






前言
yolov5训练自己的数据集
一、数据集准备
labelimg下载安装
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
打标
至少50张试试,越多越好
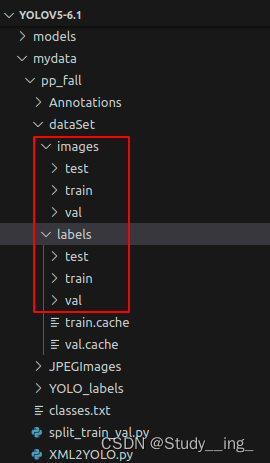
准备数据文件夹路径
二、VOC数据转yolo的txt
import os
import xml.etree.ElementTree as ET
# 定义路径
voc_annotation_path = "./Annotations"
voc_image_path = "./JPEGImages"
yolo_output_path = "./YOLO_labels"
if not os.path.exists(yolo_output_path):
os.makedirs(yolo_output_path)
# 类别列表,确保顺序与训练时的类别顺序一致
classes = ["class1", "class2", "class3"] # 替换为你的类别名称
def convert(size, box):
dw = 1. / size[0] if size[0] != 0 else 1.0 # 避免宽度为零
dh = 1. / size[1] if size[1] != 0 else 1.0 # 避免高度为零
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open(os.path.join(voc_annotation_path, f"{image_id}.xml"))
out_file = open(os.path.join(yolo_output_path, f"{image_id}.txt"), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
# 获取图像的宽度和高度,确保它们不为零
w = max(1, int(size.find('width').text)) # 最小值为1,避免宽度为零
h = max(1, int(size.find('height').text)) # 最小值为1,避免高度为零
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(f"{cls_id} " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
# 获取所有的图像ID
image_ids = [os.path.splitext(filename)[0] for filename in os.listdir(voc_annotation_path) if filename.endswith(".xml")]
for image_id in image_ids:
convert_annotation(image_id)
三、数据集自动切分
import os
import random
import shutil
# 定义路径
jpeg_images_path = "./JPEGImages"
yolo_labels_path = "./YOLO_labels"
dataset_path = "./dataSet"
# 创建总的images和labels文件夹,以及每个数据集文件夹下的images和labels子目录
def create_dataset_dirs(dataset_path):
if not os.path.exists(dataset_path):
os.makedirs(dataset_path)
os.makedirs(os.path.join(dataset_path, "images", "train"))
os.makedirs(os.path.join(dataset_path, "images", "val"))
os.makedirs(os.path.join(dataset_path, "images", "test"))
os.makedirs(os.path.join(dataset_path, "labels", "train"))
os.makedirs(os.path.join(dataset_path, "labels", "val"))
os.makedirs(os.path.join(dataset_path, "labels", "test"))
# 创建总的images和labels文件夹及其子目录
create_dataset_dirs(dataset_path)
# 设置分割比例(示例中为70%训练集,15%验证集,15%测试集)
train_ratio = 0.8
val_ratio = 0.1
test_ratio = 0.1
# 获取所有的图像文件名(假设图像和标签文件名是一一对应的)
image_files = os.listdir(jpeg_images_path)
# 打乱文件列表
random.shuffle(image_files)
# 分割数据集
num_train = int(len(image_files) * train_ratio)
num_val = int(len(image_files) * val_ratio)
num_test = len(image_files) - num_train - num_val # 剩余的为测试集
train_files = image_files[:num_train]
val_files = image_files[num_train:num_train + num_val]
test_files = image_files[num_train + num_val:]
# 复制图像和标签文件到对应目录
def copy_files(files, source_dir, dest_dir_images, dest_dir_labels):
for file in files:
file_name, file_ext = os.path.splitext(file)
# 复制图像文件
shutil.copy(os.path.join(source_dir, file), os.path.join(dest_dir_images, file))
# 复制对应的YOLO标签文件
shutil.copy(os.path.join(yolo_labels_path, file_name + ".txt"), os.path.join(dest_dir_labels, file_name + ".txt"))
# 复制训练集、验证集和测试集数据
copy_files(train_files, jpeg_images_path, os.path.join(dataset_path, "images", "train"), os.path.join(dataset_path, "labels", "train"))
copy_files(val_files, jpeg_images_path, os.path.join(dataset_path, "images", "val"), os.path.join(dataset_path, "labels", "val"))
copy_files(test_files, jpeg_images_path, os.path.join(dataset_path, "images", "test"), os.path.join(dataset_path, "labels", "test"))
print(f"Dataset split completed: {len(train_files)} train, {len(val_files)} val, {len(test_files)} test.")
四、训练准备
train.py 拉到下面,主要修改的地方
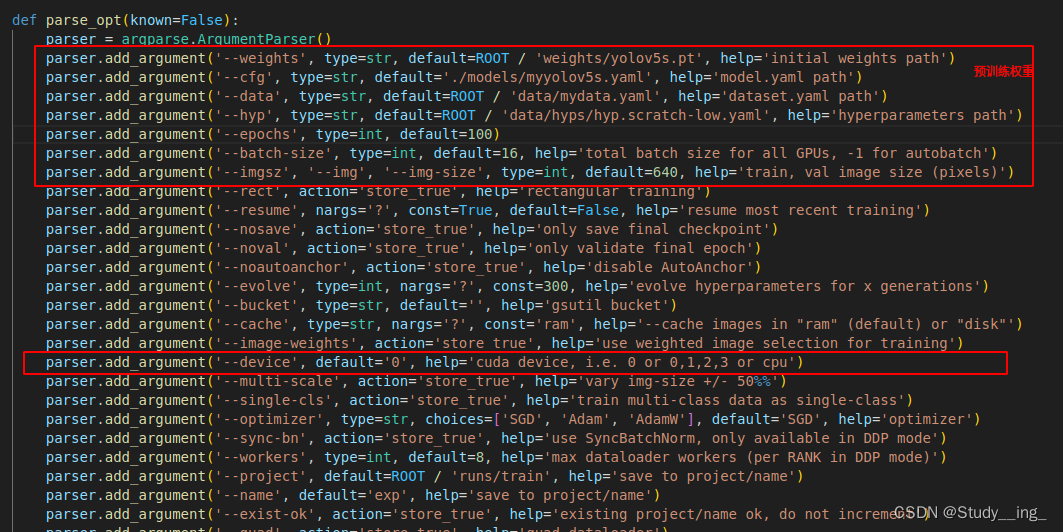
weights:权重文件路径
cfg:存储模型结构的配置文件
data:存储训练、测试数据的文件
epochs:指的就是训练过程中整个数据集将被迭代(训练)了多少次,显卡不行你就调小点。
batch-size:训练完多少张图片才进行权重更新,显卡不行就调小点。
img-size:输入图片宽高,显卡不行就调小点。
device:cuda device, i.e. 0 or 0,1,2,3 or cpu。选择使用GPU还是CPU
workers:线程数。默认是8。
权重下载
https://github.com/ultralytics/yolov5/releases/tag/v6.1
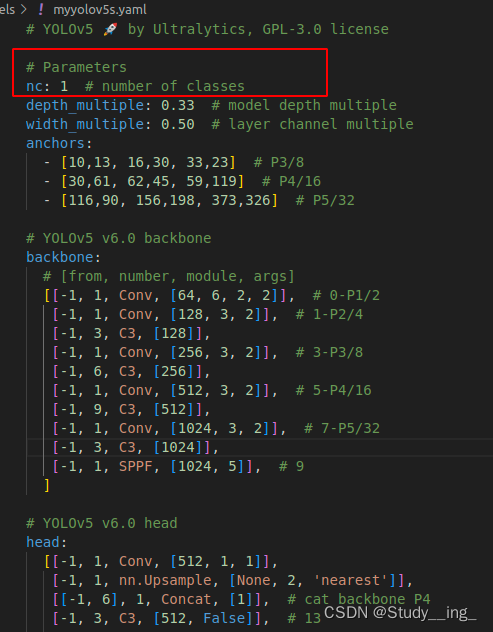
##复制一个yolov5s.yaml,只需改nc就行,类别数
##复制一个coco128.yaml
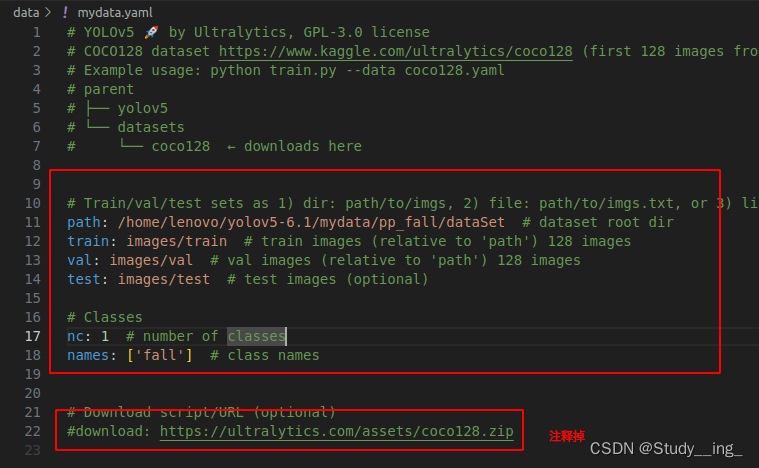
文件夹对应层级关系
运行 训练即可
python train.py
训练时可能会遇到问题
问题解决
https://blog.csdn.net/Study__ing_/article/details/139963510?spm=1001.2014.3001.5501















 27万+
27万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









