







前言
本文所有内容基于CentOS 7上的Python 2.7.5做演示,这里解释下为什么不用最新的Python 3 ,Python 3.x是最新的Python版本,将来终会淘汰Python 2成为最主流的版本。但是目前很多和计算机网络有关的模块比如Ansible, Scapy, Trigger, easySNMP等在Python 3中并没得到很好的支持就目前的趋势来看,离Python 3彻底淘汰Python 2至少还有几年的时间,而且2和3的区别虽然有,但是如果你彻底掌握了2的话,只需要几天时间就能将3懂个80%,因此目前我们完全可以从2开始学起,另外2.7.5算是比较旧的版本,但是对初学者来说完全够用了。(文章较为详细,需耐心看完)
一、运行Python
Python的运行模式大致分为两种:一种是使用解释器(interpreter)的交互模式,另外一种是使用编辑器编写的脚本的脚本(Script)模式。使用解释器和脚本来运行Python最大的区别是前者能在你执行一行或一段代码后提供"即时反馈"让你看到是否得到了想要的结果或者告诉你代码是否有误,而后者则是将整段代码写入一个扩展名为.py的文本文件中“打包执行”,脚本模式在实际的网络运维工作中很常见。但是从学习的角度来讲,肯定是能提供“即时反馈”的解释器更利于初学者,因此本文大部分内容将基于解释器的交互模式来讲解,当然,也有某些代码案例是必须用到脚本模式来进行演示的。
安装好Python后,打开CentOS的terminal输入python即可进入Python的解释器。
[root@localhost ~]# python
Python 2.7.5 (default, Jul 13 2018, 13:06:57)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>>
注:在下文举例演示的所有代码中,如果代码前面有带">>>“符号,即为在解释器下运行的代码,如果不带”>>>"符号的代码,即为脚本模式下运行的代码。
二、Python基础内容
2.1 变量 (Variable)
所谓变量,顾名思义,是指在程序运行过程中,值会发生变化的量。与变量相对应的是常量,也就是在程序运行过程中值不会发生变化的量,不同于C/C++等语言,Python并没有严格定义常量这个概念,在Python中约定俗成的方法是使用全大写字母的命名方式来指定常量,比如圆周率PI=3.1415926。
变量是存储在内存中的一个值,当你创建一个变量后,也就意味着你在内存中预留了一部分空间给它。变量用来指向同样存储在内存中的一个对象,每个对象根据自身情况又可以代表不同的数据类型(Data Type)。我们可以通过变量赋值这个操作来将变量指向一个对象,比如下面的a = 10即是一个最简单的变量赋值的示例:
>>> a = 10
在Python里我们使用等号"="来连接变量名和值,进而完成变量赋值的操作,这里我们将10这个整数(也就是内存中的对象)赋值给了a这个变量,因为10本身是**“整数”(Integer)**,所以变量a此时代表了“整数”这个数据类型。我们可以使用type()这个函数来确认a的数据类型,可以发现变量a的数据类型此时为int,也就是integer的缩写。
>>> type(a)
<type 'int'>
Python是一门动态类型语言,和C、JAVA等语言不同,你无需手动指明变量的数据类型,根据赋值的不同你可以随意更改一个变量的数据类型,举例来说刚才我们把“整数”这个数据类型赋值给了a这个变量,现在我们再次赋值一个内容为test的**“字符串”(String)**数据类型给变量a,然后用type()函数来确认,这时你会发现a的数据类型已经从int变为了str,即字符串。
>>> a = 'test'
>>> type(a)
<type 'str'>
变量名可以用大小写英文字母,下划线,数字来表示,但是不可以以数字开头。举例如下:
>>> test = 'test'
>>> _a_ = 1
>>> 123c = 10
File "<stdin>", line 1
123c = 10
^
SyntaxError: invalid syntax
>>>
这里Python解释器返回了SyntaxError: invalid syntax这个无效语法的错误提示,告诉你123c为无效的变量名。这也是使用解释器来学习Python的优势,代码里出了任何问题你都能得到“即时反馈”。
2.2 方法(method)和函数(function)
方法(method)和函数(function)大体来说是可以互换的两个词,它们之间有一个细微的区别:函数是独立的功能,需要将数据或者参数传递进去进行处理。方法则与对象有关,不需要传递数据或参数就可以使用。举个例子,前面我们讲到的type()就是一个函数,你需要将一个变量或者数据传入进去它才能运作并返回一个值,举例如下:
>>> a = 123
>>> type(a)
<type 'int'>
>>>
>>> type('xyz')
<type 'str'>
方法则需要和一个对象(变量或数据)关联,无需传递任何参数就可以返回一个值,比如下面的upper()就是一个方法,它的作用是将字符串内容里小写的英文字母转换为大写的英文字母,举例如下:
>>> vendor = 'Cisco'
>>> vendor.upper()
'CISCO'
这里我们创建了一个名为vendor的变量,并将字符串内容’Cisco’赋值给它,随后我们对该变量调用upper()这个方法,返回的值即为所有字母都变为大写的’CISCO’。
在Python里,每种数据类型都有自己默认自带的函数、方法以及变量,要查看某一数据类型本身具有的函数、方法和变量,可以使用dir()这个函数,这里以字符串和整数为例,举例如下:
>>> dir(str)
['__add__', '__class__', '__contains__', '__delattr__', '__doc__', '__eq__', '__format__', '__ge__',
'__getattribute__', '__getitem__', '__getnewargs__', '__getslice__', '__gt__', '__hash__',
'__init__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__',
'__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__',
'__subclasshook__', '_formatter_field_name_split', '_formatter_parser', 'capitalize', 'center',
'count', 'decode', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'index', 'isalnum',
'isalpha', 'isdigit', 'islower', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower',
'lstrip', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip',
'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
>>> dir(int)
['__abs__', '__add__', '__and__', '__class__', '__cmp__', '__coerce__', '__delattr__', '__div__',
'__divmod__', '__doc__', '__float__', '__floordiv__', '__format__', '__getattribute__',
'__getnewargs__', '__hash__', '__hex__', '__index__', '__init__', '__int__', '__invert__',
'__long__', '__lshift__', '__mod__', '__mul__', '__neg__', '__new__', '__nonzero__', '__oct__',
'__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdiv__', '__rdivmod__', '__reduce__',
'__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__',
'__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__',
'__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__',
'bit_length', 'conjugate', 'denominator', 'imag', 'numerator', 'real']
上面即为使用dir()函数列出的字符串和整数所自带的函数、方法与变量,注意其中前后带单下划线或双下划线的变量不会在本文中介绍,比如’_formatter_parser’和’__contains__',初学Python的网工只需要知道它们在Python中分别表示私有变量与内置变量,学有余力的网工读者可以自行阅读其他Python书籍深入学习,其他不带下划线的函数与方法并不是每一个都在网络运维中常用,笔者将在下一章节中选取讲解。
2.3 数据类型(Data Type)
前面讲到了,我们可以使用变量来指定不同的数据类型,对网工来说,常用的数据类型的有字符串(String), 整数(Integer), 列表(List), 字典(Dictionary),浮点数(Float),布尔(Boolean)。另外不是很常用的但需要了解的数据类型还包括集合(set), 元组(tuple)以及空值(None),下面一一举例讲解。
2.3.1 字符串(String)
字符串即文本,可以用单引号’‘、双引号""以及三引号’‘’ ‘’'表示,下面会分别讲到三者的区别以及用法。
单引号、双引号
在表示内容较短的字符串时,单引号和双引号比较常用且两者用法相同,比如’cisco’, “juniper”,需要注意的是单引号和双引号不可以混用。
>>> vendor1 = 'Cisco'
>>> vendor2 = "Juniper"
>>> vendor3 = 'Arista"
File "<stdin>", line 1
vendor3 = 'Arista"
^
SyntaxError: EOL while scanning string literal
>>> vendor3 = 'Arista'
这里我们创建了三个变量,vendor1,vendor2以及vendor3,分别将字符串Cisco, Juniper以及Arista赋值给了它们,因为这里字符串Arista混用了单引号和双引号,导致解释器报错,重新给vendor3赋值后解决了这个问题。这时我们可以用print这个语句(statements)将三个变量的内容打印出来。
>>> print(vendor1)
Cisco
>>> print(vendor2)
Juniper
>>> print vendor3
Arista
也许你已经注意到了,这里我们在打印vendor1和vendor2的值时用到了括号(),而打印vendor3时则没有使用括号。这是因为**print语句在Python 3里是函数,必须带括号(), 在Python 2则是可有可无,如果你使用的是Python 3,那么’print vendor3’将会报错,提醒你必须加括号。**除了使用print语句外,在解释器里我们还可以直接输入变量名来获取它的值,这点是编辑器交互模式下特有,脚本模式做不到的,举例如下:
>>> vendor1
'Cisco'
>>> vendor2
'Juniper'
>>> vendor3
'Arista'
这里需要指出的是如果变量中存在换行符\n的话,print会执行换行的这个动作,而在解释器里直接输入变量名的话,解释器则会把换行符\n当做字符串内容的一部分一起返回,举例如下:
>>> banner = "\n\n Warning: Access restricted to Authorised users only. \n\n"
>>> print banner
Warning: Access restricted to Authorised users only.
>>> banner
'\n\n Warning: Access restricted to Authorised users only. \n\n'
>>>
看出区别了吗?
在Python里我们可以通过加号"+"来拼接(concatenation)字符串,举例如下:
>>> ip = '192.168.1.100'
>>> statement = '交换机的IP地址为'
>>>
>>> print statement + ip
交换机的IP地址为192.168.1.100
注意,在使用加号+来将变量拼接合并时,如果其中一个变量为字符串,那么其他所有要与之拼接的变量也都必须为字符串,否则Python会报错,举例如下:
>>> statement1='网段192.168.1.0/24下有'
>>> quantity = 60
>>> statement2='名用户'
>>>
>>> print statement1 + quantity + statement2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: cannot concatenate 'str' and 'int' objects
这里statement1和statement2两个变量都为字符串,但是quantity这个变量为整数,因此print statement1 + quantity + statement2会报错TypeError: cannot concatenate ‘str’ and ‘int’ objects, 提示不能将字符串和整数拼接合并。解决的办法是使用str()这个函数将quantity从整数转化为字符串,举例如下:
>>> print statement1 + str(quantity) + statement2
网段192.168.1.0/24下有60名用户
引号
三引号形式的字符串通常用来表示内容较长的文本文字,它最大的好处是如果遇到需要换行的文本,文本内容里将不再需要用到换行符’\n’。比如路由器和交换机中用来警告非授权用户非法访问设备后果的MOTD(Message of The Day)之类的旗标(banner)配置,此类文本内容通常比较长且需要换行,这时用三引号来表示该文本内容就是最好的选择,举例如下:
>>> motd = ''' ---------------------------------------------------------------------
...
... Warning: You are connected to the Cisco systems, Incorporated network.
... Unauthorized access and use of this network will be vigorously prosecuted.
...
... -------------------------------------------------------------------------------- '''
>>>
>>> print motd
-----------------------------------------------------------------------------------
Warning: You are connected to the Cisco systems, Incorporated network.
Unauthorized access and use of this network will be vigorously prosecuted.
-----------------------------------------------------------------------------------
和字符串相关的方法与函数
- upper()
前面提到过了upper()这个方法,它的作用是将字符串内容里小写的英文字母转换为大写的英文字母。upper()返回的值是字符串,举例如下:
>>> vendor = 'Cisco'
>>> vendor.upper()
'CISCO'
- lower()
顾名思义,与upper()相反,lower()这个方法的作用是将字符串内容里大写的英文字母转换为小写的英文字母。lower()返回的值是字符串,举例如下::
>>> vendor = 'CISCO'
>>> vendor.lower()
'cisco'
- strip()
有时在字符串内容里面会夹杂一些空格,比如’ 192.168.100.1 ',要拿掉这些多余的空格,可以使用strip()。strip()返回的值是字符串,举例如下:
>>> ip=' 192.168.100.1 '
>>> ip.strip()
'192.168.100.1'
- count()
count()用来判断一个字符串内容里给定的字母或数字具体有多少个,比如说要找出’39419591034989320’这个字符串里面有多少个数字9,这时就可以用到count()来帮你完成这项任务。count()返回的值是整数,举例如下:
>>> '39419591034989320'.count('9')
5
>>>
- len()
len()用来判断字符串内容的长度,比如要回答上面提到的’39419591034989320’总共是多少位数,就可以用到len()方法。**len()返回的值是整数,**举例如下:
>>> a='39419591034989320'
>>> len(a)
17
- split()和join()
之所以把这两个方法放在一起讲,是因为它俩关系比较接近,在字符串、列表的转换中互成对应的关系,split()将字符串转换成列表,join()将列表转换成字符串。
目前为止我们还没有讲到列表(List),这里简单讲解一下:在Python中,列表是一组有序的集合,用中括号[]表示,该集合里的数据又被叫做元素,比如[1,3,5,7,9]就是一个最简单的列表,其中的整数1,3,5,7,9都属于该列表的元素,下面我们把该列表赋值给变量list1,用type()来确认该变量的数据类型,可以发现它的数据类型为list。
>>> list1 = [1,3,5,7,9]
>>> type(list1)
<type 'list'>
列表是有序的集合,我们可以使用索引来访问和指定列表中的每个元素,索引的顺序是从数字0开始的。列表索引的用法举例如下:
>>> list1[0]
1
>>> list1[1]
3
>>> list1[2]
5
>>> list1[3]
7
>>> list1[4]
9
>>>
讲完列表后,为了配合下面的案例,这里需要讲一下raw_input()函数。
- raw_input()函数是Python 2独有的,Python 3里已经被input()替代。
- raw_input()返回的值是字符串。
- 它的作用是用来提示用户输入数据与Python程序互动,比如说你想要写一段程序询问用户的年龄多大,然后让用户自己输入自己的年龄,可以写一段这样的脚本代码:
[root@localhost ~]# cat demo.py
age = raw_input('How old are you? ')
print ('Your age is: ' + age)
然后执行该脚本代码:
[root@localhost ~]# python demo.py
How old are you? 32
Your age is: 32
注意这里的’32’是用户自己输入的,虽然它看着像整数,但是它实际的数据类型是字符串。
了解了列表和raw_input()函数大致的原理和用法后,再来看下网工如何在网络运维中使用split()和join()。举例来说,在大中型公司里,IP地址的划分一般是有规律可循的,比如说某公司有一栋10层楼的建筑,一楼的IP子网为192.168.1.0/24,二楼为192.168.2.0/24,三楼为192.168.3.0/24,以此类推。现在你需要做个小程序,让用户输入任意一个属于公司内网的IP地址,然后让Python告诉用户这个IP地址属于哪一层楼。思路如下:
因为该公司内网IP的第一段都为192,第二段都为168, 第四段不管用户输入任何IP都不影响我们对楼层的判断。换句话来说,这里我们只能从该IP的第三段来判断是哪一层楼,但是我们要怎样告诉Python去判断哪一个数字是属于IP地址的第三段呢?这时就可以用到split()来将用户输入的ip地址(字符串)转化成列表,然后再通过列表的索引来指向IP的第三段,举例如下:
>>> floor1='192.168.1.0'
>>> floor1_list = floor1.split('.')
>>>
>>> print floor1_list
['192', '168', '1', '0']
>>>
>>> floor1_list[2]
'1'
这里我们先将’192.168.1.0’赋值给floor1这个变量,再对该变量调用split()这个方法,然后将返回的值赋值给另外一个变量floor1_list,注意这里split()括号里的’.‘表示分隔符,该分隔符用来对字符串进行切片,因为IP地址的写法都是4个数字用3个点’.‘分开,所以这里分隔符用的是’.',因为split()返回的值是列表,所以这里我们print floor1_list后可以看到,IP地址的四个数字已经被切片独立开来,分别成为了组成floor1_list这个列表的四个元素里的其中之一,之后我们就可以通过floor1_list[2]这种索引的方式来查询该列表里的第三个元素,从而得到第三段IP的数值了,也就是这里的数字1。
知道怎么通过split()来获取IP地址的第三段的数字后,回到前面的需求:让用户输入任意一个属于公司内网的IP地址,然后让Python告诉用户这个IP地址属于哪一层楼。脚本代码如下:
[root@localhost ~]# cat demo.py
# coding=utf-8
ip = raw_input('输入要查询的IP地址: ')
ip_list = ip.split('.')
print '该IP地址属于' + ip_list[2] + '楼.'
这里讲一下,如果使用脚本模式运行Python并且代码中出现了中文的话,那么必须在代码的开头加上一段**# coding=utf-8**,这是因为Python默认的编码格式是ASCII,如果不修改编码格式的话Python将无法正确显示中文。
这里我们使用raw_input()函数提示用户输入想要查询的IP地址,然后将得到的值(字符串)赋值给变量ip,随后我们对其调用split()函数,并将返回的值(列表)赋值给另外一个变量ip_list,然后通过ip_list[2]做索引,得到该列表里的第三个元素,也就是用户输入的IP地址的第三段,最后用print将查询的结果返回告知用户。
执行代码看效果:
[root@localhost ~]# python demo.py
输入要查询的IP地址: 192.168.3.100
该IP地址属于3楼
讲完split()后,再来看下join()怎么用。首先来看下面这个列表,它包含了开启一个思科交换机端口的几条最基本的命令:
>>> commands = ['configure terminal', 'interface Fa0/1', 'no shutdown']
这几条命令缺少了关键的一点:换行符\n(也就是回车键),这时我们可以使用join()来将换行符\n加在每条命令末尾,注意join()返回的值是字符串。
>>> '\n'.join(commands)
'configure terminal\ninterface Fa0/1\nno shutdown'
再举个例子,如果我们要把之前的列表[‘192’, ‘168’, ‘1’, ‘0’]转换回字符串’192.168.1.0’,可以这样做:
>>> '.'.join(['192','168','1','0'])
'192.168.1.0'
如果不加这个点’.'会怎样?试试看:
>>> ''.join(['192','168','1','0'])
'19216810'
- startswith(), endswith(), isdigit(), isalpha()
之所以把上述四个字符串的函数和方法放在一起讲,是因为**它们返回的值都是布尔值(Boolean)。**布尔类型只有两种: True和False,且首字母必须为大写,true和false都不是有效的布尔值。布尔值通常用来判断条件是否成立,如果成立,则返回True,如果不成立,则返回False。
首先来看startswith(),它用来判断字符串里的内容是否以给定的字符串开头,举例如下:
>>> ip = '172.16.5.12'
>>> ip.startswith('17')
True
>>> ip.startswith('172.')
True
>>> ip.startswith('192')
False
endswith()与startswith()相反,用来判断字符串里的内容是否以给定的字符串结尾,举例如下:
>>> ip = '192.168.100.11'
>>> ip.endswith('1')
True
>>> ip.endswith('11')
True
>>> ip.endswith('2')
False
字符串的内容包罗万象,字符串可以为空,可以为中文汉字或英文字母,可以为整数或小数,可以为任何标点符号,也可为上述任一形式的组合。而isdigit()就是用来判断字符串的内容是否为整数,举例如下:
>>> year='2019'
>>> year.isdigit()
True
>>> vendor='F5'
>>> vendor.isdigit()
False
>>> PI='3.1415926'
>>> PI.isdigit()
False
>>> IP='1.1.1.1'
>>> IP.isdigit()
False
isalpha()用来判断字符串的内容是否为英文字母,举例如下:
>>> chinese = '中文'
>>> chinese.isalpha()
False
>>> english = 'English'
>>> english.isalpha()
True
>>> family_name = 'Wang'
>>> family_name.isalpha()
True
>>> full_name = 'Parry Wang'
>>> full_name.isalpha()
False
>>> age = '33'
>>> age.isalpha()
False
注意,isalpha()很严格,只要字符串内容里出现了哪怕一个非英文字母内容,那么isalpha()就会返回False,比如’Parry Wang’(包含了空格), ‘Parry_Wang’(包含了下划线)等等。
2.3.2 整数(Integer)和浮点数(Float)
在Python中大致有5种数值类型(Numeric Type), 分别为整数(interger), 浮点数(float), 布尔类型(boolean), 长整数(long)以及复数(Complex),对网工来说,掌握前面三种就够了,后面两种不是我们需要关心的。
整数即我们通常理解的不带小数点的正数或负数, 浮点数则是我们可以把Python当成一个计算器,使用+, - , * , // , **等算术运算符做加、减、乘、除、求幂等常见的数学计算,举例如下:
>>> 256 + 256
512
>>> 1.2 + 3.5
4.7
>>> 1024 - 1000
24
>>> 16 * 16
256
>>> 100/10
10
>>> 12 // 10
1
>>> 12 % 10
2
>>> 8**2
64
>>> 3**3
27
在Python里可以通过运算符’**'做幂运算,比如8的2次方可以表示为8**2,3的3次方表示为3**3。
在做除法时,可以看到示例里分别使用了’/‘和’//‘以及’%'三个运算符,它们的区别如下:
'/'表示正常的除法运算,注意在Python2里面,如果碰到整数除整数,结果出现小数部分的时候,比如12 / 10,Python 2只会返回整数部分,即1,要想得到小数点后面的部分,必须将除数或被除数通过float()函数换成浮点数来运算,举例如下:
>>> 12/10
1
>>> 12/float(10)
1.2
>>> float(12)/10
1.2
'//'表示向下取整,求商数。
'%'则表示求余数。
整数也不知单单只是用来做数学运算,通过加号’+‘或乘号’*'两种运算符,它还可以和字符串互动,适合用来画分割线,举例如下:
>>> print 'CCIE ' * 8
CCIE CCIE CCIE CCIE CCIE CCIE CCIE CCIE
>>>
>>> print 'CCIE ' + 'CCIE'
CCIE CCIE
>>>
>>> print '*' * 50
**************************************************
在网络运维中,有时会遇到需要计数器做统计的时候,比如说某公司里有100台思科2960的交换机,由于长期缺乏系统性的运维管理,交换机的IOS版本并不统一,为了统计其中有多少台2960的IOS是最新版本的,我们需要登录所有的交换机,每发现一台IOS为最新的交换机后就通过计数器加一,直到结束。由于要完成这个脚本需要涉及到paramiko, if, for循环, 正则表达式等进阶性的Python知识点,所以这里演示计数器的用法:
>>> counter = 0
>>> counter = counter + 1
>>> counter
1
>>> counter = counter + 1
>>> counter
2
>>> counter += 1
>>> counter
3
>>> counter += 1
>>> counter
4
首先我们创建一个变量counter,将0赋值给它,改变量就是我们最初始的计数器。之后如果每次发现有交换机的IOS为最新版本,我们就在该计数器上+1, 注意counter = counter + 1可以简写为counter += 1。
2.3.3 列表(List)
列表是一组有序的集合,用中括号’[]‘表示,列表里的数据又被叫做元素,每个元素之间以逗号’,'隔开,列表里元素的数据类型可以不用固定,举例如下:
>>> list1 = [2019,1.23,'Cisco',True,None,[1,2,3]]
>>>
>>> type(list1[0])
<type 'int'>
>>> type(list1[1])
<type 'float'>
>>> type(list1[2])
<type 'str'>
>>> type(list1[3])
<type 'bool'>
>>> type(list1[4])
<type 'NoneType'>
>>> type(list1[5])
<type 'list'>
这里我们创建了一个名为list1的变量,并将一个含有6个元素的列表赋值给了它。你可以看到这6个元素的数据类型都不一样,我们使用type()函数配合列表的索引来验证每个元素的数据类型,列表的索引号从0开始,对应列表里的第1个元素。这里可以发现从第1个到第6个元素的数据类型分别为整数,浮点数,字符串,布尔值,空值,以及列表(一个列表本身也可以做为另外一个列表的元素)。
和列表相关的方法与函数
- range()
range()函数用来创建一个整数列表,举例如下:
>>> range(10)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> range(1,15)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
>>> range(1,20,2)
[1,3, 5, 7, 9, 11, 13, 15, 17, 19]
- range()创建的整数列表从0开始,因此range(10)返回的是一个包含整数0-9的列表,并不包含10.
- 也可以指定起始数,比如range(1,15)返回一个包含整数1-14的列表。
- range()还可以通过指定步长来得到我们想要的整数,比如你只想选取1至19里面所有的单数,那么就可以使用range(1,20,2)来实现(这里的2即为步长)。
注:range()返回整数列表的用法仅限于Python 2,在Python 3里range()返回的是一个整数序列的对象,你需要用list()函数将它转换成列表
- append()
append()用来向列表里添加元素,举例如下:
>>> interfaces = []
>>> interfaces.append('Gi1/1')
>>> print interfaces
['Gi1/1']
>>> interfaces.append('Gi1/2')
>>> print interfaces
['Gi1/1', 'Gi1/2']
首先我们建立一个空列表,并把它赋值给interfaces这个变量,然后使用append()方法将端口’Gi1/1’加入至该列表,随后再次调用append()将’Gi1/2’加入至该列表,现在列表interfaces里有两个元素了。
- len()
列表的len()方法和字符串的len()大同小异,前者用来统计列表里有多少个元素,后者用来统计字符串内容的长度,举例如下:
>>> len(interfaces)
2
>>>
>>> cisco_switch_models = ['2960','3560','3750','3850','4500','6500','7600','9300']
>>> len(cisco_switch_models)
8
- count()
和字符串一样,列表也有count()方法,列表的count()用来找出指定的元素在列表里有多少个,举例如下:
>>> vendors = ['Cisco','Juniper','HPE','Aruba','Arista','Huawei','Cisco',
'Palo Alto','CheckPoint','Cisco','H3C','Fortinet']
>>> vendors.count('Cisco')
3
- insert()
**列表是有序的集合,**前面讲到的append()方法是将新的元素添加在列表的最后面,如果我们想自己控制新元素在列表里的位置的话就要用到insert()这个方法。举例如下:
>>> ospf_configuration = ['router ospf 100\n','network 0.0.0.0 255.255.255.255 area 0\n']
>>> ospf_configuration.insert(0, 'configure terminal\n')
>>> print ospf_configuration
['configure terminal\n', 'router ospf 100\n', 'network 0.0.0.0 255.255.255.255 area 0\n']
首先我们创建一个名为ospf_configuration的变量,将配置OSPF的命令写在一个列表里赋值给该变量。随后发现列表里面漏了’configure terminal’这条命令,该命令要写在列表的最前面,这时我们可以用insert(0, ‘configure terminal\n’)来将该命令加在列表的最前面(记住列表的索引是从0开始的)。
如果这时我们还想再给该OSPF路由器配置一个router-id,比如我们想把router-id这条命写在router ospf 100的后面,可以再次使用insert(),举例如下:
>>> ospf_configuration.insert(2, 'router-id 1.1.1.1\n')
>>> print ospf_configuration
['configure terminal\n', 'router ospf 100\n', 'router-id 1.1.1.1\n', 'network 0.0.0.0 255.255.255.255 area 0\n']
- pop()
pop()用来移除列表中的元素,如果不指定索引号的话,pop()默认将拿掉排在列表末尾的元素**,**如果指定了索引号的话,则可以精确移除想要移除的元素,举例如下:
>>> cisco_switch_models = ['2960','3560','3750','3850','4500','6500','7600','9300']
>>> cisco_switch_models.pop()
'9300'
>>> print cisco_switch_models
['2960', '3560', '3750', '3850', '4500', '6500', '7600']
>>> cisco_switch_models.pop(1)
'3560'
>>> print cisco_switch_models
['2960', '3750', '3850', '4500', '6500', '7600']
- index()
看了pop()的用法后,你也许会问:我怎么知道我想要移除的元素的索引号是多少?这时你就需要用到index()了,比如说你想从cisco_switch_models这个列表里移除’4500’这个元素,可以这么操作:
>>> cisco_switch_models = ['2960','3560','3750','3850','4500','6500','7600','9300']
>>> cisco_switch_models.index('4500')
4
>>> cisco_switch_models.pop(4)
'4500'
>>> print cisco_switch_models
['2960', '3560', '3750', '3850', '6500', '7600', '9300']
先通过index()找出’4500’的索引号为4,然后就可以配合pop(4)将它从列表移除。
2.3.4 字典(Dictionary)
在Python里,字典是无序的键值对(key-value pair)的集合,以大括号"{}“表示,每一组键值对以逗号”,"隔开。以下面的例子说明:
>>> dict = {'Vendor':'Cisco', 'Model':'WS-C3750E-48PD-S', 'Ports':48, 'IOS':'12.2(55)SE12', 'CPU':36.3}
这里我们创建了一个变量名为dict的字典。该字典有5组键值对,分别为:
‘Vendor’:‘Cisco’
‘Model’:‘WS-C3750E-48PD-S’
‘Ports’:48
‘IOS’:‘12.2(55)SE12’
‘CPU’:36.3
- 键值对里的键(key)和值(value)以冒号":"隔开,冒号的左边为键,右边为值
- 键的数据类型可为字符串,常数,浮点数或者元组,对网工来说,最常用的肯定是字符串,比如‘Vendor’, ‘Model’等等
- 值可为任意的数据类型,比如这里的’Cisco’为字符串,48为整数,36.为浮点数。
和列表不同,字典是无序的,举例说明:
>>> a = [1,2,3,'a','b','c']
>>> print a
[1, 2, 3, 'a', 'b', 'c']
>>>
>>> dict = {'Vendor':'Cisco', 'Model':'WS-C3750E-48PD-S', 'Ports':48, 'IOS':'12.2(55)SE12', 'CPU':36.3}
>>> print dict
{'IOS': '12.2(55)SE12', 'CPU':36.3, 'Model': 'WS-C3750E-48PD-S', 'Vendor': 'Cisco', 'Ports': 48}
这里我们创建一个内容为[1,2,3,‘a’,‘b’,‘c’]的列表a, 将它打印出来后,列表里的元素的位置没有发生任何变化,因为列表是有序的。但是如果我们将刚才的字典dict打印出来,你会发现字典里键值对的顺序已经彻底被打乱了,没有规律可循,正因为字典是无序的,我们自然也不能像列表那样使用索引来查找字典里某个键对应的值。
在字典里,要查找某个值的格式为: ‘字典名[键名]’,举例如下:
>>> dict = {'Vendor':'Cisco', 'Model':'WS-C3750E-48PD-S', 'Ports':48, 'IOS':'12.2(55)SE12', 'CPU':36.3}
>>> print dict['Vendor']
Cisco
>>> print dict['CPU']
36.3
>>> print dict['Ports']
48
如果要在字典里新添加一组键值对的话,格式为: ‘字典名[新键名]’ = ‘新值’',举例如下:
>>> dict['Number of devices']=100
>>> print dict
{'Vendor': 'Cisco', 'Number of devices': 100, 'IOS': '12.2(55)SE12', 'CPU': 36.3, 'Model': 'WS-C3750E-48PD-S', 'Ports': 48}
如果要更改字典里某个已有键对应的值的话,格式为:‘字典名[键名]’ = ‘新值’',举例如下:
>>> dict['Model'] = 'WS-C2960X-24PS-L'
>>> dict['Ports'] = '24'
>>> print dict
{'IOS': '12.2(55)SE12', 'Model': 'WS-C2960X-24PS-L', 'Vendor': 'Cisco', 'Ports': '24', 'CPU': 36.3}
如果要删除字典里某组键值对的话,命令为: del ‘字典名[键名]’,举例如下:
>>> del dict['Number of devices']
>>> print dict
{'Vendor': 'Cisco', 'IOS': '12.2(55)SE12', 'CPU': 36.3, 'Model': 'WS-C3750E-48PD-S', 'Ports': 48}
>>>
和字典相关的函数和方法
- len()
len()用来统计字典里有多少组键值对。**len()返回的值是整数,**举例如下:
>>> print dict
{'Vendor': 'Cisco', 'IOS': '12.2(55)SE12', 'CPU': 36.3, 'Model': 'WS-C3750E-48PD-S', 'Ports': 48}
>>> len(dict)
5
- keys()
keys()用来返回一个字典里所有的键。keys()在Python 2里返回的值为列表(在Python 3里返回的是可迭代的对象,需要使用list()将它转换为列表,了解即可),举例如下:
>>> print dict
{'Vendor': 'Cisco', 'IOS': '12.2(55)SE12', 'CPU': 36.3, 'Model': 'WS-C3750E-48PD-S', 'Ports': 48}
>>> print dict.keys()
['Vendor', 'IOS', 'CPU', 'Model', 'Ports']
- values()
values()用来返回一个字典里所有的值。values()在Python 2里返回的值为列表(在Python 3里返回的是可迭代的对象,需要使用list()将它转换为列表,了解即可),举例如下:
>>> print dict
{'Vendor': 'Cisco', 'IOS': '12.2(55)SE12', 'CPU': 36.3, 'Model': 'WS-C3750E-48PD-S', 'Ports': 48}
>>> print dict.values()
['Cisco', '12.2(55)SE12', 36.3, 'WS-C3750E-48PD-S', 48]
- pop()
前面讲到了要删除字典里某组键值对的话可以用到命令: del ‘字典名[键名]’,另外我们还可以使用pop()来达到同样的目的,和列表的pop()不一样,字典的pop()不能导入索引号,需要导入的是键名,**而且字典的pop()返回的值不是列表,而是键名对应的值(比如下面的48),**举例如下:
>>> print dict
{'Vendor': 'Cisco', 'IOS': '12.2(55)SE12', 'CPU': 36.3, 'Model': 'WS-C3750E-48PD-S', 'Ports': 48}
>>> dict.pop('Ports')
48
>>> print dict
{'Vendor': 'Cisco', 'IOS': '12.2(55)SE12', 'CPU': 36.3, 'Model': 'WS-C3750E-48PD-S'}
- get()
前面讲到了我们可以使用values()这个方法来得到一个字典里所有的值,除此之外,我们还可以使用get()来返回字典里具体键名对应的值,get()返回的值是所导入的键名对应的值, 举例如下:
>>> print dict
{'Vendor': 'Cisco', 'IOS': '12.2(55)SE12', 'CPU': 36.3, 'Model': 'WS-C3750E-48PD-S'}
>>> dict.get('Vendor')
'Cisco'
>>> dict.get('CPU')
36.3
2.3.5 布尔类型(Boolean)
布尔类型用来判断条件是否成立,布尔值只有两种: True和False,如果条件成立,返回True,如果条件不成立,则返回False。**布尔值的首字母必须为大写,true和false都不是有效的布尔值。**布尔类型在判断语句中常用,Python的判断语句将在进阶内容中详细讲解。
比较运算符
既然布尔类型是用来判断条件是否成立,那这里就不得不提一下Python中的比较运算符,包括等于号"==“、不等于号”!=“,大于号”>“,小于号”<“,大于等于号”>=“,小于等于号”<="。比较运算符和算术运算符_(2.3.2 整数(Integer)和浮点数(Float)中提到)_最大的区别是前者是用来判断符号左右两边的变量或数据是否满足运算符本身的条件,并且返回的值是布尔值,后者则是单纯的做加减乘除等运算,返回的值是整数或浮点数。
在编辑器模式下,使用比较运算符后可以马上看到返回的布尔值True或者False,如果是脚本模式,则需要配合print命令才能看到,举例如下:
>>> a = 100
>>> a == 100
True
>>> a == 1000
False
>>> a != 1000
True
>>> a != 100
False
>>> a > 99
True
>>> a > 101
False
>>> a < 101
True
>>> a < 99
False
>>> a >= 99
True
>>> a >= 101
False
>>> a <= 100
True
>>> a <= 99
False
逻辑运算符
除了比较运算符外,使用逻辑运算符也能返回布尔值**。**逻辑运算符有三种:且(and)、或(or)、否(not)。学习过离散数学的读者朋友对且、或、否的逻辑运算不会感到陌生,在逻辑运算中使用的真值表(Truth Table)如下:
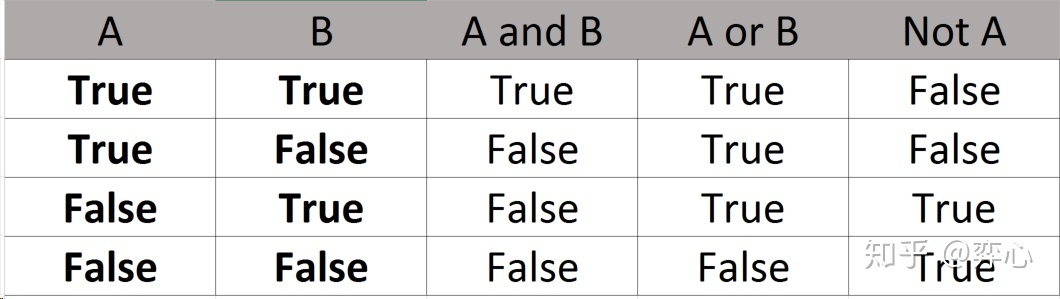
逻辑运算在Python中的使用举例如下:
>>> A = True
>>> B = True
>>> A and B
True
>>> A or B
True
>>> not A
False
>>>
>>>
>>> A = False
>>> B = True
>>> A and B
False
>>> A or B
True
>>> not A
True
>>>
>>> A = False
>>> B = False
>>> A and B
False
>>> A or B
False
>>> not A
True
2.3.6 集合(Set),元组(Tuple),空值(None)
同样做为网工需要掌握的Python数据类型,集合、元组、空值相对来说使用频率不如前面讲到的字符串,整数,浮点数,列表,字典以及布尔类型,这里简单做下介绍。
集合(Set)
- 集合是一种特殊的列表,里面**没有重复的元素,**因为每个元素在集合里只有一个,因此集合没有count()这个方法。
- 集合必须用函数set()创建,不像列表那样可以直接用中括号创建。
>>> vendors = set(['Cisco','Juniper','Arista','Cisco'])
>>> print vendors
set(['Cisco', 'Arista', 'Juniper'])
vendors这个列表里有两个重复的元素,即’Cisco’,在用set()函数将它转换成集合后,多余的一个’Cisco’被去掉,只保留了一个。
- 集合是无序的,不能像列表那样使用索引号,也不具备index()方法。
>>> vendors[2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'set' object does not support indexing、
与集合有关的方法和函数
- add()
add()用来向一组集合里添加新元素,其返回的值依然是集合,举例如下:
>>> vendors.add('Huawei')
>>> vendors
set(['Huawei', 'Cisco', 'Arista', 'Juniper'])
- remove()
remove()用来删除一组集合里已有的元素,其返回的值依然是集合,举例如下:
>>> vendors.remove('Arista')
>>> vendors
set(['Huawei', 'Cisco', 'Juniper'])
元组(Tuple)
- 和集合一样,元组也是一种特殊的列表,它和列表最大的区别是:我们可以任意地对列表里的元素进行增添、删除、修改,而元组则不可以,元组一旦被创建后,将无法对其做任何形式的更改,所以元组没有append(), insert(), pop(), add(), remove(),只保留了index()和count()两种方法。
- 元组可以通过小括号"()"创建,也可以使用函数tuple()创建
- 和列表一样,元组是有序的,可以对元素进行索引。
>>> vendors = ('Cisco','Juniper','Arista')
>>> print vendors
('Cisco', 'Juniper', 'Arista')
>>> print vendors[1]
Juniper
>>> vendors[2] = 'Huawei'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
与元组有关的方法和函数
- index()
元组的index()和列表用法相同,都是用来查询指定元素的索引号的。index()返回的值为整数,举例如下:
>>> vendors
('Cisco', 'Juniper', 'Arista')
>>> vendors.index('Cisco')
0
- count()
元组的index()和列表用法相同,用来查询指定元素在元组中的数量。count()返回的值为整数,举例如下:
>>> vendors = ('Cisco','Juniper','Arista','Cisco')
>>> vendors.count('Cisco')
2
>>> vendors.count('Juniper')
1
空值(None)
空值是比较特殊的数据类型(NoneType),它没有自带的函数和方法,也无法做任何算术运算,但是可以把它赋值给一个变量,举例如下:
>>> type(None)
<type 'NoneType'>
>>> None == 100
False
>>> a = None
>>> print a
None
空值的使用
空值较常用在判断语句和正则表达式中。对网工来说,日常工作中我们经常需要使用显示命令(“show"或者"display”)来对网络设备进行排错或者查询网络信息,很多显示命令通常都会给出很多内容,而我们大多时候只需要关注其中的一、两项参数即可,用Python来实现网络运维自动化的话,我们需要使用正则表达式来告诉Python应该抓取哪一个“关键词”(即我们想要的参数),而空值则可以用来判断“关键词”抓取是否成功。关于判断语句和正则表达式的用法在进阶内容中将会详细讲到。
文末福利
零基础Python学习资料介绍

👉Python学习路线汇总👈
围绕Python所有方向的技术点做的整理,以形成各个领域的知识点汇总,这样就可以按照上面的知识点去找对应的学习资源,保证学得较为全面。

👉Python必备开发工具👈
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉实战案例👈
边学边练是最高效的学习方法,这时候可以搞点实战案例来学习。
👉100道Python练习题👈
检查学习结果。
👉面试刷题👈

资料领取
这份完整版的Python全套学习资料已为大家备好,朋友们如果需要可以微信扫描下方二维码添加,输入"领取资料" 可免费领取全套资料【有什么需要协作的还可以随时联系我】朋友圈也会不定时的更新最前言python知识。↓↓↓
或者
【点此链接】领取

好文推荐
了解python能做哪些事情:https://blog.csdn.net/SpringJavaMyBatis/article/details/127196603
关于python的前景:https://blog.csdn.net/SpringJavaMyBatis/article/details/127194835















 796
796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









