







1、移动文件
import os,shutil
srcfile='/home/tx/src'
dstfile='/home/tx/dst'
count=0
for item in os.listdir(srcfile):
count+=1
if count < 5001:
sourceFile = os.path.join(srcfile, item)
targetFile = os.path.join(dstfile, item)
shutil.move(sourceFile,targetFile) 2、numpy.squeeze(a)
从数组a的形状中删除单维条目,即把shape中为1的维度去掉。
x = np.array([[[0], [1], [2]]])
x.shape
Out[99]: (1, 3, 1)
np.squeeze(x).shape
Out[100]: (3,)3、argparse
argparse是python用于解析命令行参数和选项的标准模块,用于代替已经过时的optparse模块。argparse模块的作用是用于解析命令行参数。
使用步骤:
import argparse
parser = argparse.ArgumentParser()
parser.add_argument()
parser.parse_args()
解释:首先导入该模块;然后创建一个解析对象;然后向该对象中添加你要关注的命令行参数和选项,每一个add_argument方法对应一个你要关注的参数或选项;最后调用parse_args()方法进行解析;解析成功之后即可使用。
4、import与from import
import datetime
print(datetime.datetime.now())是引入整个datetime包
from datetime import datetime
print(datetime.now())是只引入datetime包里的datetime类
所以import之后前者是datetime这个包可见
后者是datetime.datetime这个类可见
5、上下文管理器
上下文管理器就是在对象内实现了两个方法:enter() 和exit()
enter()方法会在with的代码块执行之前执行,exit()会在代码块执行结束后执行。
exit()方法内会自带当前对象的清理方法。
class Timer:
def __init__(self, msg):
self.msg = msg
self.start_time = None
def __enter__(self):
self.start_time = time.time()
def __exit__(self, exc_type, exc_value, exc_tb):
print(self.msg % (time.time() - self.start_time))6、将对象作为数据描述符
这就是“_ get_”的作用了,将整个对象都作为数据描述符,但是请记住,要想“_ get_”作为数据描述符,那么此对象只能作为类属性,作为实例属性则无效,如下:
lass Dept(object):
def __init__(self, name):
self.name = name
# target是拥有此属性的对象
def __get__(self, target, type=None):
# 默认返回self与obj都可以
return 'Dept'
class Company(object):
# 一定要作为类属性,作为实例属性无效
dept = Dept('organ')
# 现在的测试结果
x = Company()
# 返回True
print type(x.dept) == str7、用下划线作为变量前缀和后缀指定特殊变量
_xxx 不能用’from module import *’导入
__xxx 类中的私有变量名
xxx 系统定义名字
核心风格:避免用下划线作为变量名的开头。
因为下划线对解释器有特殊的意义,而且是内建标识符所使用的符号,我们建议程序员避免用下划线作为变量名的开头。一般来讲,变量名_xxx被看作是“私有的”,在模块或类外不可以使用。当变量是私有的时候,用_xxx 来表示变量是很好的习惯。 因为变量名xxx对Python 来说有特殊含义,对于普通的变量应当避免这种命名风格。
“单下划线” 开始的成员变量叫做保护变量,意思是只有类对象和子类对象自己能访问到这些变量;
“双下划线” 开始的是私有成员,意思是只有类对象自己能访问,连子类对象也不能访问到这个数据。
以单下划线开头(如_foo)的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用“from xxx import *”而导入;以双下划线开头的(如foo)代表类的私有成员;以双下划线开头和结尾的(__foo)代表python里特殊方法专用的标识,如 init() 代表类的构造函数。
8、view()
在图像处理中的应用
当需要对输入图像三个通道进行相同的处理时,使用cv2.split和cv2.merge是相当浪费资源的,因为任何一个通道的数据对处理来说都是一样的,我们可以用view来将其转换为一维矩阵后再做处理,这要不需要额外的内存开销和时间开销。
9、float() 函数
float() 函数用于将整数和字符串转换成浮点数。
>>>float(1)
1.0
>>> float(112)
112.0
>>> float(-123.6)
-123.6
>>> float('123') # 字符串
123.010、scipy.misc 下的图像处理
from scipy.misc import imread, imresize, imsave
I = imread('./cat.jpg')
I_tinted = I * (1, .95, .9)
I_tinted = imresize(I_tinted, (300, 300))
# print(I_tinted.shape)
imsave('./figs/cat_tinted.jpg', I_tinted)imread():返回的是 numpy.ndarray 也即 numpy 下的多维数组对象;
I_tinted = imresize(I_tinted, (300, 300)),经过 imresize 操作得到的 I_tinted 仍然是 3 维的彩色信息(I_tinted.shape ⇒ (300, 300, 3))
要调整一幅图像的尺寸,可以调用 resize() 方法。该方法的参数是一个元组,用来指定新图像的大小:out = pil_im.resize((128,128))
11、Numpy数据类型转换astype,dtype
查看数据类型dtype
In [11]: arr = np.array([1,2,3,4,5])
In [12]: arr
Out[12]: array([1, 2, 3, 4, 5])
// 该命令查看数据类型
In [13]: arr.dtype
Out[13]: dtype('int64')
In [14]: float_arr = arr.astype(np.float64)
// 该命令查看数据类型
In [15]: float_arr.dtype
Out[15]: dtype('float64')转换数据类型astype
// 如果将浮点数转换为整数,则小数部分会被截断
In [7]: arr2 = np.array([1.1, 2.2, 3.3, 4.4, 5.3221])
In [8]: arr2
Out[8]: array([ 1.1, 2.2, 3.3, 4.4, 5.3221])
// 查看当前数据类型
In [9]: arr2.dtype
Out[9]: dtype('float64')
// 转换数据类型 float -> int
In [10]: arr2.astype(np.int32)
Out[10]: array([1, 2, 3, 4, 5], dtype=int32)字符串数组转换为数值型
In [4]: numeric_strings = np.array(['1.2','2.3','3.2141'], dtype=np.string_)
In [5]: numeric_strings
Out[5]: array(['1.2', '2.3', '3.2141'], dtype='|S6')
// 此处写的是float 而不是np.float64, Numpy很聪明,会将python类型映射到等价的dtype上
In [6]: numeric_strings.astype(float)
Out[6]: array([ 1.2, 2.3, 3.2141])12、np.pad()
常用与深度学习中的数据预处理,可以将numpy数组按指定的方法填充成指定的形状。
对一维数组的填充
import numpy as np
arr1D = np.array([1, 1, 2, 2, 3, 4])
'''不同的填充方法'''
print 'constant: ' + str(np.pad(arr1D, (2, 3), 'constant'))
print 'edge: ' + str(np.pad(arr1D, (2, 3), 'edge'))
print 'linear_ramp: ' + str(np.pad(arr1D, (2, 3), 'linear_ramp'))
print 'maximum: ' + str(np.pad(arr1D, (2, 3), 'maximum'))
print 'mean: ' + str(np.pad(arr1D, (2, 3), 'mean'))
print 'median: ' + str(np.pad(arr1D, (2, 3), 'median'))
print 'minimum: ' + str(np.pad(arr1D, (2, 3), 'minimum'))
print 'reflect: ' + str(np.pad(arr1D, (2, 3), 'reflect'))
print 'symmetric: ' + str(np.pad(arr1D, (2, 3), 'symmetric'))
print 'wrap: ' + str(np.pad(arr1D, (2, 3), 'wrap'))- 第一个参数是待填充数组
- 第二个参数是填充的形状,(2,3)表示前面两个,后面三个
- 第三个参数是填充的方法 填充方法:
-
constant连续一样的值填充,有关于其填充值的参数。
constant_values=(x, y)时前面用x填充,后面用y填充。缺参数是为0000。。。 - edge用边缘值填充
- linear_ramp边缘递减的填充方式
- maximum, mean, median, minimum分别用最大值、均值、中位数和最小值填充
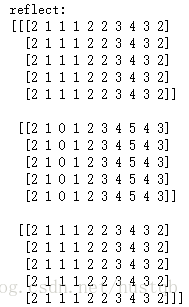
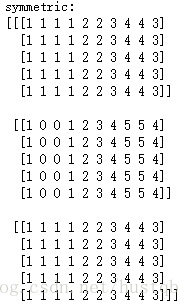
- reflect, symmetric都是对称填充。前一个是关于边缘对称,后一个是关于边缘外的空气对称╮(╯▽╰)╭
- wrap用原数组后面的值填充前面,前面的值填充后面
- 也可以有其他自定义的填充方法
 解释:
解释:
对多维数组的填充
import numpy as np
arr3D = np.array([[[1, 1, 2, 2, 3, 4], [1, 1, 2, 2, 3, 4], [1, 1, 2, 2, 3, 4]],
[[0, 1, 2, 3, 4, 5], [0, 1, 2, 3, 4, 5], [0, 1, 2, 3, 4, 5]],
[[1, 1, 2, 2, 3, 4], [1, 1, 2, 2, 3, 4], [1, 1, 2, 2, 3, 4]]])
'''对于多维数组'''
print 'constant: \n' + str(np.pad(arr3D, ((0, 0), (1, 1), (2, 2)), 'constant'))
print 'edge: \n' + str(np.pad(arr3D, ((0, 0), (1, 1), (2, 2)), 'edge'))
print 'linear_ramp: \n' + str(np.pad(arr3D, ((0, 0), (1, 1), (2, 2)), 'linear_ramp'))
print 'maximum: \n' + str(np.pad(arr3D, ((0, 0), (1, 1), (2, 2)), 'maximum'))
print 'mean: \n' + str(np.pad(arr3D, ((0, 0), (1, 1), (2, 2)), 'mean'))
print 'median: \n' + str(np.pad(arr3D, ((0, 0), (1, 1), (2, 2)), 'median'))
print 'minimum: \n' + str(np.pad(arr3D, ((0, 0), (1, 1), (2, 2)), 'minimum'))
print 'reflect: \n' + str(np.pad(arr3D, ((0, 0), (1, 1), (2, 2)), 'reflect'))
print 'symmetric: \n' + str(np.pad(arr3D, ((0, 0), (1, 1), (2, 2)), 'symmetric'))
print 'wrap: \n' + str(np.pad(arr3D, ((0, 0), (1, 1), (2, 2)), 'wrap'))





















 8482
8482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









