







这篇文章是在读了一篇有关跨模态检索的综述《An Overview of Cross-media Retrieval: Concepts, Methodologies, Benchmarks and Challenges》之后,综述中提到了context信息的重要性,于是记起来之前有篇利用context进行re-id研究的文章没看。
Motivation
在行人检索中只利用行人自身的特征作为检索的线索会造成检索的困难,例如衣服款式相近的行人。本文为了解决这个问题,致力于使用context information来定位行人。
Innovations
本文的innovations主要有两方面
1. Instance expansion
在这个过程中,该文利用probe和gallery中包含同一个target的图像对,从中提取target和positive context information。context information就是target周围的人物特征(这些人物已经通过person detection阶段剪裁出,且人物特征通过part-based的方式提取),而positive context information则是对于定位target有帮助的人物特征。该文利用relative attention module,当y=1,即人物相同,通过调整不同part的权重使sim升过高从而使其loss降低;当y=0时,即人物不相同,通过调整不同part的权重使sim降低从而使loss降低。最终得到一个relative attention network可以赋予不同part不同权重,从而判断probe和gallery中的两个context information是否相似,如果相似则可以作为positive context information。
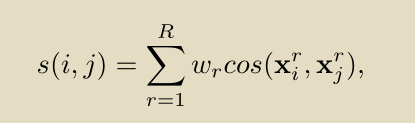
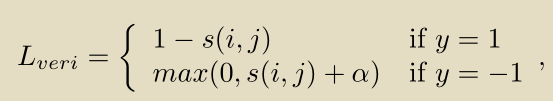
2. Contextual Graph Representation Learning
这里是使用GCN来进一步从target-contexts graph中提取特征,值得注意的做法是graph中的node均为pairs的形式。文章还特意和Siamese GCN的做法进行了比较,并分析Siamese GCN结构的主要缺点是"Siamese structure prevents the contextual information to propagate between graphs, which leads to significant information loss."。虽然文章实验证明了自己方法的有效性,但是这里我没明白不同image中的contextual information流动是否有其意义。
person detection这阶段没怎么仔细研究过,读过的论文也不大多,但是这个阶段该文只是提了下自己的做法,其中一些方法也是之前就有的。














 1341
1341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









