






1. (25 分)数据集的准备。
(1)使用SCIKIT-LEARN 的自带的鸢尾花数据集,获取数据集的后两个特征,形成原始数据集D。
(2)训练集与测试集的产生:
将原始数据集D 按照类别分层随机打乱,以hold-out 方式划分为训练集(80%),以及测试集(20%)
2. (25 分)模型的选择
采用单轮m-折交叉验证方式进行近邻数K 值的优选(m=4)。
以“欧式距离”为指定的距离度量方式,以“多数表决”的投票方式为决策方式。
备选K 值集合{1,2,…, 16}
(1)首先,训练集的规范化预处理,并记录预处理使用的参数。
(2)然后,对规范化的训练集的分层随机打乱, 形成m=4 个版本的估计集(小训练集)与验证集(小测试集).
(3)然后,结合上述估计集与验证集的划分,基于单轮m-折交叉验证的超参数K 的优选:
针对当前版本的验证集的每个样本,采用预设的距离度量,在估计集内找到该样本的前K 个近邻,
采用预设的决策方式,得到该样本的预测类别;将预测类别与真实类别比较,得到该验证集的预测错误
率。
最终得到不同版本估计集与验证集组合下,每个备选K 值的评价结果。
记录每个备选的K 值的预测错误率平均值与标准差,生成相应的误差曲线。曲线横轴为K 值,纵轴
为对应的错误率均值+/-标准差。
(4)最终,给出K 值的最终优选结果。
3. (25 分) K-近邻分类模型的性能评价。
基于测试集混淆矩阵的K-近邻分类模型的评价。25 分
(1)首先,构建结合训练集预处理所用的参数,对测试集的每个样本进行预处理;
(2)基于K 值优选结果(或你设定的K 值),对预处理之后的每个测试样本进行类别预测,得到所有测试样本
的类别预测结果。
(3)结合测试集各样本的类别预测结果及真实类别答案,生成混淆矩阵,并可视化混淆矩阵
(4)基于混淆矩阵,估计每个类别的查准率、查全率、F1 值,以及宏查准率、宏查全率、宏F1 值;估计总
体预测正确率.
4. (25 分) K-近邻分类模型的使用。
(1)采用训练集预处理所用的参数,对待决策样本集D1 的每个样本进行预处理,送入KNN 分类模型,进
行类别预测,得到每个样本的预测标签值;
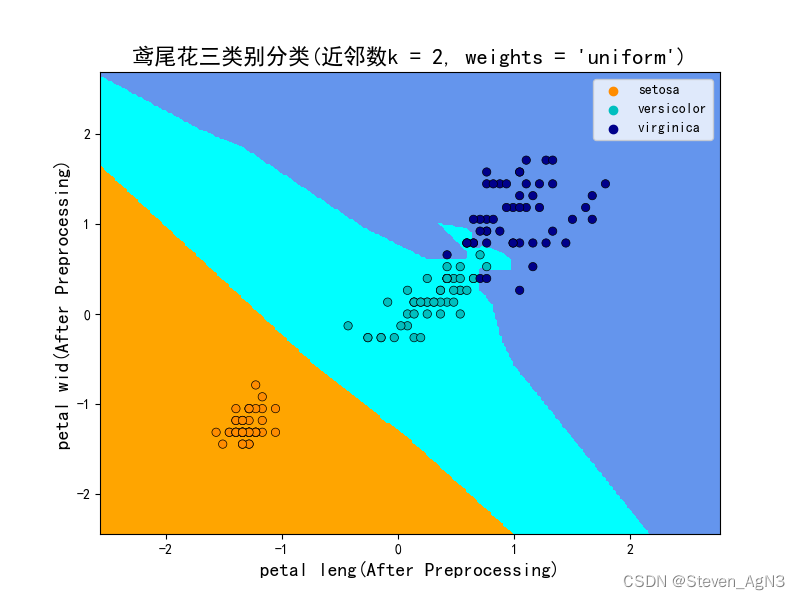
(2)结合样本分预测标签值,在原始特征空间,实现原始二维特征空间的类别划分,及可视化。
(2)待决策样本集D1 的产生:在原始二维特征空间,基于该数据集的两种特征取值的最小值、最大值,获
取该数据集的矩形包围盒,并在该的矩形区域上下左右各个方向扩充1 的基础上,以step=0.02 为两种特
征的采样间隔,在该矩形区域等间隔抽取离散位置,构成原始待决策的样本集D1。
源码如下:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# from pandas.core.common import random_state
import seaborn as sns
from matplotlib.colors import ListedColormap
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix, f1_score, accuracy_score, precision_score
from sklearn.preprocessing import StandardScaler
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
iris = load_iris() # 载入数据集
# 对原始数据集切片,保留后两个特征
X = iris.data[:, 2:4]
Y = iris.target
# 划分训练集和测试集,分层随机打乱
x_train, x_test, y_train, y_test = train_test_split(X, iris.target, train_size=0.8,
random_state=42,
shuffle=True)
# print(iris.target)
""""
以上,训练集和测试集准备完成
"""
# 数据集数据预处理、去除量纲
scaler = StandardScaler()
scaler.fit(X)
X0 = scaler.transform(X)
scaler.fit(x_train)
X0_train = scaler.transform(x_train)
X0_test = scaler.transform(x_test)
# 创建备选K值的训练模型参数, 并且添加到列表中
K_range = range(1, 17)
model_new = []
for neighbor in K_range:
model_new.append(KNeighborsClassifier(n_neighbors=neighbor, weights='uniform', metric='euclidean'))
# 用每个备选的模型在训练集中训练并计算准确率和标准差,根据默认评分方式打分并保存在scores数组中,标准差保存在std_dev数组中
scores_list = []
std_dev_list = []
for knn in model_new:
scores = cross_val_score(knn, X0_train, y_train, cv=4)
scores_list.append(scores.mean())
std_dev_list.append(np.std(scores))
# 选择评分最高的K值,
best_K = K_range[np.argmax(scores_list)]
# print("最佳K值为:", best_K)
# 绘制每个备选参数模型(错误率+/-标准差)的折线图
ER = [(1 - i) for i in scores_list] # 错误率(ER) = 1 - 精确率(Precision)
ER_add_Stddev = list(map(lambda x, y: x + y, ER, std_dev_list))
ER_line = sns.lineplot(x=[i for i in range(1, 17)], y=ER_add_Stddev)
plt.title('ErrorRate ± Standard deviation')
plt.xlabel('value of K for KNN')
plt.ylabel('mean ± SD')
plt.show()
"""
至此,模型选择和误差曲线绘制已完成
"""
# 选择最佳参数模型训练
best_model = KNeighborsClassifier(n_neighbors=best_K, weights='distance', metric='euclidean')
best_model.fit(X0_train, y_train)
# 创建一个列表以保存模型在测试集上预测出的标签值
predict_target = best_model.predict(X0_test)
# 使用sklearn中的API得到混淆矩阵
cm = confusion_matrix(y_test, predict_target)
df_cm = pd.DataFrame(cm)
# 通过热力图绘制混淆矩阵, annot = True 显示数字 ,cmap参数调整色调为紫色
ax = sns.heatmap(df_cm, annot=True, cmap="Purples")
ax.set_title('Confusion Matrix(近邻数k = %i)' % best_K) # 标题
ax.set_xlabel('predict target') # x轴标签
ax.set_ylabel('true target') # y轴标签
plt.show()
# 基于混淆矩阵,估计每个类别的查准率、查全率、F1 值,以及宏查准率、宏查全率、宏F1 值;估计总体预测正确率.
# 计算有关评价指标
print('F1值宏平均 = ', f1_score(y_test, predict_target, average='macro'))
print('F1值微平均 = ', f1_score(y_test, predict_target, average='micro'))
print('F1值加权平均 = ', f1_score(y_test, predict_target, average='weighted'))
print('所有类别的F1值 = ', f1_score(y_test, predict_target, average=None))
print('正确预测的样本数目 = ', accuracy_score(y_test, predict_target, normalize=False))
print('预测正确率 = ', accuracy_score(y_test, predict_target))
print('精度的宏平均 = ', precision_score(y_test, predict_target, average='macro'))
print('精度的微平均 = ', precision_score(y_test, predict_target, average='micro'))
print('精度的加权平均 = ', precision_score(y_test, predict_target, average='weighted'))
# 设置近邻数、设置特征空间样本采样步长
h = 0.02
# 特征空间样本集最小包围盒的确定;样本点的取样、类别预测
x_min, x_max = X0[:, 0].min() - 1, X0[:, 0].max() + 1
y_min, y_max = X0[:, 1].min() - 1, X0[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = best_model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 创建画布,基于输入空间所有取样点的预测标签对输入空间的预测结果进行颜色绘制。
cmap_light = ListedColormap(["orange", "cyan", "cornflowerblue"])
cmap_bold = ["darkorange", "c", "darkblue"]
plt.figure(figsize=(8, 6))
plt.contourf(xx, yy, Z, cmap=cmap_light) # 注意使用的颜色表
# 绘制训练样本的散点图
sns.scatterplot(
x=X0[:, 0],
y=X0[:, 1],
hue=iris.target_names[Y],
palette=cmap_bold, # 使用的颜色表
alpha=1.0,
edgecolor="black")
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("鸢尾花三类别分类(近邻数k = %i, weights = 'uniform')"
% best_K, size=16)
# 使用后数据集的后两个特征作为X, Y 轴绘图
# 模型训练和绘图所用的数据都是预处理后的去量纲数据,因此需要使用字符串切片去除iris.feature_names后的量纲
xlabel = iris.feature_names[2][:10] + '(After Preprocessing)'
ylabel = iris.feature_names[3][:9] + '(After Preprocessing)'
plt.xlabel(xlabel, size=14)
plt.ylabel(ylabel, size=14)
plt.show()
运行结果如下:
F1值宏平均 = 1.0
F1值微平均 = 1.0
F1值加权平均 = 1.0
所有类别的F1值 = [1. 1. 1.]
正确预测的样本数目 = 30
预测正确率 = 1.0
精度的宏平均 = 1.0
精度的微平均 = 1.0
精度的加权平均 = 1.0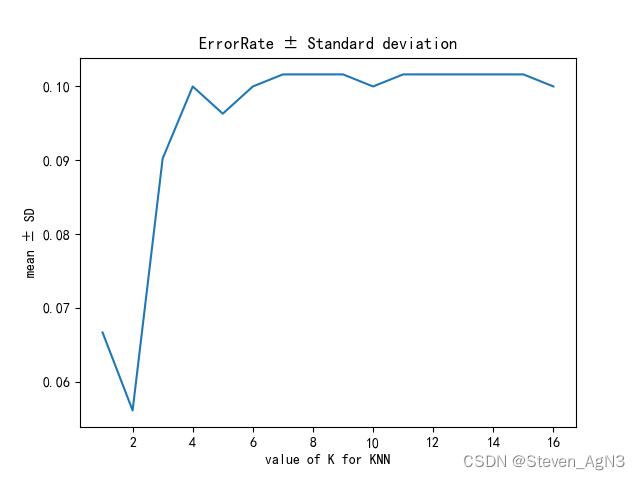
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









