









前言
环境配置
查看有哪些 虚拟环境 :conda info --env
Anaconda+Pycharm环境下的PyTorch配置方法
参考
yolov3参考:
视频学习链接:
视频地址:Pytorch 搭建自己的YOLO3目标检测平台(Bubbliiiing 深度学习 教程)
博客地址:睿智的目标检测26——Pytorch搭建yolo3目标检测平台
一、yoloV3算法原理及实现
参考:
睿智的目标检测26——Pytorch搭建yolo3目标检测平台
ResNet50 、 残差网络
昇腾
yolov3 算法原理
实现代码:
darknet.pyyolo3.py

主干提取网络 Darknet53 介绍
YoloV3所使用的主干特征提取网络为Darknet53,它具有两个重要特点:
1、Darknet53具有一个重要特点是使用了残差网络Residual,Darknet53中的残差卷积就是首先进行一次卷积核大小为3X3、步长为2的卷积,该卷积会压缩输入进来的特征层的宽和高,此时我们可以获得一个特征层,我们将该特征层命名为layer。之后我们再对该特征层进行一次1X1的卷积和一次3X3的卷积,并把这个结果加上layer,此时我们便构成了残差结构。通过不断的1X1卷积和3X3卷积以及残差边的叠加,我们便大幅度的加深了网络。
残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
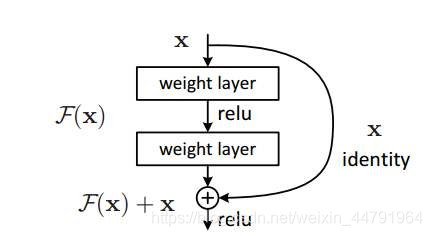
2、Darknet53的每一个卷积部分使用了特有的DarknetConv2D结构,每一次卷积的时候进行l2正则化,完成卷积后进行BatchNormalization标准化与LeakyReLU。
普通的ReLU是将所有的负值都设为零,Leaky ReLU则是给所有负值赋予一个非零斜率。以数学的方式我们可以表示为:
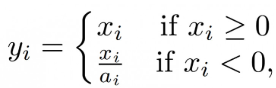
残差网络
参考:[神经网络学习小记录20——ResNet50模型的复现详解]((66条消息) 神经网络学习小记录20——ResNet50模型的复现详解_Bubbliiiing的学习小课堂-CSDN博客)
Residual net(残差网络):
将靠前若干层的某一层数据 输出直接 跳过多层 引入到后面数据层的输入部分。
意味着 后面的特征层的内容会有一部分由其前面的 某一层线性贡献。
其结构如下:
深度残差网络的设计是为了 克服由于 网络深度加深而产生的学习效率变低与准确率无法有效提升的问题。
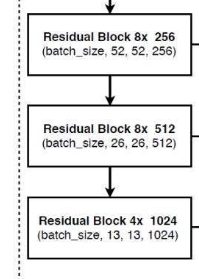
Darknet53
Darknet53 除了最开始的卷积块 Conv2D ,其他都是由残差网络构成的残差块Residual Block

PS:该图有一些小问题,宽高最小的特征层在经过Conv2D Block 5L的处理后,它的shape按照代码应该为(batch_size,13,13,512),而非图中的(batch_size,13,13,1024)。
- 主干特征提取网络:提取特征

输入是一个416x416x3——>进行下采样,宽高会不断的被压缩,在不断卷积之后 ,通道数(channel数/kernel的数目)由 3 逐渐增多,变为 1024。——>可以获得一堆特征层,用来表示输入进来图片的特征。
- 下采样:
52,52,256
26,26,512 会和 13,13,1024 层的上采样得到的特征层 进行堆叠,构建特征金字塔
13,13,1024 进行5次卷积的操作,会有两个方向的前进,即 分类预测 和 回归预测
- 路径一:分类预测 和 回归预测的结果
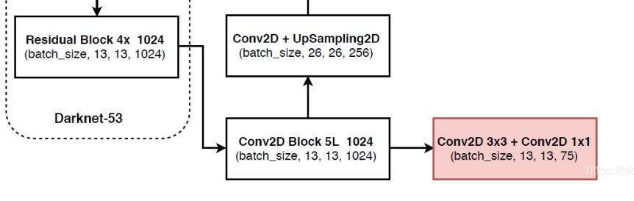
13×13×75 = 13×13×3×25 = 13×13×3×(20+1+4)
13,13(把输入的图片划分成13 × 13的网格,每个网格上面存在 3 个先验框),75 ->
13,13,3(3个先验框,它是预先标注在图片上的,用以检测物体)×25(25分为20+1+4) ->
13,13,3,20(框内部物体属于某一个类的概率,总共20个类)+1(判别是否有物体)+4(先验框的调整参数,4个参数确定一个框)
13×13×3×(20+1+4) 的理解:预测的结果判断各个网格(13)的 先验框(3)里 是否真的包含物体(1),然后判断物体的种类(20),然后对先验框进行 中心 和 宽高的调整(4),使其变成 预测框
- 路径二:卷积后上采样
上采样会使得特征层宽高得到扩张, 会和 【26,26,512】 特征层进行堆叠,该过程就是在构建特征金字塔,利用特征金字塔可以进行多尺度特征融合,提取出更有效地特征。


26,26,512 会和 13,13,1024 上采样得到的特征层进行堆叠,构建特征金字塔
然后进行5次卷积
得到:26,26,75 ——>
分解:26,26,3x25 ——> 26x26x3x(20+1+4)
26x26x3x(20+1+4)理解同路径一:13×13×3×(20+1+4)
- 路径三:
同理:

预测部分
参考:
睿智的目标检测26——Pytorch搭建yolo3目标检测平台_Bubbliiiing的学习小课堂-CSDN博客
步骤:
从特征获取预则结果
预则结果的解码
在原图上进行绘制
训练部分
计算loss所需参数
pred是什么
target是什么
loss的计算过程
其他参考
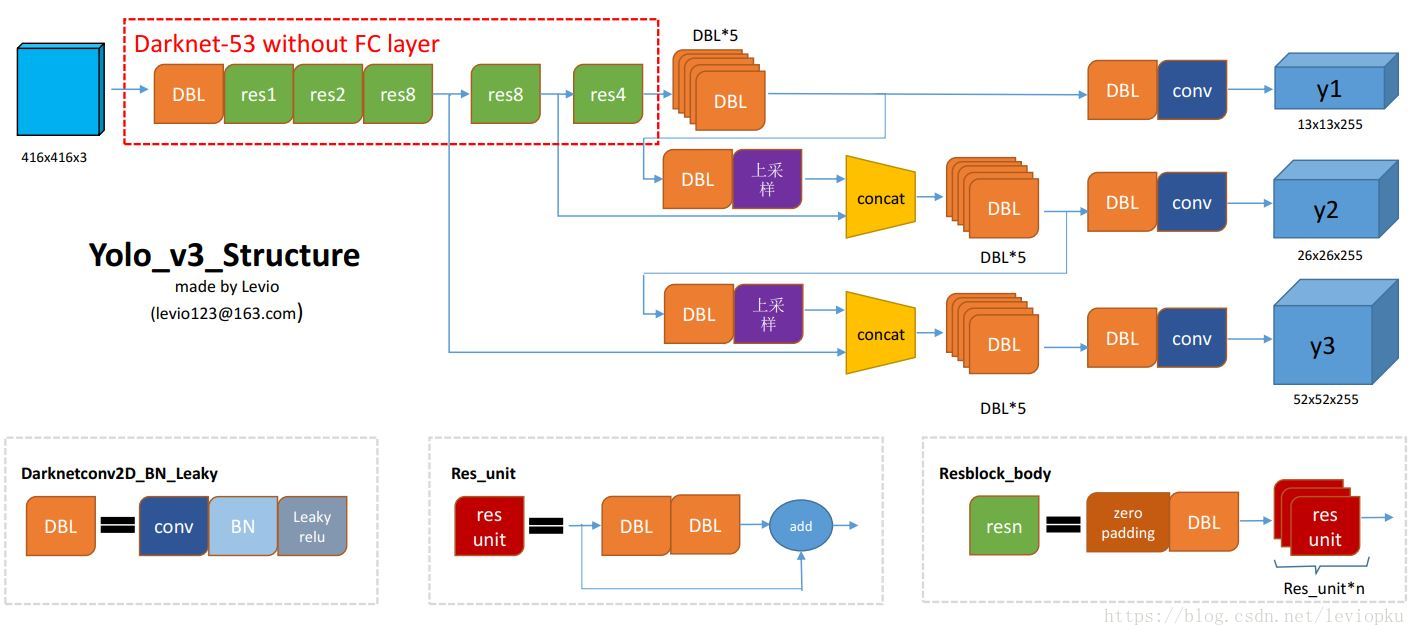
DBL: 如图1左下角所示,也就是代码中的Darknetconv2d_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu。对于v3来说,BN和leaky relu已经是和卷积层不可分离的部分了(最后一层卷积除外),共同构成了最小组件。
resn:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。这是yolo_v3的大组件,yolo_v3开始借鉴了ResNet的残差结构,使用这种结构可以让网络结构更深(从v2的darknet-19上升到v3的darknet-53,前者没有残差结构)。对于res_block的解释,可以在图1的右下角直观看到,其基本组件也是DBL。
concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
DBL
二维卷积操作(DarknetConv2D)
归一化(BatchNormalization)
非线性激活函数(LeakyReLU)
backbone
整个v3结构里面,是**没有池化层和全连接层**的(下采样层也叫池化层:池化层理解、卷积层与池化层、CNN 入门讲解:什么是全连接层)。
前向传播过程中,张量的尺寸变换是通过改变 卷积核 的步长来实现的,比如stride=(2, 2),这就等于将图像边长缩小了一半(即面积缩小到原来的1/4)。在yolo_v2中,要经历5次缩小,会将特征图缩小到原输入尺寸的1 / 2 5 1/2^51/25,即1/32。输入为416x416,则输出为13x13(416/32=13)。
yolo_v3也和v2一样,backbone都会将输出特征图缩小到输入的1/32。所以,通常都要求输入图片是32的倍数。可以对比v2和v3的backbone看看:(DarkNet-19 与 DarkNet-53)
二、YoloV4 算法原理
YOLOV4改进的部分
1、主干特征提取网络:DarkNet53 => CSPDarkNet53
2、特征金字塔:SPP,PAN
3、分类回归层:YOLOv3(未改变)
4、训练用到的小技巧:Mosaic数据增强、Label Smoothing平滑、CIOU、学习率余弦退火衰减
5、激活函数:使用Mish激活函数
主干特征提取网络Backbone
当输入是416x416时,特征结构如下:

三、YoloV4 算法程序实现
1 训练及预测步骤
训练 P10
VOC2007文件夹 和 voc2yolo4.py

Annotations 存放标签文件
JPEGimages 存放对应图片文件
ImageSets —》 train.txt 存放图片去掉后缀的名字,由
运行voc2yolo4.py程序自动生成的:

voc_annotation.py
- 修改classes为自己要检测的对象
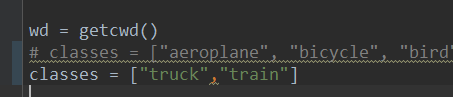
- 运行该py文件,得到:
训练的时候,只需要调用2007_train.txt,即可获取 图片 位置信息 和 图片 内部的信息。

注:文件修改路径后,2007_train.txt也要重新生成:
train.py
-
选择 输入图片尺寸:
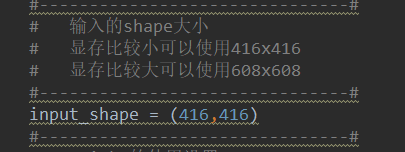
-
是否使用 余弦退火衰减
-
是否使用 mosaic 数据增强方法

- 是否使用 平滑标签
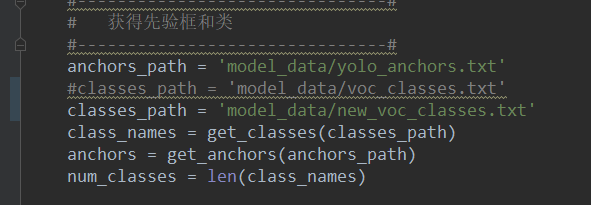
- 训练自己的 数据集 需要修改 txt文件,输入自己要检测的类。

- 预训练 模型会保存一些比较好的权重,加快训练效率

点击训练,生成.pth文件,保存至logs文件夹中
预测 P11
把训练好的文件放入 model_data文件夹
yolo.py 代码修改
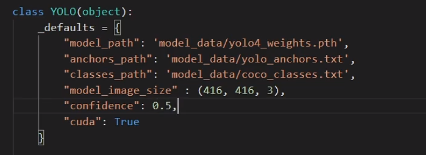
修改 model_path -----》 自己训练好的权值文件,在log文件夹中
修改classes_path -----》 要分的类,在model_data文件夹中

可以在416 与 608 之间进行修改
置信度修改
根据电脑 是否有显卡 设置 是否使用CUDA
predict.py 预测
点击运行
说明
train.py 参数说明P12
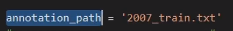

2007_train.txt 图片 绝对路径 + 目标信息


anchors_path 指向先验框,对于 yolov4 模型,总共有9个大小先验框,每个网格上默认有三个先验框
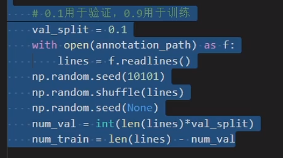
训练集和验证集划分
count_anchors P13
如何为自己的yolo模型计算合适的先验框
运行根目录kmeans_for_anchors.py,进行聚类,求先验框
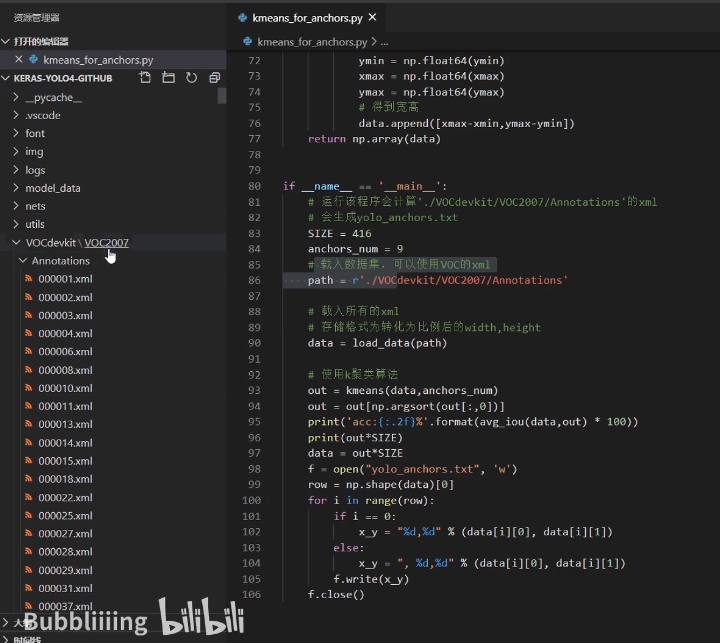
K聚类算法流程:
将框划分进9个聚类中:1 - IOU(重合程度:交的面积/并的面积) 获得 偏移程度,即 所有的框 距离这 9 个聚类中心的距离,再根据这个距离 对所有的 框 进行划分,划分成9个区域。
对 9 个区域中的框 取平均,重新作为聚类中心,进行下一轮循环,直到聚类中心 不再改变为止。
注:原始先验框 基于coco数据集,适用性很高,可以不用进行替换
马赛克数据增强 P14
睿智的目标检测28——YoloV4当中的Mosaic数据增强方法
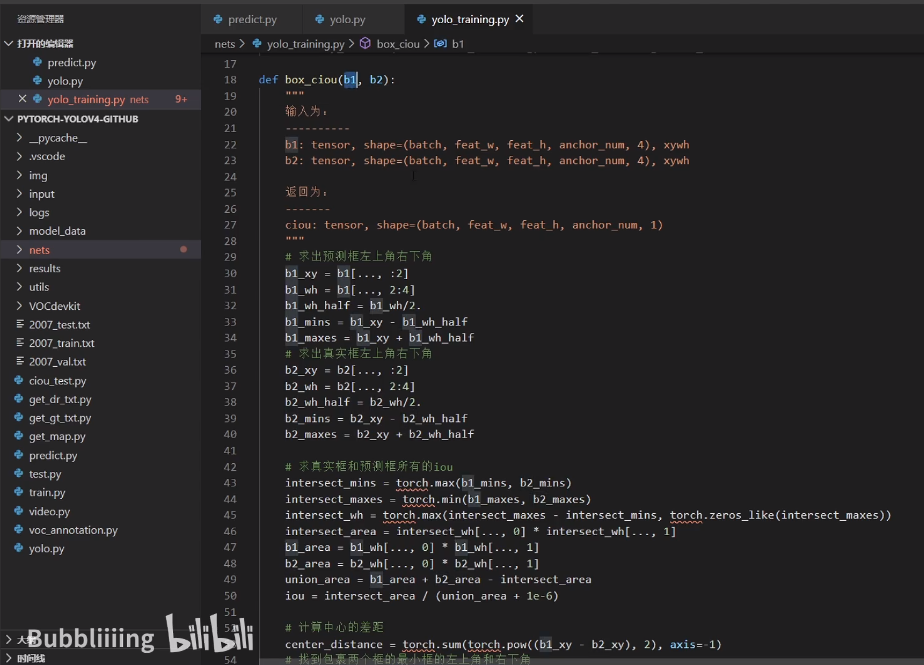
利用CIOU计算 回归损失 P15
yolo_training.py
利用 CIOU 对BBox回归损失进行优化
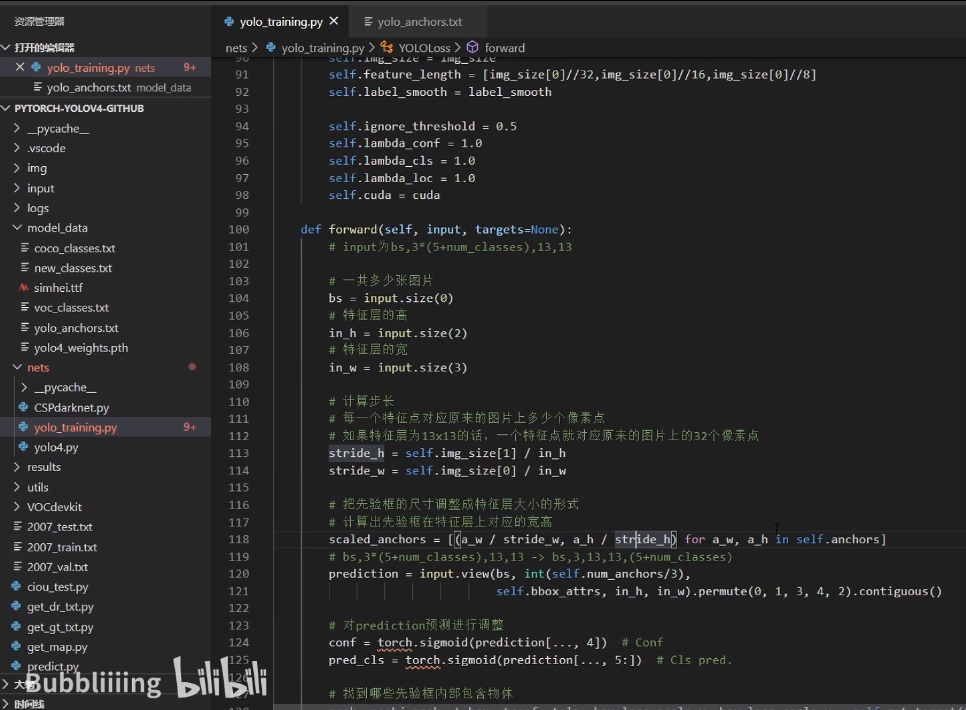
LOSS计算过程 P16
yolo_training.py
LOSS计算过程:
YOLOLoss forward

先验框中是否有物体,
先验框中物体的种类
get_target
真实框 先验框
功能:对真实框做出判断,找到对应的网格点,找到对应的先验框,帮助我们获得网络应该有的预测结果 。
get_target
功能:帮助我们找到应该忽略哪些副样本,并且获得网络的预测框。
返回 noobj_mask 副样本
pred_boxes 网络解码后的预测框
2 绘图
计算map并绘图
参考:
什么是AP
AP事实上指的是,利用不同的Precision和Recall的点的组合,画出来的曲线下面的面积。
如下面这幅图所示。
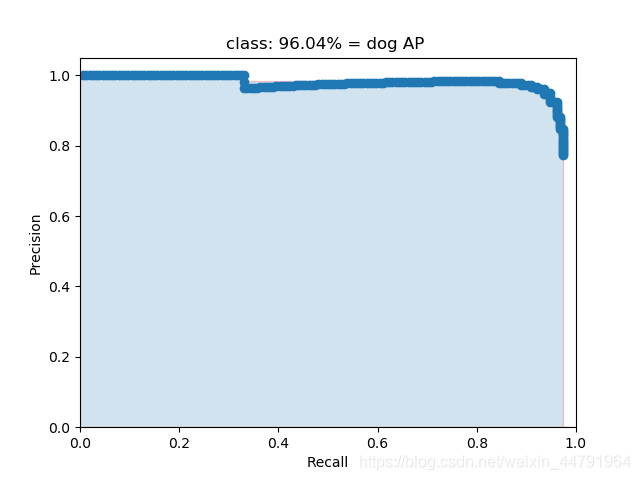
当我们取不同的置信度,可以获得不同的Precision和不同的Recall,当我们取得置信度够密集的时候,就可以获得非常多的Precision和Recall。
此时Precision和Recall可以在图片上画出一条线,这条线下部分的面积就是某个类的AP值。mAP就是所有的类的AP值求平均。
依次运行:
get_gt_txt.py detection-results:指的是预测结果的txt。
get_dr_txt.py ground-truth:指的是真实框的txt。
get_map.py
绘制loss曲线
参考:
Pytorch Tensorboard可视化工具(Bubbliiiing 深度学习 教程)_哔哩哔哩_bilibili
(75条消息) 神经网络学习小记录49——Pytorch当中Tensorboard的使用_Bubbliiiing的学习小课堂-CSDN博客
SummaryWriter()
这个函数用于创建一个tensorboard文件,其中常用参数有:
- log_dir:tensorboard文件的存放路径
- flush_secs:表示写入tensorboard文件的时间间隔
调用方式如下:
writer = SummaryWriter(log_dir='logs',flush_secs=60)
writer.add_graph()
这个函数用于在tensorboard中创建Graphs,Graphs中存放了网络结构,其中常用参数有:
- model:pytorch模型
- input_to_model:pytorch模型的输入
if Cuda:
graph_inputs = torch.from_numpy(np.random.rand(1,3,input_shape[0],input_shape[1])).type(torch.FloatTensor).cuda()
else:
graph_inputs = torch.from_numpy(np.random.rand(1,3,input_shape[0],input_shape[1])).type(torch.FloatTensor)
writer.add_graph(model, (graph_inputs,))
writer.add_scalar()
这个函数用于在tensorboard中加入loss,其中常用参数有:
-
tag:标签,如下图所示的Train_loss
-
scalar_value:标签的值
-
global_step:标签的x轴坐标

调用方式如下:writer.add_scalar('Train_loss', loss, (epoch*epoch_size + iteration))
tensorboard --logdir =
在完成tensorboard文件的生成后,可在命令行调用该文件,tensorboard网址。
具体代码如下:
tensorboard --logdir=D:\Study\Collection\Tensorboard-pytorch\logs
问题及解决方案
问题1:No module named 'past’
pip3 install future
问题2:No module named 'tensorboard.summary.writer
pip --default-timeout=100 install tensorboard==1.14.0 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
C:\ProgramData\Anaconda3\envs\python36tfgpu\lib\site-packages\tensorflow\python\framework\dtypes.py:516: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
C:\ProgramData\Anaconda3\envs\python36tfgpu\lib\site-packages\tensorflow\python\framework\dtypes.py:517: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])
C:\ProgramData\Anaconda3\envs\python36tfgpu\lib\site-packages\tensorflow\python\framework\dtypes.py:518: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])
C:\ProgramData\Anaconda3\envs\python36tfgpu\lib\site-packages\tensorflow\python\framework\dtypes.py:519: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])
C:\ProgramData\Anaconda3\envs\python36tfgpu\lib\site-packages\tensorflow\python\framework\dtypes.py:520: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])
C:\ProgramData\Anaconda3\envs\python36tfgpu\lib\site-packages\tensorflow\python\framework\dtypes.py:525: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
C:\ProgramData\Anaconda3\envs\python36tfgpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
C:\ProgramData\Anaconda3\envs\python36tfgpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])
C:\ProgramData\Anaconda3\envs\python36tfgpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])
C:\ProgramData\Anaconda3\envs\python36tfgpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])
C:\ProgramData\Anaconda3\envs\python36tfgpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])
C:\ProgramData\Anaconda3\envs\python36tfgpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
问题原因
Numpy版本过高
解决方法
安装低版本的Numpy即可。
执行 pip install numpy==1.16.4
3 相关应用
通过snap7与西门子PLC通信
安装snap7
pip install python-snap7
下载snap7的动态链接文件
四、相关问题
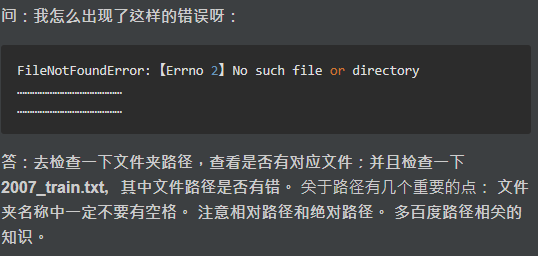
voc_annotation.py问题
AttributeError: 'NoneType' object has no attribute 'text'
(64条消息) 模型训练报错AttributeError: ‘NoneType‘ object has no attribute ‘text‘_u014479551的专栏-CSDN博客
出现了gbk什么的编码错误
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa6 in position 446: illegal multibyte sequence
答:标签和路径不要使用中文,如果一定要使用中文,请注意处理的时候编码的问题,改成打开文件的encoding方式改为utf-8。















 4874
4874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









