







 本文详细介绍了如何使用Flink处理ODS层业务数据,包括ETL过滤空值,实现动态分流功能,以及维度数据存储的选择。讨论了动态配置的重要性,提出了两种解决方案,最终选择了以MySQL存储配置并使用广播流来实时感知变化,实现了数据写入HBase和Kafka中的功能。
本文详细介绍了如何使用Flink处理ODS层业务数据,包括ETL过滤空值,实现动态分流功能,以及维度数据存储的选择。讨论了动态配置的重要性,提出了两种解决方案,最终选择了以MySQL存储配置并使用广播流来实时感知变化,实现了数据写入HBase和Kafka中的功能。
Flink实时数仓项目—ODS层业务数据到DWD层
前言
前面已经将日志数据和业务数据采集到了Kafka中,Kafka中的ods_xx主题就作为了实时数仓的ODS层。同时,已经完成了将ODS层的日志数据处理完放到了DWD层,下面进行对ODS层业务数据的处理。
之前,我是使用了Flink-CDC将业务数据采集到了Kafka中,把所有的数据写入了同一个主题,但是这些数据包括事实数据、也包括维度数据,使用起来非常不方便。
因此。本层的目的是将ODS层的业务数据进行处理,将维度数据保存到HBase中,将事实数据写回Kafka中作为业务数据的DWD层。
一、ODS层业务数据处理
1.ETL过滤空值数据
首先,我们从Flink-CDC采集到的业务数据的格式不一定完全正确的,数据也不一定是正常的,有些数据是没有必要的(例如Delete类型的数据),所以要做一个简单的过滤,把空值筛选掉。
2.实现动态分流功能
因为Flink-CDC是把全部数据统一写入一个topic中,很明显不方便未来的使用,因此需要把各个表拆开进行处理,相当于做了一个分流操作,把不同的表放到了不同的流里。
在实时计算中一般把维度数据写入存储容器,这样是为了方便通过主键查询,速度较快,比如有:HBase、Redis、MySQL等等。一般把事实数据写入流中,进一步处理,最终形成宽表。
但是会出现一些问题:数据库中的表可能是不完善的,在后面可能会新建表,这样的话,如果我们把表的配置写死,后面很难进行扩展,只能做保存点停止程序,然后修改程序,再重新启动,非常的麻烦。因此需要一种动态配置的方案,把这种配置长期保存下来,一旦配置有变化,实时计算就可以自动感知。
二、功能实现
1.ETL空值过滤
首先,要从Kafka的ods_base_db这个主题中读取数据,然后将读取到的String类型的数据转化为JSON对象类型,然后获取到里面的operation类型,使用filter筛选掉操作类型为delete的数据,实现如下:
//2、消费Kafka的ods_base_db主题中的数据
String topic="ods_base_db";
String groupId="ods_db_app";
DataStreamSource<String> kafkaDataStream = env.addSource(MyKafkaUtil.getKafkaSource(topic, groupId));
//3、将每行数据转换为JSON对象并过滤掉delete数据 主流
SingleOutputStreamOperator<JSONObject> jsonObjDataStream = kafkaDataStream.map(data -> JSON.parseObject(data))
.filter(new FilterFunction<JSONObject>() {
@Override
public boolean filter(JSONObject jsonObject) throws Exception {
//获取对应的操作类型,前面封装的名称是operation
String operation = jsonObject.getString("operation");
return !"delete".equals(operation);
}
});
2.维度数据存储的选择
共有三种选择:HBase、Redis和MySQL,三者其实查询效率都挺高的,都可以通过索引加快查询。
最主要的影响选择的因素:数据量的大小
因为维度数据中某些数据量还是比较大的,比如user表,所以从数据量上来说可以选择HBase和MySQL,Redis就不太合适了(其实也可以将大表放到HBase中,小表放到Redis中,但是太麻烦了,所以不适用)。
但是如果存储到MySQL中,在用到维度数据时,需要到MySQL中查询数据,但是java后端一直在使用MySQL,再让维度表去MySQL中查询数据,会增加MySQL数据库的压力。
所以,综上可以选择存储到HBase中。
3.动态分流再分析
2.1 思路一(Pass)
首先,一种思路就是根据表名,写对应个数的测输出流,业务数据中一共有46张表,那么就需要写46个动态分流…不敢想象,这种方法最容易想到,但是不到万不得已肯定不要去使用。
另外,可能远远不止46张表。例如order_info这张表,它是既会新增又会修改的表,如果我们要求GMV,那我们只需要新增的数据,还要进行过滤;如果我们要变化的数据,那么也需要过滤,因此还得把这张表再次进行拆分。
最后,如果业务数据库新增了一张表,我们写的程序没有写这张表的测输出流,只能进行保存点保存,停掉程序,然后修改程序,然后再重启。
很明显,这样做很麻烦…
2.2 思路二
采用动态配置的方案,一旦配置发生了变化,实时计算可以自动感知,不需要去修改程序。
这又有三种方案可以选择:
1)使用zookeeper存储,通过Watch感知数据变化(zookeeper的方式写的很少,所以不使用)。
2)使用mysql数据库存储,周期性的同步。
在mysql中维护这样一张表:
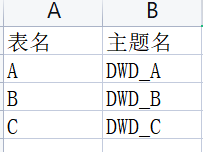
一列是业务数据库的表名,对应一列是这张表应该发送到的业务数据库的主题.
比如,此时新建了一张表D,那么这张表也会新增一行:
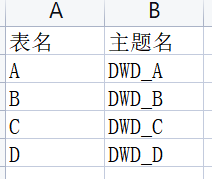
在Flink程序中使用定时器定期去mysql中查询这样的配置信息,就可以做到配置变化的自动感知。
问题:可能会出现丢数据的问题?
问题描述:比如刚扫描完配置文件,建了一张新表,在下次扫描前,这个时间段内的数据可能会丢失。
解决办法:跟后端业务人员商量好,先在配置文件中进行修改,确保Flink程序已经扫描过了配置文件后,再去新建表,这样就不会丢数据。
3)使用mysql数据库存储,使用广播流。
如下图:
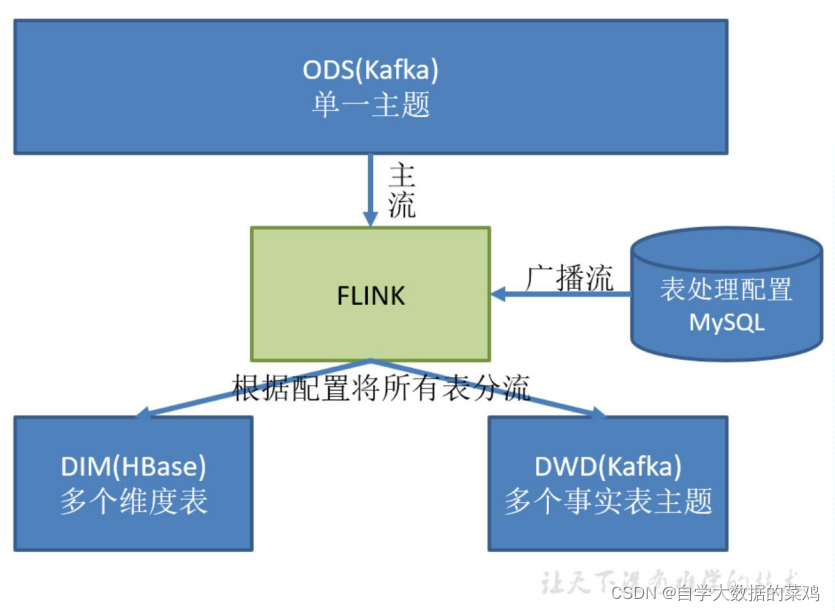
我们使用MySQL存储相关的配置信息,然后用Flink-CDC监控这个表,再将采集到的数据作为一个广播流(因为主流多个并行度,每个并行度都要收到这样的配置文件),用主流和广播流进行连接。这样,当配置文件新增一条信息时,广播流也会实时输出这条信息,主流就会知道发生了变化,就可以根据最新的信息做相应的处理。
综上所述,采用第三种方法最为合适。
4.思路二实现
分流操作是在ETL之后的操作,所以当前数据格式为JSONObject类型。
4.1 配置表字段的确定
我们需要通过配置表来获取到mysql某张表的数据要放到HBase或Kafka中的哪个地方,因此需要对表中的字段进行具体的分析:
要知道采集到的数据是来源于哪张表,所以要有——来源表这个字段。
因为前面提到了新增和变化的数据要区分开,所以要有——操作类型这个字段。
因为维度表放在HBase中,事实表放在Kafka中,所以要有——输出类型这个字段。
对应的,写入HBase中需要一个表名,写入Kafka中需要一个主题,所以要有——输出表名(主题名)这个字段。
将数据写入到Kafka中是可以自动创建topic的,但是使用Phoenix往HBase中写入数据时,如果表不存在,会发生异常,所以我们需要自己去建表,对应的,需要——建表所需的列名这个字段。
Phoenix中建表还要求必须有主键,所以需要——主键这个字段。
在建MySQL中表的时候,在建表语句后可能还有一些别的扩展字段,例如指明字符编码等,在Phoenix中也一样,所以需要——扩展语句这个字段。
综上所述,建表语句如下:
CREATE TABLE `table_process` (
`source_table` varchar(200) NOT NULL COMMENT '来源表',
`operate_type` varchar(200) NOT NULL COMMENT '操作类型 insert,update,delete',
`sink_type` varchar(200) DEFAULT NULL COMMENT '输出类型 hbase kafka',
`sink_table` varchar(200) DEFAULT NULL COMMENT '输出表(主题)',
`sink_columns` varchar(2000) DEFAULT NULL COMMENT '输出字段',
`sink_pk` varchar(200) DEFAULT NULL COMMENT '主键字段',
`sink_extend` varchar(200) DEFAULT NULL COMMENT '建表扩展',
PRIMARY KEY (`source_table`,`operate_type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
4.2 TableProcess实体类的创建
@Data
public class TableProcess {
//动态分流Sink常量
public static final String SINK_TYPE_HBASE="hbase";
public static final String SINK_TYPE_KAFKA="kafka";
public static final String SINK_TYPE_CK="clickhouse" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4978
4978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









