedata_material和ruozedata_materialcategory表;
- 如下图进行举例:把产品维表进一步分解,分为第一类别维度表和第二类别维度表;而星型模型是产品表和类别表糅合在一起进行了使用。

维度表设计符合3NF,规范化,有效降低数据冗余,但是性能相对肯定差了,同时也复杂,并行度低。
2.3、数据建模-星座模型
- 星座模型是星型模型的延伸,是基于多个事实表,而且共享维度信息。
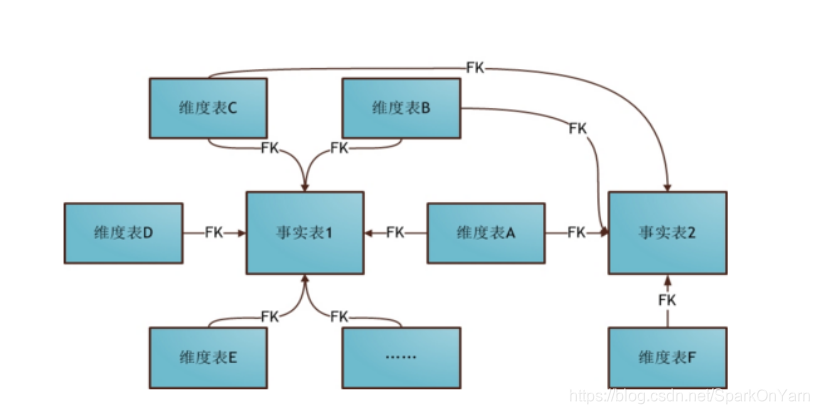
2.4、三种模型总结
星型模型不符合3NF设计,反规范化,不存在渐变维度,数据是有冗余的以存储空间为代价,降低维度表连接数,提高性能。比如地域表,存在数据:
商品名称 第一类别 第二类别
新鲜水果 热带水果 芒果
新鲜水果 热带水果 火龙果
此处的数据冗余指的是:第一类别、商品名称分别存储了两次,虽然此处冗余但是性能最好;相比于雪花模型,需要类别表和商品表进行join,性能就会差些;
商品名称 类别ID
芒果 25
火龙果 25
2、雪花模型是星型模型的扩展,不同的是维度表被规范化,进一步分解到附加表中
这张表在MySQL中相当于是自己join自己,子父表:t1 join t2,t1/t2其实是一张表
| 类别ID | 名称 | 父ID |
|---|---|---|
| 25 | 热带水果 | 18 |
| 25 | 热带水果 | 18 |
| 18 | 新鲜水果 | -1 |
| 18 | 新鲜水果 | -1 |
3、星座模型也是不符合3NF,业务复杂,开发也复杂,性能不高。
在工作当中,比如两张表合为一张表就叫降维,商品+商品类别表 --> 商品表
J总公司降维是没有用的,数仓的理论知识在实战中根本不用;
三、ERP项目架构
-
存储多维度的最小粒度汇总:
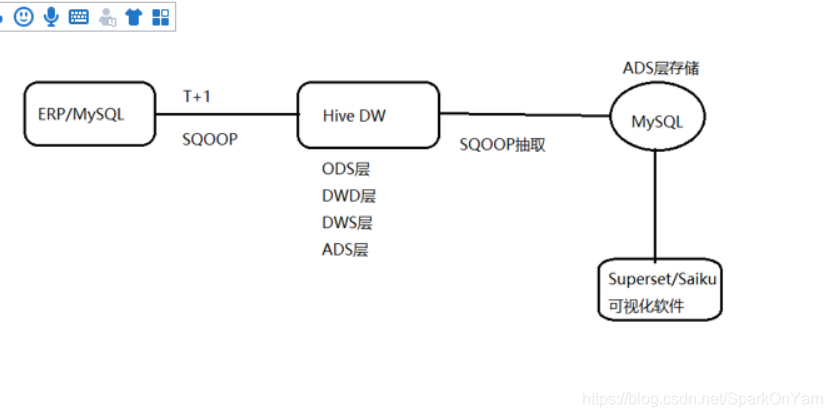
-
MySQL中的数据使用SQOOP通过t+1的方式抽取到Hive中去,Hive的统计结果还是使用SQOOP抽取到MySQL,MySQL的数据再通过Superset(Apache开源)进行可视化展示
-
Hive数仓这层包括ODS层、DWD层、DWS层、ADS层,SQOOP抽取的是ADS层的数据到MySQL,ADS层的数据MySQL存一份、Hive存一份;
3.1、数仓分层流程图
ods商品表+ods商品类别表 --> dwd_sku(两张表合为一张表,降维),一般不用,是因为性能提升不了多少。
事实表也分为明细事实表和聚合事实表:
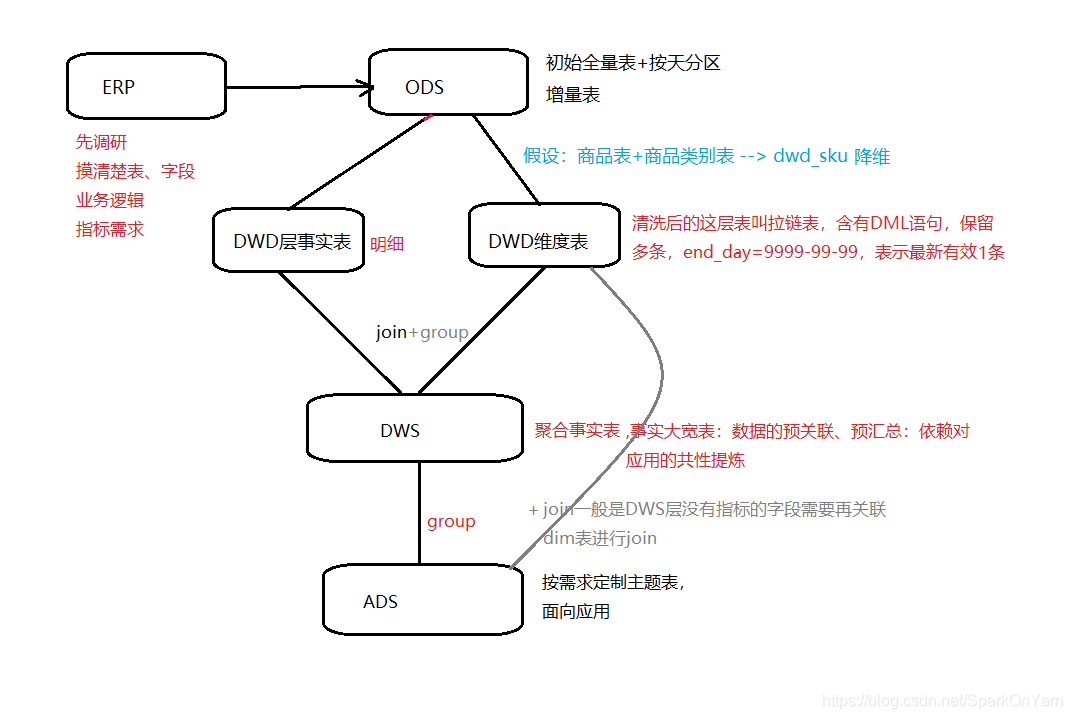
解析上图:
第一层: ODS层分为初始全量表和按天分区增量表;
第二层: ODS层抽取过来上游是什么数据下游就是什么数据,DWD层事实表和DWD维度表,比如上游设计的不恰当,可以在这一层拆分成2个表,或者合并成1个表;商品表+商品类别表 --> dwd_sku,两张维度表变为一张维度表,经过join为一张进行降维;DWD层清洗后的表叫拉链表,含有DML语句,保留多条,end_day=9999-99-99 表示为最新有效1条数据;
第三层: DWD层的事实表+DWD维度表进行join形成轻度汇总层,有时候会在这一层做一些group by语法 --> DWS层,就叫聚合事实表(事实大宽表):进行数据的预关联、预汇总
第四层: 关于共性字段怎么找,运营、qa人员经常使用哪些表的哪些字段;做数仓是给别人使用的,提前沟通好即可;
正常DWS层的数据直接做group by到ADS层,但存在一些需求DWS层没有指标的字段需要再关联dim维表进行join;
数仓就是group by和join、行转列、列转行、window下求topN
为什么要做大数据的原因:
1、技术更新
2、MySQL的单点计算不出来,select查询时间长,在ERP中MySQL就相当于是一串SQL,join\group by,在Hive中先join再group by
MySQL能做TopN,行转列,列转行,window下函数;这些MySQL中都能做,为什么要引进大数据框架呢?
思考问题?
还是上次课程中说的问题:直接ODS层出结果,写到ADS层?
- 数据仓库的分层也不是越多越好,合理的层次设计,以及计算成本,和人力成本的平衡,是一个好的数仓架构表现:
举例:ODS层的数据:5min的力度是200~300G,这种情况下数据再流转到DWD层的话就吃不消;ODS层数据–> DWD–> DWS层是3份数据,如果乘以3副本的数,就相当于是9份数据;数据量大的话分层不仅占用空间,计算也会来不及跟上去;比如:快手、懂车帝、省卫视的直播数据确实是有这么大的。
数据在ODS层1T,–>DWD层 --> 再到DWS层数据就是9T;三副本的情况,每层存储3份;
所以我们需要评估上游现在的总数据量是多少G,评估一年增长多少?
如何评估:取字段最多最大的一张表:根据createtime字段取出2019年的总条数,取出其中一条字段大小,总条数X一条数据的大小;比如估算出来一张表1G,有100张表,再乘以一个系数:1G1003倍=300g
四、ODS --> DWD层是如何做的
打开Dbeaver,选择ruozedata_depothead,我们选择属性,DDL语句:
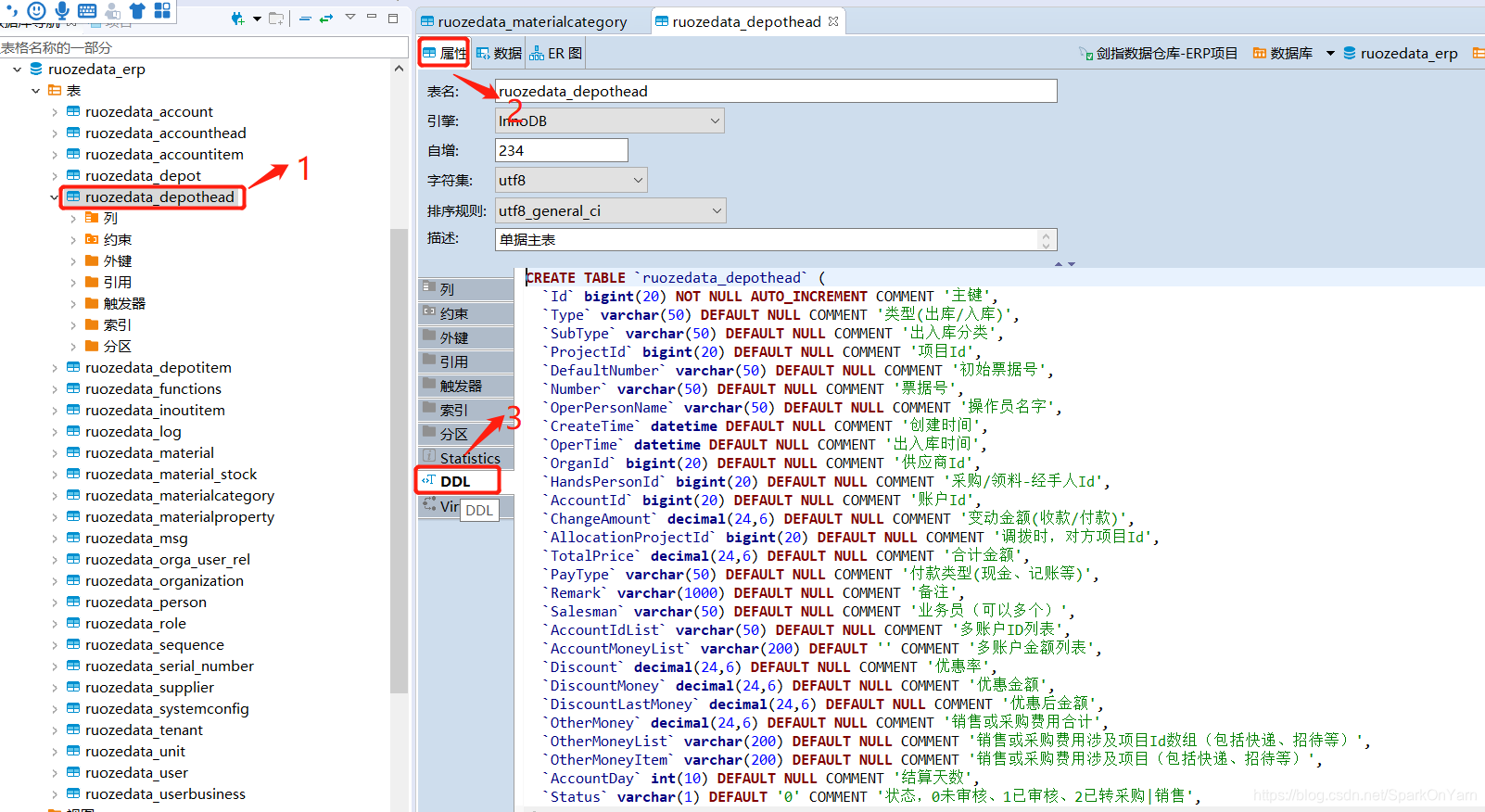
4.1、MySQL转化Hive表结构
要把MySQL中的语法转换为Hive中的语法:
1、去除`符号
2、去除主键 不为空等约束
3、去除 字符集、执行引擎
4、COMMENT=‘单据主表’ --> =去除
5、MySQL的字段类型 --> 转换为Hive字段类型
比如在MySQL中的bigint(20) --> Hive中就叫bigint
datetime --> timestamp
char/varchar --> string
ODS:ods_ruozedata_depothead 普通的全量内部表
ods_ruozedata_depothead_update 普通的分区表,按天增量
DWD:dwd_ruozedata_depothead 普通的内部表,拉链表
drop table ruozedata_erp.ods_ruozedata_depothead;
CREATE TABLE ruozedata_erp.ods_ruozedata_depothead (
Id bigint ,Type string ,SubType string ,ProjectId bigint ,DefaultNumber string,
Number string ,OperPersonName string ,CreateTime timestamp ,OperTime timestamp ,OrganId bigint,
HandsPersonId bigint ,AccountId bigint ,ChangeAmount decimal(24,6) ,AllocationProjectId bigint ,TotalPrice decimal(24,6) ,
PayType string ,Remark string ,Salesman string,AccountIdList string ,AccountMoneyList string ,
Discount decimal(24,6) ,DiscountMoney decimal(24,6) ,DiscountLastMoney decimal(24,6) ,OtherMoney decimal(24,6) ,
OtherMoneyList string,OtherMoneyItem string ,AccountDay int ,Status string ,LinkNumber string ,tenant_id bigint ,delete_Flag string,
UpdateTime timestamp
)COMMENT '单据主表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
drop table ruozedata_erp.ods_ruozedata_depothead_update;
CREATE TABLE ruozedata_erp.ods_ruozedata_depothead_update (
Id bigint ,Type string ,SubType string ,ProjectId bigint ,DefaultNumber string,
Number string ,OperPersonName string ,CreateTime timestamp ,OperTime timestamp ,OrganId bigint,
HandsPersonId bigint ,AccountId bigint ,ChangeAmount decimal(24,6) ,AllocationProjectId bigint ,TotalPrice decimal(24,6) ,
PayType string ,Remark string ,Salesman string,AccountIdList string ,AccountMoneyList string ,
Discount decimal(24,6) ,DiscountMoney decimal(24,6) ,DiscountLastMoney decimal(24,6) ,OtherMoney decimal(24,6) ,
OtherMoneyList string,OtherMoneyItem string ,AccountDay int ,Status string ,LinkNumber string ,tenant_id bigint ,delete_Flag string,
UpdateTime timestamp
)COMMENT '每日单据主表更新表'
PARTITIONED BY (UpdateDay string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
drop table ruozedata_erp.dwd_ruozedata_depothead;
CREATE TABLE ruozedata_erp.dwd_ruozedata_depothead (
Id bigint ,Type string ,SubType string ,ProjectId bigint ,DefaultNumber string,
Number string ,OperPersonName string ,CreateTime timestamp ,OperTime timestamp ,OrganId bigint,
HandsPersonId bigint ,AccountId bigint ,ChangeAmount decimal(24,6) ,AllocationProjectId bigint ,TotalPrice decimal(24,6) ,
PayType string ,Remark string ,Salesman string,AccountIdList string ,AccountMoneyList string ,
Discount decimal(24,6) ,DiscountMoney decimal(24,6) ,DiscountLastMoney decimal(24,6) ,OtherMoney decimal(24,6) ,
OtherMoneyList string,OtherMoneyItem string ,AccountDay int ,Status string ,LinkNumber string ,tenant_id bigint ,delete_Flag string,
UpdateTime timestamp,
StartDay string comment '数据起始时间',
EndDay string comment '数据结束时间'
)COMMENT '单据主表拉链表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
现在的时间点:2020-04-14:14:33:35:
我们此时要做一个全量的数据从MySQL中导入到Hive中;
如下所示:ods_init.sh代码如下所示:
4.2、ods_init.sh脚本
#!/bin/bash
if [ $# != 1 ] ; then
echo "USAGE: $0 TABLENAME Table for initialization of full data sync."
echo "e.g.: $0 ruozedata_depothead."
exit 1;
fi
#parameters
#mac: YESTERDAY=`date -v -1d +%Y-%m-%d`
YESTERDAY=`date -d"-1 day" +%Y-%m-%d`
TODAY=`date +%Y-%m-%d`
#mac: YESTERDAYTIME="`date -v -1d +%Y-%m-%d` 00:00:00"
YESTERDAYTIME="`date -d"-1 day" +%Y-%m-%d` 00:00:00"
TODAYTIME="`date +%Y-%m-%d` 00:00:00"
MySQL_DATABASENAME="ruozedata_erp"
MySQL_TABLENAME="$1"
MySQL_URL="jdbc:mysql://hadoop001:3306"
MySQL_USER="root"
MySQL_PASSWORD="960210"
HDFS_PATH="hdfs://hadoop001:9000"
HIVE_DATABASENAME="ruozedata_erp"
HIVE_ODS_TABLENAME="ods_${1}"
HIVE_PATH="${HDFS_PATH}/user/hive/warehouse/${HIVE_DATABASENAME}.db/${HIVE_ODS_TABLENAME}"
#import
sqoop import \
--connect ${MySQL_URL}/${MySQL_DATABASENAME} \
--username ${MySQL_USER} \
--password ${MySQL_PASSWORD} \
--query "select * from "${MySQL_TABLENAME}" where updatetime<'${TODAYTIME}' and \$CONDITIONS" \
-m 1 \
--hive-import \
--delete-target-dir \
--target-dir "${HIVE_PATH}" \
--hive-database ${HIVE_DATABASENAME} \
--hive-table ${HIVE_ODS_TABLENAME} \
--null-string '\\N' \
--null-non-string '\\N' \
--fields-terminated-by "\t" \
--lines-terminated-by "\n"
exit
如上shell脚本解析:
使用脚本的时候需要传参数,
[hadoop@hadoop001 offlineDW]$ date +%Y-%m-%d
2020-04-14
MYSQL_TABLE="$1",¥ 1 代 表 的 是 需 要 传 入 的 参 数 : 这 个 s h e l l 脚 本 最 核 心 的 话 其 实 就 是 : s e l e c t ∗ f r o m " 1代表的是需要传入的参数: 这个shell脚本最核心的话其实就是:select * from " 1代表的是需要传入的参数:这个shell脚本最核心的话其实就是:select∗from"{MySQL_TABLENAME}" where updatetime<’${TODAYTIME},select * from ruozedata_depothead where updatetime<2020-04-18,将4月14号前的所有历史数据抽取到这张ods全量表。
此时去执行shell脚本:./ods_init.sh ruozedata_depothead;
4.2.1、MySQL --> Hive数据紊乱
- sqopp脚本在抽取的时候可能没问题,但是数据可能有问题,MySQL和Hive做count数比较,一般出现换行符的话会导致两个数据库不一致。
进入到shell的脚本目录中去,专门的拷贝ods_init.sh的这个shell脚本,其实就是改那句select语句;
去到MySQL中的ruozedata_materialcategory这张表中,右键点击这张表,选择生成SQL --> 再选择select;
SELECT `Id`, `Name`, `CategoryLevel`, `ParentId`, sort, status, serial_no, replace(replace(remark,char(10),''),char(13),'') as remark, create_time, creator, update_time, updater, tenant_id, `UpdateTime`
FROM ruozedata_erp.ruozedata_materialcategory;
此时就不存在Hive表了,这种操作不用删除表,数据在运行脚本时会直接进行覆盖;在数据抽取过程中这是一个很正常的过程,千万不要认为shell脚本执行的命令都是okay,其实不然,你的数据是不okay的。
MySQL和Hive做count数比较,可以知道两者的数据是否相同。
SQOOP抽取的时候是okay的,不代表数据是okay的。
ods_init和ods_update的数据已经就是okay的了,此时去做dwd层的数据;
4.2.2、Yarn出现unhealthy nodes
- df -h查看磁盘,磁盘使用率达到91%,达到生产阈值,就会出现这个情况,unhealthy nodes
1、使用df -h查看磁盘目录:
[hadoop@sz5i5j-01 software]$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 40G 34G 4.2G 89% /
devtmpfs 7.8G 0 7.8G 0% /dev
tmpfs 7.8G 0 7.8G 0% /dev/shm
tmpfs 7.8G 1.5M 7.8G 1% /run
tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup
tmpfs 1.6G 0 1.6G 0% /run/user/0
/dev/vdb1 197G 36G 152G 19% /data
tmpfs 1.6G 0 1.6G 0% /run/user/1000
/dev/vda1一旦超过90%这个阈值以后,就会变成unhealthy nodes,我清理了一下空间,变成89%,节点就变为active nodes了。

4.3、ods_update.sh脚本(ods增量)
- 昨晚ods_init.sh脚本后开始制作ods_update.sh脚本:
- 比如每晚凌晨1点执行:
此时时间点:2020-04-14 15:03:30,要将ods_ruozedata_depothead数据初始化导入到ods_ruozedata_depothead_update表,shell脚本如下:
#!/bin/bash
if [ $# != 1 ] ; then
echo "USAGE: $0 TABLENAME Table for initialization of incremental data sync."
echo " e.g.: $0 ruozedata_depothead"
exit 1;
fi
#parameters
#mac: YESTERDAY=`date -v -1d +%Y-%m-%d`
#YESTERDAY=`date -d"-1 day" +%Y-%m-%d`
TODAY=`date +%Y-%m-%d`
#mac: YESTERDAYTIME="`date -v -1d +%Y-%m-%d` 00:00:00"
#YESTERDAYTIME="`date -d"-1 day" +%Y-%m-%d` 00:00:00"
#TODAYTIME="`date +%Y-%m-%d` 00:00:00"
YESTERDAY="2020-04-13"
YESTERDAYTIME="2020-04-13 00:00:00"
TODAYTIME="2020-04-14 00:00:00"
MySQL_DATABASENAME="ruozedata_erp"
MySQL_TABLENAME="$1"
MySQL_URL="jdbc:mysql://hadoop001:3306"
MySQL_USER="root"
MySQL_PASSWORD="960210"
HDFS_PATH="hdfs://hadoop001:9000"
HIVE_DATABASENAME="ruozedata_erp"
HIVE_ODS_TABLENAME_UPDATE="ods_${1}_update"
HIVE_PATH="${HDFS_PATH}/user/hive/warehouse/${HIVE_DATABASENAME}.db/${HIVE_ODS_TABLENAME_UPDATE}/updateday=${YESTERDAY}"
#import
sqoop import \
--connect ${MySQL_URL}/${MySQL_DATABASENAME} \
--username ${MySQL_USER} \
--password ${MySQL_PASSWORD} \
--query "select * from "${MySQL_TABLENAME}" where updatetime>='${YESTERDAYTIME}' and updatetime<'${TODAYTIME}' and \$CONDITIONS" \
-m 1 \
--hive-import \
--delete-target-dir \
--target-dir "${HIVE_PATH}" \
--hive-database ${HIVE_DATABASENAME} \
--hive-table ${HIVE_ODS_TABLENAME_UPDATE} \
--null-string '\\N' \
--null-non-string '\\N' \
--fields-terminated-by "\t" \
--lines-terminated-by "\n" \
--hive-partition-key "updateday" \
--hive-partition-value ${YESTERDAY}
exit
ods_update.sh对应的sql其实就是:
- insert overwrite table dwd_ruozedata_depothead select *, ‘2020-04-12’ as startday, ‘9999-99-99’ as endday from ods_ruozedata_depothead;
- 数据是9999-99-99代表新的数据,其它日期就是旧数据。
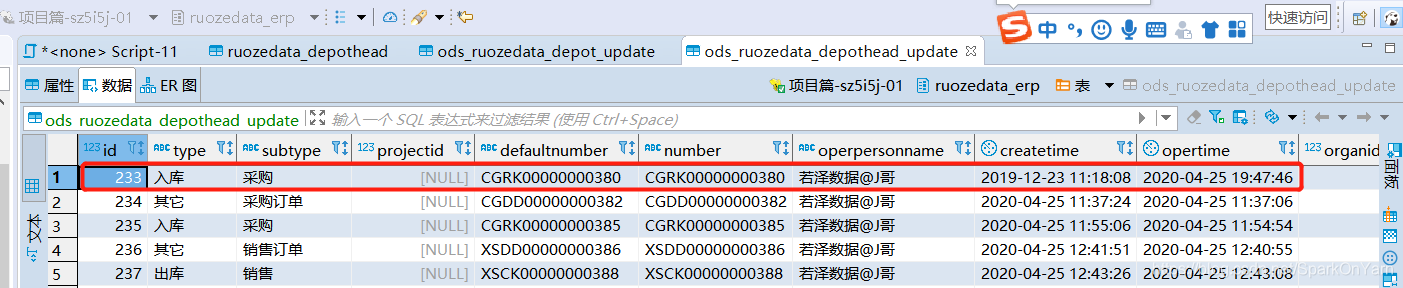
4.4、dwd_update.sh脚本(拉链表)
-
每晚凌晨2点执行:
-
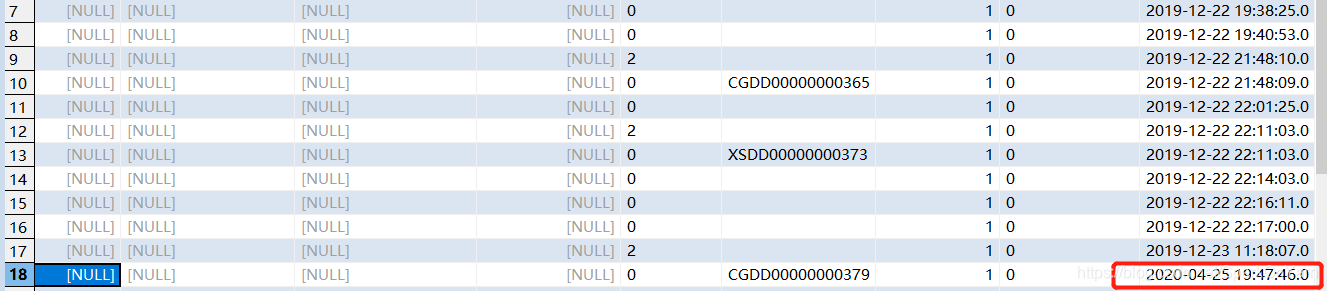
模拟测试数据,新增今天04-25的数据,修改之前的历史数据,就是为了演示拉链表:修改MySQL中ruozedata_depothead这张表下id=18的这条数据,优惠率从4% --> 10%;刷新mysql的表,发现已经进行了修改;

updatetime时间已经进行了更新:
-
涉及到拉链表:
假设D时间点:2020-04-14 02:00:00 做的是DWD拉链表,ods_update对于新增和修改的数据,都在这个分区表中;
对于已经存在修改的数据需要把它作废,新数据标识为9999-99-99;新增数据加上标识9999-99-99;
此处编辑脚本:vi dwd_update.sh
最核心的SQL:
select
a.id, a.type, a.subtype, a.projectid, a.defaultnumber, a.number,
a.operpersonname, a.createtime, a.opertime, a.organid, a.handspersonid, a.accountid, a.changeamount,
a.allocationprojectid, a.totalprice, a.paytype, a.remark, a.salesman, a.accountidlist, a.accountmoneylist,
a.discount, a.discountmoney, a.discountlastmoney, a.othermoney, a.othermoneylist, a.othermoneyitem,
a.accountday, a.status, a.linknumber, a.tenant_id, a.delete_flag, a.updatetime,
a.startday,
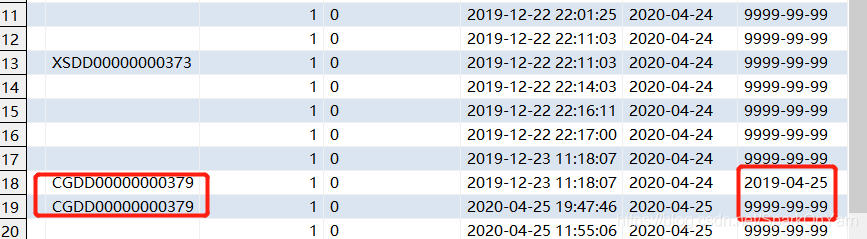
case
when a.endday = '9999-99-99' and b.id is not null then '2019-04-25'
else a.endday
end as endday
from ruozedata_erp. as a
left outer join (select * from ruozedata_erp.ods_ruozedata_depothead_update where updateday='2020-04-25') as b
on b.id = a.id

- 在ruozedata_depothead表中折扣率为4的数据的生命周期已经结束了。
select
id, type, subtype, projectid, defaultnumber, number,
operpersonname, createtime, opertime, organid, handspersonid, accountid, changeamount,
allocationprojectid, totalprice, paytype, remark, salesman, accountidlist, accountmoneylist,
discount, discountmoney, discountlastmoney, othermoney, othermoneylist, othermoneyitem,
accountday, status, linknumber, tenant_id, delete_flag, updatetime,
'2020-04-25' as startday, '9999-99-99' as endday
from ruozedata_erp.ods_ruozedata_depothead_update where updateday='2020-04-25'
SQL解析:
就是两张表做join,dwd_ruozedata_depot新增全量表做主表,id匹配,匹配到就是说明是更新的数据是‘9999-99-99’,匹配不到就是声明周期结束。
dwd_update.sh相当于是:每一次都是自己覆盖自己,自己拿出一份与新增表数据做join,看新旧数据做标识;做分区无法识别dml的操作,这些结果就包含了一些update数据的操作记录,就没必要再去做分区了。
因为数据源是DML语句,要把update的记录维护好,之前的数据也记录起来,因为有时候我们是需要去取这些数据的。
全量表做主表,新增表做匹配:匹配到说明数据是做update is not null,
拉链表:
是为了保存历史的一些状态,需要用拉链表来记录数据,
startday标识数据的生命开始
endday标识数据的声明结束:
2020-04-15 --> 结束
9999-99-99 --> 最新有效数据
假设:每天存一份全量的分区表,浪费空间了,还要涉及到数据的一份变化;数据的前后怎么做标识呢,SQL写的会很复杂;update在13号分区,insert落在14号分区,怎么取最新数据?
生产举例:
分区增量:
04-13号分区 做的是insert操作
04-14号分区做的是update操作
04-15号分区做的是update2操作
我们肯定是取04-15号分区数据(是最新有效的);
除非按表分组,按updatetime排序,取最新的1条 31分区 --> 分组求topN性能肯定是不高的。
按照拉链表的方法如何取最新的数据?
select * from t wher endday=‘9999-99-99’ -->标识数据全部是有效的
分区全量:
13分区 insert
14分区 insert update1
15分区 insert update1 update2 有效分区–>拉链表
–> 层层包含的关系
只要取最新的15号的分区数据就行 --> 拉链表
拉链表的好处:节省存储空间+满足业务需求+计算简单。














 333
333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









