






写在前面:断更了几天,之前写了一篇论文的解读,发现自己对并行MOE的了解还不够深入,所以想通过查看代码来学习一下。一开始是想运行MegaBlocks项目的,但是我一直被依赖冲突困扰,长达两天,然后我选择暂时搁置,选择了Deepspeed项目。所以这一期就是记录如何部署Deepspeed项目中的MOE以及一些避坑指南,在博客中我也会讲到关于配置的问题。如果你对这个项目感兴趣,就一起来看看吧!
一. 基础知识:MOE and Megatron-DeepSpeed
首先,MoE 模型的核心思想是:它拥有海量的总参数量,但对于每一个输入 token,只有一部分(或少数几个)专家会被激活并参与计算。这使得 MoE 模型能够在不显著增加计算量的前提下,大幅提升模型容量,从而学习到更复杂的模式和表示,解锁稠密模型难以企及的规模和性能。因此,一般的单机单卡无法满足如此规模巨大的MOE训练,所有并行专家模型应运而生。
NVIDIA Megatron-DeepSpeed 框架是一个专为大规模语言模型训练而设计的综合性框架,它集成了多种先进的并行策略,包括:
- 数据并行 (Data Parallelism):将训练数据分布到多个设备上,每个设备独立计算梯度,然后进行梯度同步。
- 模型并行 (Model Parallelism):
- 张量模型并行 (Tensor Model Parallelism):在层内将模型权重分割到不同设备上,从而突破单设备内存限制。
- 流水线模型并行 (Pipeline Model Parallelism):将模型层间分割到不同设备上,实现模型层级的并行计算,减少显存占用和提高吞吐量。
- 专家并行 (Expert Parallelism):这是专为 MoE 模型设计的并行策略,它将 MoE 层中的海量专家分布到多个设备上,并通过高效的 All-to-All 通信机制确保 token 能够正确地路由到对应的专家进行计算,并最终聚合结果。
简单了解一下,具体的实现还是需要通过代码才能更加清楚,但是有关代码的讲解我想放在下一期,今天我们就先来看看如何让这个项目跑起来吧!
二. 代码获取和环境准备
pip install -r requirements.txt1. 代码获取(Megatron-DeepSpeed)
注意:之前我说过可以通过码云来作为中转站以解决网络连接问题,但是使用这种方法会出现代码克隆不完整的情况(至少在Megatron-DeepSpeed存在,你也可以试一下,可能是我的网络问题等等),所以这里我建议直接从github的官网获取,不需要配置镜像也可以克隆的。具体的代码如下:
#克隆 Megatron-DeepSpeed 仓库
git clone https://github.com/deepspeedai/Megatron-DeepSpeed.git依赖安装:
pip install -r requirements.txt2. 安装Deepspeed和依赖
pip install deepspeed这里我建议这么使用,因为你采用git cone的方法会导致版本不匹配不兼容(血泪教训)。
但是你仍然可以克隆下代码来学习是没有问题的。
#克隆DeepSpeed代码
https://github.com/deepspeedai/DeepSpeed.git当你执行pip install deepspeed时,pip会自动为你安装 DeepSpeed 及其直接的 Python 依赖,所以不需要额外安装啦!
3. 系统的完整环境
我的实验环境如下:
- 操作系统 (Ubuntu 22.04 LTS)
- GPU 型号 (NVIDIA GeForce RTX 4090 x 2)
- CUDA 版本 (CUDA 12.2)
- Python 版本 (Python 3.10)
有关anaconda的安装以及python环境的创建在第一期有详细介绍。https://blog.csdn.net/Sunine_686/article/details/148061153?spm=1001.2014.3001.5501
4. Python环境安装
无论你现在有没有python环境,我都建议你新建一个,以防止破环你原本的环境的依赖等等。所以我还是给出简要的步骤。
#创建Conda环境
conda create -n 环境名称 python=3.10
#激活环境
conda activate 环境名称
#安装 PyTorch 和 CUDA 12.1 相关包
pip install torch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 --index-url https://download.pytorch.org/whl/cu1215. CUDA安装(使用apt)
注意:如果有看过我第一期的同学,可能对我下面说得有印象:anaconda中的python环境仅与你的显卡的版本有关(也就是满足:不超过nvidia-smi 显示的 CUDA 版本,即驱动版本兼容的最高版本),并且可以不用与你的CUDA版本一致。这个话是没有问题的,而且这是对于非oot用户安装pytorch和CUDA相关库时的常用方法。但是,考虑与项目的兼容性是十分重要的。这一般会在readme、requirement.txt或者setup.py中给出,所以无论是什么项目都需要仔细阅读。
这里我之所以给出CUDA的安装是因为:在安装apex(这是一个非常麻烦的库)出现了CUDA版本不匹配的问题。错误命令如下:
RuntimeError: Cuda extensions are being compiled with a version of Cuda that does not match the version used to compile Pytorch binaries. Pytorch binaries were compiled with Cuda 12.1.正是因为apex安装的复杂性,在安装时他会去寻找你的CUDA编译器(nvcc),如果它找到的版本和需要的不一致时就会报错,所以我单独加了一个CUDA的安装过程。那我们就一起来看看吧!
- 确定Linux的发行版本
cat /etc/os-release我的Linux是Ubuntu 22.04,所以我下面的安装命令都是在这个环境下哦!你可以去官网寻找适合你的。我下面以Ubuntu 22.04 为例。

- 下载 CUDA GPG Key pin 文件
这个文件用于固定 CUDA 仓库的优先级,确保你安装的是 NVIDIA 官方的 CUDA 包。
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin- 移动 pin 文件到 apt 优先级目录
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600- 下载 CUDA 仓库 .deb 包
wget https://developer.download.nvidia.com/compute/cuda/12.1.1/local_installers/cuda-repo-ubuntu2204-12-1-local_12.1.1-530.30.02-1_amd64.deb- 等待下载完成后,安装 CUDA 仓库.deb 包
可以看到在这条命令中,我写了一个替换成自己的包名,这个名称会在你下载完成的最后输出名称的,你可以寻找一下(与我这个类似的或者一样的即可)
sudo dpkg -i cuda-repo-ubuntu2204-12-1-local_12.1.1-530.30.02-1_amd64.deb # 替换为实际的文件名- 复制仓库的 GPG Key
sudo cp /var/cuda-repo-ubuntu2204-12-1-local/cuda-*-keyring.gpg /usr/share/keyrings/- 更新 apt 包列表
sudo apt-get update- 安装 CUDA Toolkit 12.1(实际安装cuda-toolkit-12-1)
sudo apt-get -y install cuda-toolkit-12-1- 配置环境变量
vim ~/.bashrc #打开配置文件在文件末尾添加下面的代码即可:
# NVIDIA CUDA Toolkit 12.1
export PATH=/usr/local/cuda-12.1/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
export CUDA_HOME=/usr/local/cuda-12.1保存并退出。
注意:这个PAYH是你的cuda的实际安装位置,如果你按照我的步骤的话,复制即可。如果不是你可以用下面的命令查找一下:
ls -l /usr/local/看一下这个里面有没有CUDA Toolkit相关的内容。
- 使配置生效
source ~/.bashrc- 验证安装
nvcc --version输出版本号即可:

6. 制作数据集(通过借助huggingface的datasets库来获取)
- 安装datasets库(新环境很有可能没有安装哈)
# 激活你的 conda 环境(如果尚未激活)
conda activate 环境名称
# 安装 datasets 库
pip install datasets- 下载 GPT-2 词汇表和合并文件(建议走镜像)
wget https://hf-mirror.com/gpt2/resolve/main/vocab.json -O /path/to/your/cloned/Megatron-DeepSpeed/data/gpt2-vocab.json
wget https://hf-mirror.com/gpt2/resolve/main/merges.txt -O /path/to/your/cloned/Megatron-DeepSpeed/data/gpt2-merges.txt- 编写 Python 脚本来生成 JSONL 文件
创建一个脚本xxx.py ,并粘贴一下代码:
import os
from datasets import Dataset
def generate_and_save_jsonl(output_dir="/home/liuyl/Megatron-DeepSpeed/data/", num_lines=1000, text_length=2000):
"""
生成一个包含重复文本的 JSONL 文件。
Args:
output_dir (str): JSONL 文件将要保存的目录。
num_lines (int): 生成的 JSONL 文件中的行数(即文本样本数)。
text_length (int): 每个文本样本中重复字符的长度。
"""
output_filename = "huggingface_generated_data.jsonl"
output_filepath = os.path.join(output_dir, output_filename)
# 1. 创建一个简单的文本列表
# 我们将生成包含大量重复字符的文本,以确保有足够的token
# 每个字符串将是 "A" * text_length
dummy_text_content = "A" * text_length
data_list = [{"text": dummy_text_content} for _ in range(num_lines)]
print(f"将生成 {num_lines} 行数据,每行文本长度为 {text_length} 字符。")
print(f"数据示例: {data_list[0]}")
# 2. 将列表转换为 Hugging Face Dataset 对象
# from_list 方法可以从字典列表创建数据集
dataset = Dataset.from_list(data_list)
print(f"Dataset 创建成功,包含 {len(dataset)} 个样本。")
# 3. 将 Dataset 保存为 JSONL 文件
# orient="records" 确保每个字典是一个 JSON 对象
# lines=True 确保每个 JSON 对象独占一行 (JSONL 格式)
# force_ascii=False 允许非 ASCII 字符,虽然我们这里只有 'A'
dataset.to_json(output_filepath, orient="records", lines=True, force_ascii=False)
print(f"JSONL 文件已成功生成到: {output_filepath}")
print(f"请检查文件内容确保其为 JSONL 格式: head -n 5 {output_filepath}")
return output_filepath
if __name__ == "__main__":
# 调用函数生成文件
generated_file_path = generate_and_save_jsonl()
# 你可以根据需要调整 num_lines 和 text_length
# 例如:
# generated_file_path = generate_and_save_jsonl(num_lines=10000, text_length=5000)- 运行 Python 脚本生成 JSONL 文件
在你的终端中,进入Megatron-DeepSpeed的根目录,然后运行这个 Python 脚本(一行一行输入)。
cd /home/liuyl/Megatron-DeepSpeed/
python xxx.py #脚本名称这时候,在你的 Megatron-DeepSpeed/data/ 目录下会生成一个名为huggingface_generated_data.jsonl 的文件(代码中设置了)。
- 执行预处理命令
python tools/preprocess_data.py \
--input data/huggingface_generated_data.jsonl \
--output-prefix data/huggingface_generated_data \
--vocab-file data/gpt2-vocab.json \
--merge-file data/gpt2-merges.txt \
--tokenizer-type GPT2BPETokenizer \
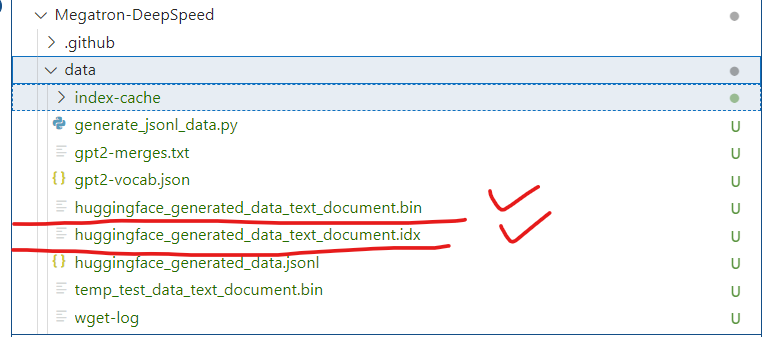
--workers 1这时候就会生成这两个文件:
- 更新 Megatron-DeepSpeed 训练脚本(以ds_pretrain_gpt_1.3B_MoE128.sh为例)
路径./Megatron-DeepSpeed/examples_deepspeed/MoE/ds_pretrain_gpt_1.3B_MoE128.sh
查找VOCAB_PATH,MERGE_PATH,DATA_BLEND并修改,有六处需要修改,各两处,修改如下:
VOCAB_PATH=/home/用户名/Megatron-DeepSpeed/data/gpt2-vocab.json #替换为gpt2-vocab.json的实际路径
MERGE_PATH=/home/用户名/Megatron-DeepSpeed/data/gpt2-merges.txt #替换为gpt2-merges.txt的实际路径
DATA_BLEND=/home/用户名/Megatron-DeepSpeed/data/huggingface_generated_data_text_document#替换为huggingface_generated_data_text_document的实际路径7. 修改配置
为什么需要修改?那肯定是因为主包的显卡不够运行他原本.sh文件中的那么大规模的模型!!!
- 模型选择:以 GPT-1.3B MoE-128 为例(路径./Megatron-DeepSpeed/examples_deepspeed/MoE/ds_pretrain_gpt_1.3B_MoE128.sh)
- 一些关键参数(ctrl+F快速定位修改即可)
#符合2张4090显卡的配置
MODEL_SIZE=0.01 #缩小模型的规模
NUM_LAYERS=4
HIDDEN_SIZE=256
NUM_ATTN_HEADS=4
GLOBAL_BATCH_SIZE=16
BATCH_SIZE=4
TRAIN_TOKENS=100000000 #减少一点Token的数目
NUM_GPUS=2 #使用 2 块 GPU 进行专家并行(因为我的是两个GPU显卡)
EP_SIZE=128 #设置一下专家的数目,这里设置为128,说明每张GPU上64个专家注意:所以的等号左右都不要有空格(别C代码写多了的习惯哈哈哈)
8. 运行脚本
在运行之前,我建议你先看一下第三章有些地方需要修改一下,不过也可以先执行,如果遇到错误再修改bug也不是不可以,很少可以一步成功!!!!
切换到相应目录
cd Megatron-DeepSpeed/examples_deepspeed/MoE执行:
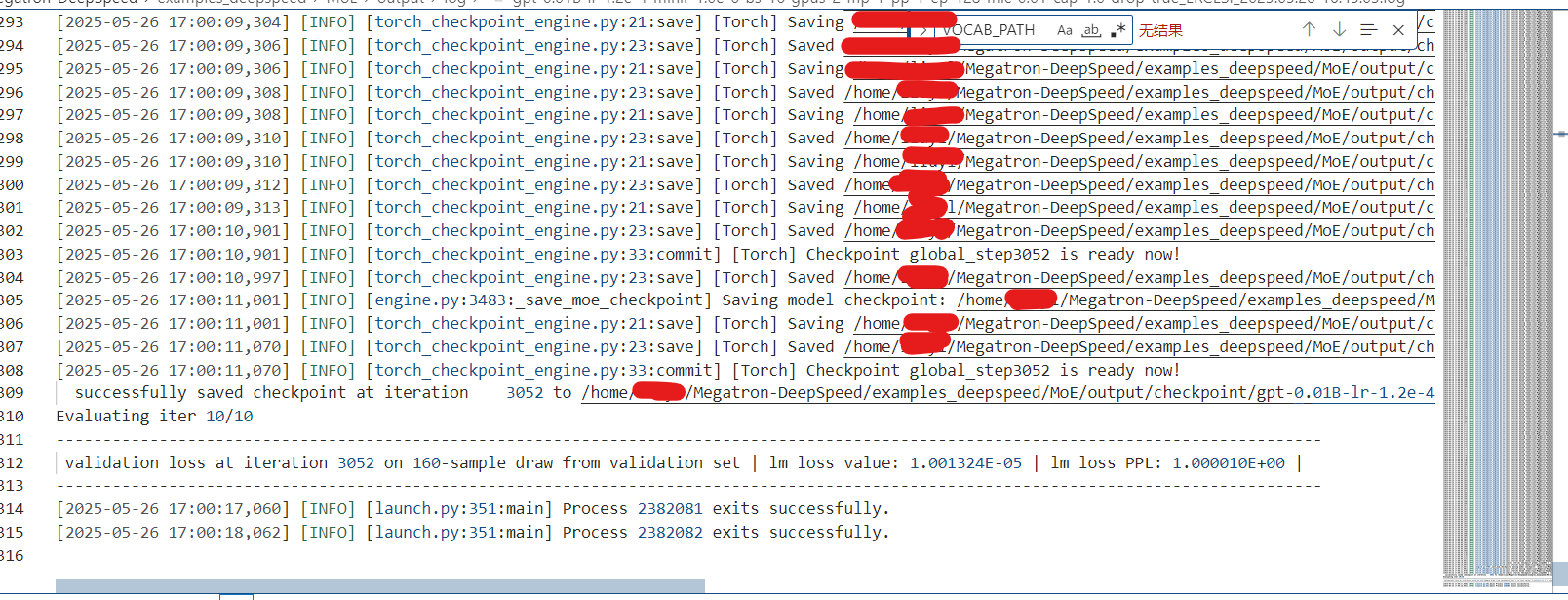
bash ds_pretrain_gpt_1.3B_MoE128.sh最终在路径 /home/用户名/Megatron-DeepSpeed/examples_deepspeed/MoE/output/log下可以找到日志输出,以供研究并行训练的过程。
三. 遇到的问题和解决方案
问题一: TyprError
- 错误现象:
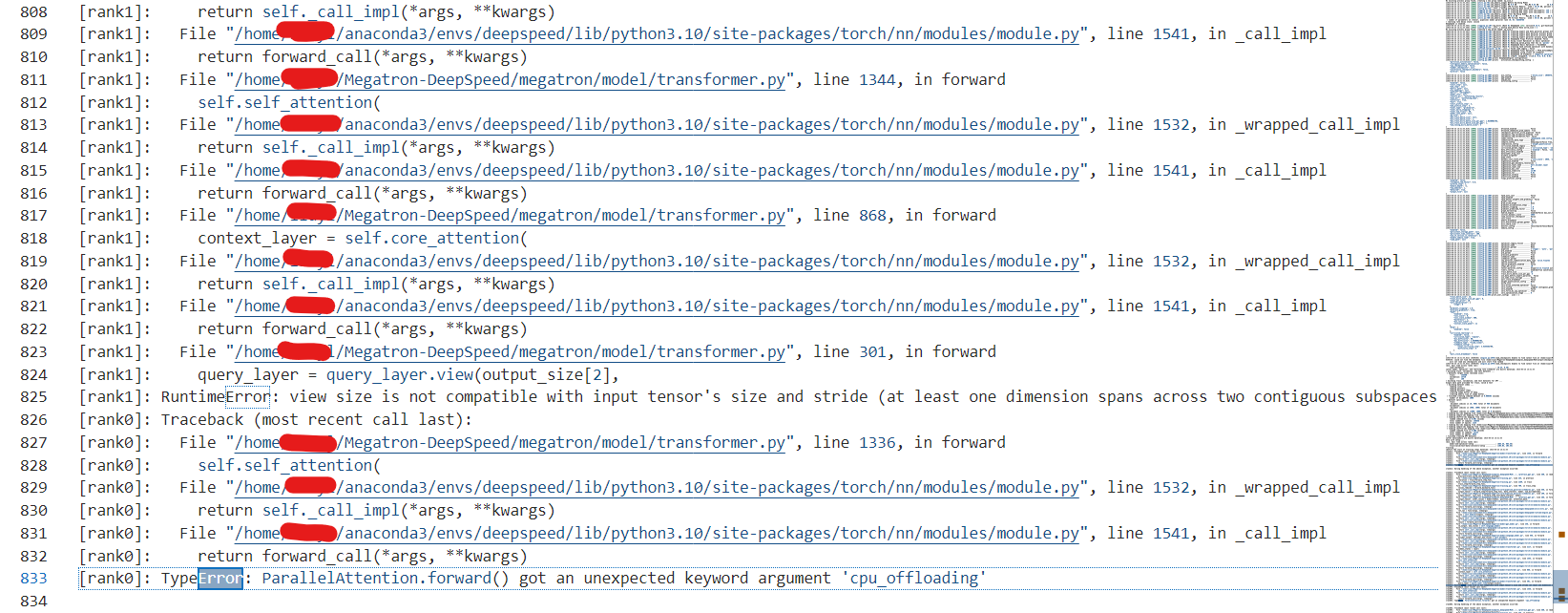
- 解决方案:直接修改transformer代码中的内容。(/home/用户名/Megatron-DeepSpeed/megatron/model/transformer.py)
在 forward 方法的参数列表中,添加 cpu_offloading=None 
问题二: RuntimeError
- 错误现象:
[rank0]: RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.-
分析:解释
torch.Tensor.view()要求张量内存连续,而permute、transpose等操作可能导致不连续。指出错误信息直接建议使用reshape()。 -
解决方案:定位到
megatron/model/transformer.py大约 301 行,将query_layer.view(...)改为query_layer.reshape(...)。(其实这里有好几处:301,304,354)。

问题三: 缺少Modul
缺少什么就pip install即可。
四. 未来展望
下期我们一起来看看并行MOE到底是什么样子滴!!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









