




前言
参考:
【刷题】刷题常用STL函数整理合集_zhuhongde的博客-CSDN博客_stl常用函数
STL教程:C++ STL快速入门(非常详细) (biancheng.net)
C++ STL 教程 | 菜鸟教程 (runoob.com)
容器:
1 STL基础
STL(standard template library) ,中文可译为标准模板库或者泛型库,其包含有大量的模板类和模板函数,是 C++ 提供的一个基础模板的集合,用于完成诸如输入/输出、数学计算等功能。如今 STL 已完全被内置到支持 C++ 的编译器中,无需额外安装,STL 就位于各个 C++ 的头文件中,即它并非以二进制代码的形式提供,而是以源代码的形式提供。
C++ 标准模板库的核心包括以下三个组件:
| 组件 | 描述 |
|---|---|
| 容器(Containers) | 容器是用来管理某一类对象的集合。C++ 提供了各种不同类型的容器,比如 deque、list、vector、map 等。 |
| 算法(Algorithms) | 算法作用于容器。它们提供了执行各种操作的方式,包括对容器内容执行初始化、排序、搜索和转换等操作。 |
| 迭代器(iterators) | 迭代器用于遍历对象集合的元素。这些集合可能是容器,也可能是容器的子集。 |
其他部分:
| 组件 | 描述 |
|---|---|
| 函数对象 | 如果一个类将 () 运算符重载为成员函数,这个类就称为函数对象类,这个类的对象就是函数对象(又称仿函数)。 |
| 适配器 | 可以使一个类的接口(模板的参数)适配成用户指定的形式,从而让原本不能在一起工作的两个类工作在一起。值得一提的是,容器、迭代器和函数都有适配器。 |
| 内存分配器 | 为容器类模板提供自定义的内存申请和释放功能,由于往往只有高级用户才有改变内存分配策略的需求,因此内存分配器对于一般用户来说,并不常用。 |
2 容器
**概念:**容器是储存其他对象的对象。被储存的对象必须是同一类型。
目前,STL 中已经提供的容器主要如下:
| 容器 | 解释 |
|---|---|
| vector | 一种向量。 |
| list | 一个双向链表容器,完成了标准 C++ 数据结构中链表的所有功能。 |
| queue | 一种队列容器,完成了标准 C++ 数据结构中队列的所有功能。 |
| stack | 一种栈容器,完成了标准 C++ 数据结构中栈的所有功能。 |
| deque | 双端队列容器,完成了标准 C++ 数据结构中队列的所有功能。 |
| priority_queue | 一种按值排序的队列容器。 |
| set | 一种集合容器。 |
| multiset | 一种允许出现重复元素的集合容器。 |
| map <key, val> | 一种关联数组容器。 |
| multimap <key, val> | 一种允许出现重复 key 值的关联数组容器。 |
2.1 序列容器
常用容器: vector、deque、list、queue、stack
概念: 序列是对基本容器的一种改进,在保持其基础功能上增加一些我们需要的更为方便的功能。
要求: 序列的元素必须是严格的线性顺序排序。因此序列中的元素具有确定的顺序,可以执行将值插入到特定位置、删除特定区间等操作。
序列容器基本特征: 以下用 t 表示类型为T(储存在容器中的值的类型)的值,n表示整数,p、q、i 和 j 表示迭代器。
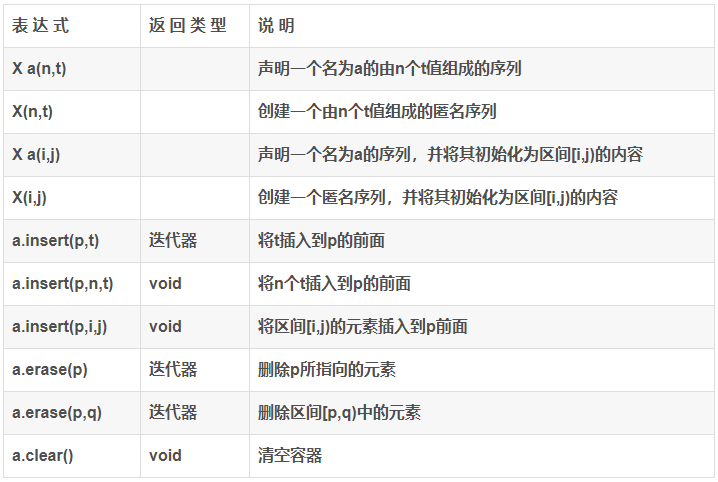
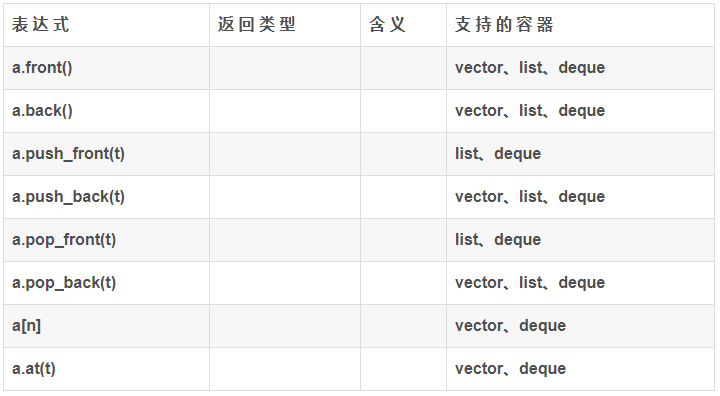
不同容器特有的特征:
【queue】队列
头文件queue,queue不允许随机访问队列元素,不允许遍历队列,可以进行队列基本操作;可以将元素添加到队尾,从队首删除元素,查看队尾和队首的值,检查元素数目和测试队列是否为空。
基本操作
queue<int> a; //声明一个空队列
a.empty() //判断队列是否为空,如果为空则返回 1,不为空则返回 0
a.size() //返回队列元素个数
a.front() //返回指向队首元素的引用
a.back() //返回指向队尾元素的引用
a.push(t) //队尾插入元素
a.pop() //删除队首元素
注:
pop() 是一个删除数据的方法,不是检索数据的方法!!!
如果要使用队列中的值,首先要使用 front() 来检索这个值,然后用 pop() 将他从队列中删除。
【deque】双端队列(double ended queue)
C++中deque是stack和queue默认的底层实现容器,deque是可以两边扩展的,而且deque里元素并不是严格的连续分布的。
头文件deque,在STL中deque类似vector,并且支持随机访问;区别在于:
- 从deque起始位置插入删除元素时间是固定的;
- 为了实现在deque俩段执行插入和删除操作的时间为固定这一目的,deque对象设计比vector设计更为复杂一些。因此,在序列中部执行插入删除操作时,vector更快一些;
基本操作
deque<int> a; //声明一个空队列
a.empty() //判断队列是否为空,如果为空则返回 1,不为空则返回 0
a.size() //返回队列元素个数
a.front() //返回指向队首元素的引用
a.back() //返回指向队尾元素的引用
a.push_front() //从队首插入
a.push_back() //从队尾插入
a.pu 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









