







本次学习是根据贪心科技的李文哲老师的语言模型课程所整理的相关笔记,并加上自己的理解。
-
内容包括
- 语言模型的介绍
- Chain Rule 以及马尔可夫假设
- Unigram, Bigram, Ngram
- 估计语言模型的概率
- 评估语言模型 - Perplexity
- Add-one 平滑,Add-K平滑
- Interpolation平滑
【0】语言模型(Language Model, LM)
- 概念:用来判断一个句子的合理性,即一句话在语法上是否通顺;
- 方法:通过符合语法的概率来判断;
- 常见的应用场景:拼写纠错;

【1】Chain Rule(链式法则)
- 假设一个句子s是由w1,w2,…,wT组成,则根据贝叶斯公式可得联合概率p(s)
- 定理公式:
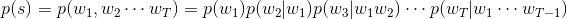
由上,一个统计语言模型可以表示成:由前面词求后一个词出现的条件概率 - 例如:s = “I want to do somethings.”
P(S) = P(i)P(want|i)P(to|i want)P(do|i want to)P(somethings|i want to do)
那么,如何求解上面的概率呢?我们很容易的想到:可以通过计算它们在语料库出现的频数比值得出概率,如P(to|i want) = count(i want to) / count(i want) - 缺点:条件概率通过语料库来进行计算;由于语料库的不足,存在稀疏性问题(存在得出的条件概率为0情况),需要通过马尔可夫假设来解决
【2】Markov Assumption(马尔可夫假设)
- 简化条件概率,只与临近的几个词有关
- 1st order、2nd order、3rd order


【3】训练和使用语言模型
- 训练
- 计算概率和条件概率的过程
- 朴素贝叶斯
- 使用
- 根据训练得到的概率,计算句子的联合概率
- Unigram
- 假设每个单词都是独立的
- 只考虑当前词
- 条件概率没有了条件,调整句子词的顺序概率不变
- 缺点:有相同词语组成的不同序列句子,概率是相同的


- Bigram
- 考虑当前词,和临近的1个词
- 解决Unigram问题


- N-gram
- 考虑当前词,和临近的N-1个词
- 缺点:存在概率为0的问题,需要通过“平滑”来解决


【4】评估语言模型 Perplexity
- Perplexity是用在NLP中,衡量语言模型好坏的指标。主要是根据每个词来 估计一句话出现的概率,并用句子长度做normalize,公式如下:
Perplexity = 2-(x), 其中 x : average log likelihood 即 x = -((1/N) * sum(logP(wi)))
* x 越大,Perplexity越小,则模型效果越好



在上图的例子中,Trigram模型是最好的。
【5】smoothing平滑
- 语料库中没有出现的词概率会变成0
- Add-one平滑
- P(wi|wi-1) = (c(wi-1, wi)+1) / (c(wi)+V)
- V是词典大小:这样,对p(wi|w0)的所有i求和是1
- 思考题:为什么是V,而不是2V或其他值
- 答:为了保证所有词概率之和为1
- Add-k平滑
- P(wi|wi-1) = (c(wi-1, wi)+k) / (c(wi)+kV)
- 思考题:k的选择?
- 答:通过Perplexity来构造关于k的损失函数,求解最优k
- interpolation平滑
- Why need this?
- 若P(a|c, d) = 0, P(b|c, d) = 0
- P(c, d, a) = P(c )P(d|c)P(a|c, d) = 0
- P(c, d, b) = P(c )P(d|c)P(b|c, d) = 0
- 概率相同,不合理
- 核心思路:计算Trigram概率时,同时考虑Unigram, Bigram, Trigram出现的频次,即三种语言模型的加权平均
- P(wi|wi-2, wi-1) =
λ
\lambda
λ1P(wi|wi-2, wi-1) +
λ
\lambda
λ2P(wi|wi-1) +
λ
\lambda
λ3P(wi)
其中: λ \lambda λ1 + λ \lambda λ2 + λ \lambda λ3 = 1

- Why need this?
- Good-Turning Smoothing
这篇基于斯坦福大学的NLP入门笔记也不错:https://blog.csdn.net/kunpen8944/article/details/83049405
总结:
基于以上方法的改进也有很多,但也不是说某个改进一定时最好的,需要我们在实践中,选择最适合的方法和模型。















 1126
1126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









