






在用到稀疏编码时,难免会提到以下概念:
(1)LASSO(Least Absolute Shrinkage and Selection Operatior): 最小绝对收缩选择算子。这个名词听名字比较唬人,很高大上的样子,其实本质很简单,就是给一个解向量增加一个L1范数约束,使解向量的元素尽可能稀疏(0元素越多越好)。L1范数就是一个向量的各元素的绝对值之和。
(2)近端梯度下降(Proximal Gradient Descent, PGD),也可以称为近端梯度优化:听着也很高大上。其实质就是,当一个损失函数比较复杂时,我们把这个损失函数的某个点处用泰勒公式展开为二次函数,用于拟合这个损失函数的局部区域的形状。这样,我们就可以在这个点的附近区域,通过求泰勒公式展开的二次函数的最优解来求损失函数在这个点的近邻区域的局部最优解。PGD可行的一个前提是损失函数在局部满足L-Lipschitz条件,L-Lipschitz条件将在下面被介绍。
所以,“近端”表示的是局部区域,在损失函数曲线上的一个泰勒展开点的近端/附近。
“近端梯度优化”:在损失函数曲线上的一个点的附近进行泰勒展开,通过执行梯度优化寻找局部最优解。
一个典型的图像如下所示:
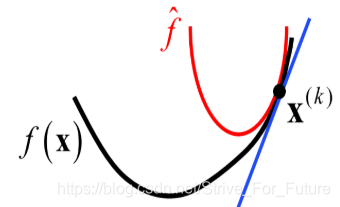
由以上可见,近端梯度优化得到的是一个局部区域的最优解,不是全局最优解。当一个函数最终是凸的的时候,我们可以通过迭代这一PGD过程,寻找到全局最优解。
为什么会在稀疏编码中用到近端梯度下降?
因为稀疏编码的损失函数中包含L1范数,L1范数是凸的但是不是处处可导(在0处不可导),因此我们无法直接用梯度下降法求解。近端梯度下降法提供了一种解决思路。
(3)软阈值(soft thresholding)
无论是软阈值(soft thresholding)还是硬阈值(hard thresholding),都是对绝对值的阈值化。软阈值化之后的得到的曲线更平滑,消除了跃变。

为什么会在稀疏编码的求解中用到软阈值?
因为:LASSO中包含L1范数,在用近端梯度下降法求解时,会遇到绝对值求导数的情况,而绝对值求导得到的是一个符号函数,所以最终会涉及到一个分情况讨论的情况,这个步骤产生了软阈值操作。



(4)迭代软阈值算法(ISTA)
稀疏编码的优化过程中要用到近端梯度下降算法,这是一个迭代优化的过程,而每一次近端梯度下降的过程中都因为L1范数求导的原因要用到软阈值分析,因此这整个过程被称为迭代软阈值算法(Iterative Shrinkage Thresholding Algorithm)(“Shrinkage 收缩” 与“soft 软”可通用?不是很清楚)。
(5)L-Lipschitz条件
L-Lipschitz条件是一个比连续平滑更强的条件,
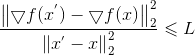
理解方式1:一个曲线上任意两点处的 导数的距离 比上这两点之间的欧式距离 有上界。
理解方式2:如果上式两端同开根号,则可以描述为 该函数的二阶导有限/有上界。
备注:关于稀疏编码求解的详细推导过程,可参考博客:LASSO回归与L1正则化 西瓜书, 写的非常详细。














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









