







比赛网址:K-lab平台2019中国高校计算机大赛---大数据挑战赛
预选赛题
预选赛题——文本情感分类模型
本预选赛要求选手建立文本情感分类模型,选手用训练好的模型对测试集中的文本情感进行预测,判断其情感为「Negative」或者「Positive」。所提交的结果按照指定的评价指标使用在线评测数据进行评测,达到或超过规定的分数线即通过预选赛。
比赛数据
数据样本格式:
| NO | 列名 | 类型 | 字段描述 |
| 1 | ID | int | 文本唯一标识 |
| 2 | review | string | 文本记录 |
| 3 | label | string | 文本的情感状态 |
其中,训练集的样本规模为6328,测试集的样本规模为2712。
提交结果
选手提交.csv的结果文件,文件名可以自定义,但文件内的字段需要对应。其中,ID表示文本唯一标识,pred表示预测该条文本的情感状态是否为「Positive」。
结果文件的内容示例:
| ID | Pred |
| 1 | 0.123456 |
| 2 | 0.654321 |
| 3 | 0.799212 |
代码分为五部分:
导入数据、清洗数据、观察数据、建立模型、预测数据;
导入数据
首先导入包:
import re
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import string
import nltk导入数据:
i = "this"
trainTrue = pd.read_csv('E:\kLab_File\\mase\\train.csv',engine = 'python')
train = trainTrue.copy()
testTrue = pd.read_csv('E:\kLab_File\mase\\test.csv')
test = testTrue.copy()
查看导入的数据:
print(train.head(10))
可以看到,数据包含三列,ID、review和label,review包含了我们需要清理的评论内容,label是根据review判断出改评论的态度
看了头部数据之后,我们大概可以开始清理数据了,清理大概可以从下面几个方面入手:
- 我们发现label中这一列只有positive和negative两种,我们可以进行数字化,方便以后进行信息的分析和计算。
- @xxxx这个标签没有任何实际意义。
- 我们也考虑去掉标点符号,数字甚至特殊字符,他们也对区分不同的评论起不到任何作用。
- 大多数太短的词起不到什么作用,比如‘pdx’,‘his’,‘all’。所以我们也把这些词去掉。
- 执行完上述三步之后,我们就可以把每一条评论切分成独立的单词或者符号了,这在所有NLP任务中都是必须的一步。
- 在第四个数据中,有一个单词‘love’.与此同时,在余下的语料中我们可能会有更多的单词,例如loves,loving,lovable等等。这些词其实都是一个词。如果我们能把这些词都归到它们的根源上,也就是都转换成love,那么我们就可以大大降低不同单词的数量,而不会损失太多信息。
清洗数据
数据化label列,方便以后进行数据的分析
train['label'] = train['label'].replace(to_replace=['Positive', 'Negative'], value=[1, 0])
我们后面要用test进行预测,所以我们text也要进行相同的数据处理、数据清理。
删除@xxxx
下面是一个自定义的方法,用于正则匹配删除文本中不想要的内容。它需要两个参数,一个是原始文本,一个是正则规则。这个方法的返回值是原始字符串清除匹配内容后剩下的字符。在我们的实验中,我们将使用这个方法来去除@xxx标记
# 删除@
combi = train.copy()
def remove_pattern(input_txt,pattern):
r = re.findall(pattern,input_txt)
for i in r:
input_txt = re.sub(i,'',input_txt)
return input_txt
这里我推荐大家把训练集和测试集并在一起清洗,这样方便一点
combi = train.append(test, ignore_index=True)当然博主没有并在一起处理,所以对数据的每一步操作,测试集做一次处理,训练集在做一次处理。
combi['review'] = np.vectorize(remove_pattern)(combi['review'],"@[\w]*")
test['review'] = np.vectorize(remove_pattern)(test['review'],"@[\w]*")
除标点符号,数字和特殊字符
combi['review'] = combi['review'].str.replace("[^a-zA-Z#]"," ")
test['review'] = test['review'].str.replace("[^a-zA-Z#]"," ")
空格删除
把评论的空格前缀都删除
combi['review'] = combi['review'].str.strip()
统计每列数据缺失值的分布情况
print(combi.isnull().sum()) 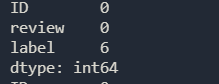
我们发现数据中有6行拥有缺失值的,由于拥有缺失值的行数比较少,所以我们选择直接删除这六行;
删除缺失值行
combi.dropna(axis=0, how='any', thresh=None, subset=None, inplace=True) #去除含有缺失值的一行
删除以后我们查看一下数据
print(combi.isnull().sum())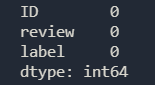
已经删除了缺失的6行
移除短单词
这里要注意到底多长的单词应该移除掉。我的选择是小于三的都去掉。例如hmm,oh,hi这样的都没啥用,删掉这些内容好一些
combi['review'] = combi['review'].apply(lambda x: ' '.join([w for w in x.split() if len(w)>3]).lower())
test['review'] = test['review'].apply(lambda x: ' '.join([w for w in x.split() if len(w)>3]).lower())
分词、符号化
tokenized_review = combi['review'].apply(lambda x: x.split())
tokenized_review_test = test['review'].apply(lambda x: x.split())
print(tokenized_review.head())
提取词干
提取词干说的是基于规则从单词中去除后缀的过程。例如,play,player,played,plays,playing都是play的变种。
from nltk.stem.porter import *
stemmer =PorterStemmer()
tokenized_review = tokenized_review.apply(lambda x: [stemmer.stem(i) for i in x]) #stemming
tokenized_review_test = tokenized_review_test.apply(lambda x: [stemmer.stem(i) for i in x]) #stemming
print(tokenized_review.head())
分词复原
把符号化的词语重新拼回去,这里我们使用最笨的方法就是遍历拼写回去;
这里在自然语言处理库nltk没有改版时时可以只用nltk的MosesDetokenizer方法很容易做到,但是更改之后官网时把nltk中的MosesDetokenizer方法删除了的,好像是为了处理兼容性的问题。
tokenized_review = tokenized_review.apply(lambda x: ' '.join([w for w in x]))
tokenized_review_test = tokenized_review_test.apply(lambda x: ' '.join([w for w in x]))
print("head2",tokenized_review.head(10))
test.to_csv('E:\kLab_File\\mase\\testtest0.1.csv',index=False)
观察数据 (其实这一步我们可以不用详细的观察,因为在此次数据处理中我们的数据都是经过脱敏的,单词非英语单词,所以句子一般读不懂。但是你也可以看一看)
- 数据集中最常见的单词有哪些?
- 数据集上表述积极和消极的常见词汇有哪些?
- 评论一般有多少主题标签?
- 我的数据集跟哪些趋势相关?
- 哪些趋势跟情绪相关?他们和情绪是吻合的吗?
使用 词云 来了解评论中最常用的词汇
现在,我想了解一下定义的情感在给定的数据集上是如何分布的。一种方法是画出词云来了解单词分布。
词云指的是一种用单词绘制的图像。出现频率越高的词在图案中越大,出现频率越低的词在图案中越小。
下面就来绘制基于我们的数据的词云图像。
总的词云:
#使用 词云 来了解评论中最常用的词汇
all_words = ' '.join([text for text in combi['review']])
from wordcloud import WordCloud
wordcloud = WordCloud(width=800, height=500, random_state=21, max_font_size=110).generate(all_words)
plt.figure(figsize=(10, 7))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis('off')
plt.show()
积极评论的词云:
# 积极数据
positive_words =' '.join([text for text in combi['review'][combi['label'] == 0]])
wordcloud = WordCloud(width=800, height=500, random_state=21, max_font_size=110).generate(positive_words)
plt.figure(figsize=(10, 7))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis('off')
plt.show()
消极评论的词云:
# 消极数据
negative_words = ' '.join([text for text in combi['review'][combi['label'] == 1]])
wordcloud = WordCloud(width=800, height=500,
random_state=21, max_font_size=110).generate(negative_words)
plt.figure(figsize=(10, 7))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis('off')
plt.show()
我们存下所有主题标签,并分成两类,一类是积极内容中的标签,一类是带有消极内容中的标签。
#love #hate 这种标签
写一个方法用来剥离标签
def hashtag_extract(x):
hashtags = []
# Loop over the words in the tweet
for i in x:
ht = re.findall(r"#(\w+)", i)
hashtags.append(ht)
return hashtags用剥离标签的方法剥离标签并放到相应的数组中;
# extracting hashtags from non racist/sexist tweets
HT_positive = hashtag_extract(combi['review'][combi['label'] == 0])
# extracting hashtags from racist/sexist tweets
HT_negative = hashtag_extract(combi['review'][combi['label'] == 1])
# unnesting list
HT_positive = sum(HT_positive,[])
HT_negative = sum(HT_negative,[])
画出标签:
# 画积极标签
a = nltk.FreqDist(HT_positive)
d = pd.DataFrame({'Hashtag': list(a.keys()),'Count': list(a.values())})
# selecting top 10 most frequent hashtags
d = d.nlargest(columns="Count", n = 10) #前十
plt.figure(figsize=(16,5))
ax = sns.barplot(data=d, x= "Hashtag", y = "Count")
ax.set(ylabel = 'Count')
plt.show()
画出消极标签
# 画消极标签
b = nltk.FreqDist(HT_negative)
e = pd.DataFrame({'Hashtag': list(b.keys()),'Count': list(b.values())})
# selecting top 10 most frequent hashtags
e = e.nlargest(columns="Count", n = 10)
plt.figure(figsize=(16,5))
ax = sns.barplot(data=e, x= "Hashtag", y = "Count")
ax.set(ylabel = 'Count')
plt.show()

建立模型
要分析清洗后的数据,就要把它们转换成特征。根据用途来说,文本特征可以使用很多种算法来转换。比如词袋模型(Bag-Of-Words),TF-IDF,word Embeddings之类的方法。
在本文中,我使用了Bag-Of-Words和TF-IDF两个方法。
词袋特征
Bag-Of-Words是一种数字化表达特征的方式。假设有一个语料集合C,其中有D篇文章(d1,d2,...dD),在C中有N个不重复的符号。那么这N个符号(即单词)构成一个列表,那么词袋模型的矩阵M的大小就是D*N.M中的每一行记录了一篇文章D(i)中对应符号的词频。
让我们用一个简单的例子来加强理解。假设我们只有两篇文章
D1: He is a lazy boy. She is also lazy.
D2: Smith is a lazy person.
构建包含所有去重单词的list
= [‘He’,’She’,’lazy’,’boy’,’Smith’,’person’]
那么,在这个语料C上,D=2,N=6
词袋模型的矩阵M的大小就是2*6

矩阵
现在,这个矩阵就可以作为特征矩阵来构建一个分类模型了。
使用sklearn的CountVectorizer方法可以轻松的构建词袋模型。
建立词袋模型
这里建议大家的磁带模型是用测试集数据和训练集数据建立的,可以增加后续的准确率。
设置参数max_features = 8200 ,只取词频前8200的词,当我去掉超过30%的无用词时,还剩下8200个。
我感觉词频越高,后面的准确度越高。所以这里打击根据自己的数据需求更改自己的max_features;
#构建词袋模型
from sklearn.feature_extraction.text import CountVectorizer
bow_vectorizer = CountVectorizer(max_df=0.30, max_features=8200, stop_words='english')
bow = bow_vectorizer.fit_transform(combi['review'])
bowtest = bow_vectorizer.fit_transform(test['review'])
print(test.describe())
print(bow.toarray())
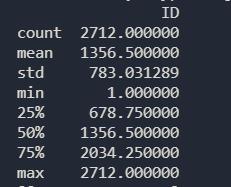
根据词袋模型运用逻辑回归来构建模型
# 逻辑回归来构建模型
# 使用词袋模型特征集合构建模型
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
train_bow = bow[:6331,:]
test_bow = bowtest[:2712,:]
print("这里",test_bow.toarray())
划分测试集合训练集,测试集占30%
xtrain_bow, xvalid_bow, ytrain, yvalid = train_test_split(train_bow, combi['label'], random_state=42, test_size=0.3)
逻辑回归
lreg = LogisticRegression()
lreg.fit(xtrain_bow, ytrain)
prediction = lreg.predict_proba(xvalid_bow) # predicting on the validation set
prediction_int = prediction[:,1] >= 0.3
prediction_int = prediction_int.astype(np.int)
print("回归f",f1_score(yvalid, prediction_int)) # calculating f1 score
![]()
F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的准确率和召回率。F1分数可以看作是模型准确率和召回率的一种加权平均,它的最大值是1,最小值是0。
这里可以通过调各种数据来提高模型的f1分数
预测数据
模型来预测测试集数据。
test_pred = lreg.predict_proba(test_bow)
print("这里P:",test_pred)
 看一下传入的test数据经过模型预测的数据;
看一下传入的test数据经过模型预测的数据;
print(test_pred.size)
test_pred_int = test_pred[:,1] //提取我们需要预测的test的label列
print(test_pred_int.size) //看看进过模型预测后的长度是否有变化
print(pd.DataFrame(test,columns=["ID"]).size) //看看原始test的数据列有多少
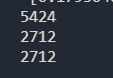 第二行和第三行要相同,不然会出现填写行数与预测行数不匹配的问题;
第二行和第三行要相同,不然会出现填写行数与预测行数不匹配的问题;
最后只剩下保存数据了
test['Pred'] = test_pred_int
submission = test[['ID','Pred']]
submission.to_csv('E:\kLab_File\\mase\\result.csv', index=False) # writing data to a CSV file


TF-IDF特征
这个方法也是基于词频的。但是它跟词袋模型还有一些区别,主要是它还考虑了一个单词在整个语料库上的情况而不是单一文章里的情况。
TF-IDF方法会对常用的单词做惩罚,降低它们的权重。同时对于某些在整个数据集上出现较少,但是在部分文章中表现较好的词给予了较高的权重。
来深入了解一下TF-IDF:
- TF = 单词t在一个文档中出现的次数 / 文档中全部单词的数目
- IDF = log(N/n),N是全部文档数目,n是单词t出现的文档数目
- TF-IDF = TF*IDF
这里我就不深入了。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









