







 该项目是在Kaggle上的NLP挑战,目标是预测推文是否涉及真实灾难。通过EDA、数据预处理,利用Bert进行预训练模型的迁移学习。训练后模型在测试集上达到0.83742的准确率。
该项目是在Kaggle上的NLP挑战,目标是预测推文是否涉及真实灾难。通过EDA、数据预处理,利用Bert进行预训练模型的迁移学习。训练后模型在测试集上达到0.83742的准确率。
Tweet with Disaster(Kaggle NLP项目实战)
项目介绍(Real or Not? NLP with Disaster Tweets)
项目kaggle链接:https://www.kaggle.com/c/nlp-getting-started/overview
在紧急情况下,Twitter已经成为一个重要的沟通渠道。智能手机的普及使人们能够实时宣布正在观察的紧急情况。正因为如此,越来越多的机构对程序化监控Twitter(即救灾组织和新闻机构)感兴趣。但是,人们并不总是清楚一个人的话是否真的在宣告一场灾难。比如下面的例子:

作者明确地使用了“燃烧”这个词,但它的意思是隐喻性的。这一点对人类来说是显而易见的,特别是在视觉辅助下。但对机器来说就不那么清楚了。
在这场竞争中,你面临着建立一个机器学习模型的挑战,该模型可以预测哪些Tweets是关于真正的灾难的,哪些Tweets不是。
EDA
数据预处理部分
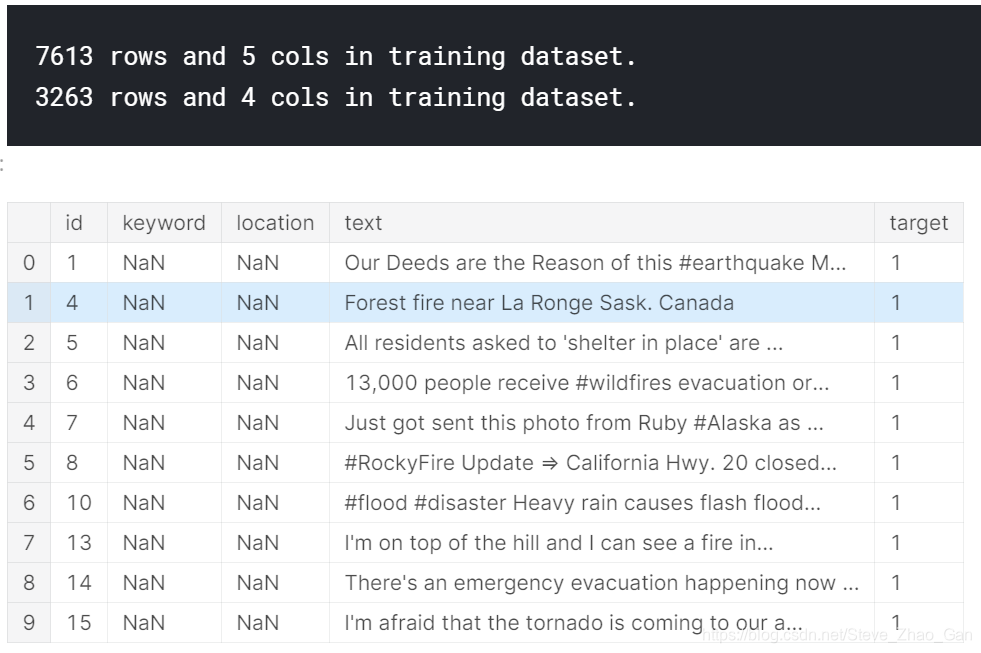
1 导入数据
train = pd.read_csv('../input/nlp-getting-started/train.csv')
test = pd.read_csv('../input/nlp-getting-started/test.csv')
sample_submission = pd.read_csv('../input/nlp-getting-started/sample_submission.csv')
# Print the shape of the training data
print('{} rows and {} cols in training dataset.'.format(train.shape[0], train.shape[1]))
print('{} rows and {} cols in training dataset.'.format(test.shape[0], test.shape[1]))
# Inspecting the training data
train.head(10)
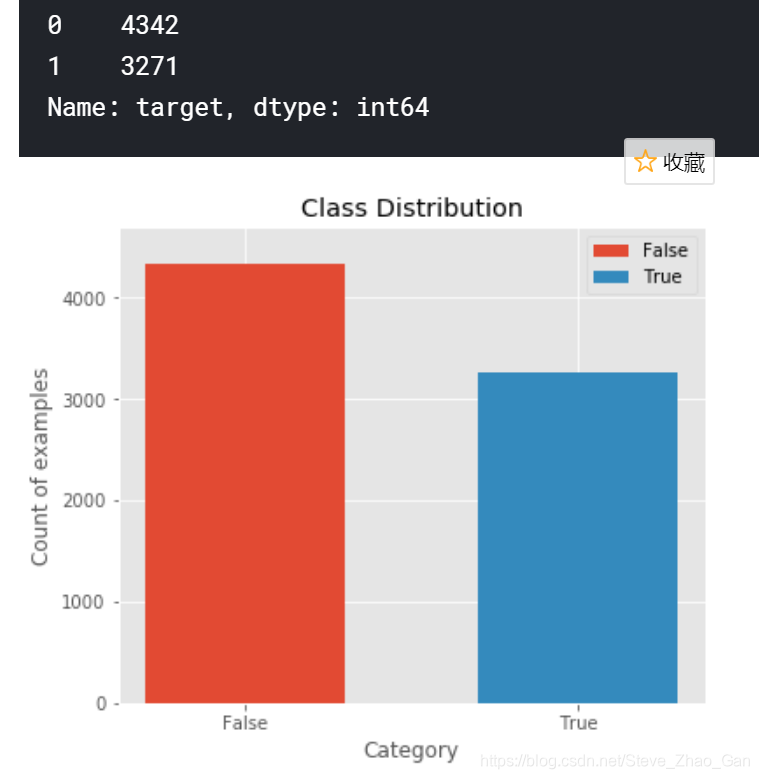
2 描述性分析
查看标签0和1的分布情况
# Frequency for taget variable
count_table = train.target.value_counts()
display(count_table)
# Plot class distribution
plt.figure(figsize=(6,5))
plt.bar('False',count_table[0],label='False',width=0.6)
plt.bar('True', count_table[1],label='True',width=0.6)
plt.legend()
plt.ylabel('Count of examples')
plt.xlabel('Category')
plt.title('Class Distribution')
plt.ylim([0,4700])
plt.show()
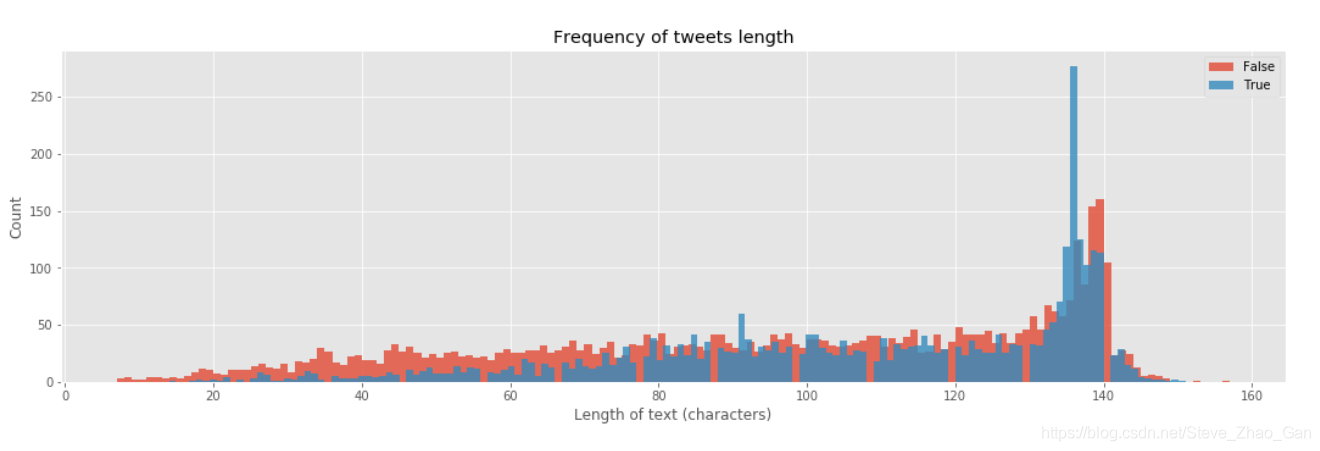
每条推特长度的分布
# Plot the frequency of tweets length
bins = 150
plt.figure(figsize=(18,5))
plt.hist(train[train['target']==0]['length'], label= 'False',bins=bins,alpha=0.8)
plt.hist(train[train['target']==1]['length'], label= 'True', bins=bins,alpha=0.8)
plt.xlabel('Length of text (characters)')
plt.ylabel('Count')
plt.title('Frequency of tweets length')
plt.legend(loc='best')
plt.show()
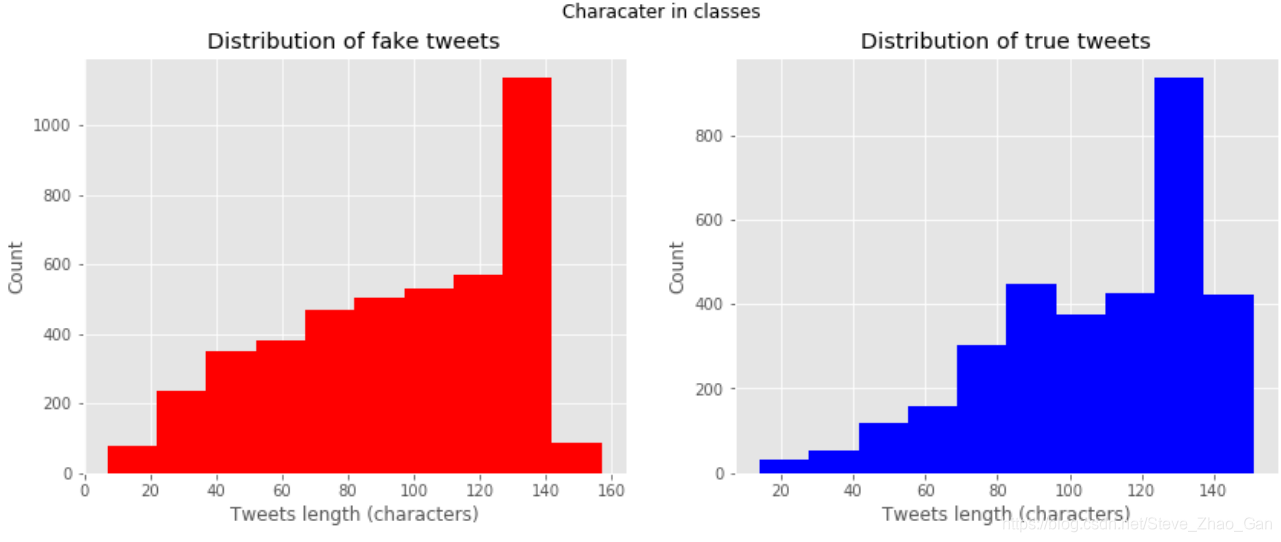
两种推特的长度分布情况对比
# Frequency of tweets length in 2 classes
fg, (ax1, ax2)=plt.subplots(1,2,figsize=(14,5))
ax1.hist(train[train['target']==0]['length'],color='red')
ax1.set_title('Distribution of fake tweets')
ax1.set_xlabel('Tweets length (characters)')
ax1.set_ylabel('Count')
ax2.hist(train[train['target']==1]['length'],color='blue')
ax2.set_title('Distribution of true tweets')
ax2.set_xlabel('Tweets length (characters)')
ax2.set_ylabel('Count')
fg.suptitle('Characater in classes')
plt.show()
两种推特出现的词的数量分布
# Plot the distribution of count of words
words_true = train[train['target']==1]['text'].str.split().apply(len)
words_false = train[train['target']==0]['text'].str.split().apply(len)
plt.figure(figsize=(10,5))
plt.hist(words_false, label='False',alpha=0.8,bins=15)
plt.hist(words_true, label='True',alpha=0.6,bins=15)
plt.legend(loc='best')
plt.title('Count of words in tweets')
plt.xlabel('Count of words')
plt.ylabel('Count')
plt.show()
3 数据清洗
定义去除所有停用词,语气符号,html符号,表情符号的函数
# Define a function to remove URL
def remove_url(text):
url = re.compile(r'https?://\S+|www\.\S+' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









