










1、延迟背景
业务对某个服务的延迟特别敏感,例如制定的SLO为20ms 99.99%延迟,但业务还是会偶发耗时比较高达上千ms,这种长尾问题相对严重,导致失败率也不达标,成为整体业务的关键瓶颈之一。那么如何去优化延迟呢?
2、解决思路
1)业务的代码框架问题,查看函数调用的火焰图?
2)RS主调被调之间的网络问题,抓包分析是否有丢包?
3)梳理RS所在机房的网络问题,抓包分析跨机房是否有影响?
4)容器所依赖的宿主机负载问题,监控延迟高的时间段是否高负载、流量满?
5)TCP队列:半连接syns queue、全连接qaccept queue 队列是否有溢出情况?
2.1 tcpdump抓包
# tcpdump tcp -i eth1 -s 0 -c 10000 and port ${target_port} and host ${target_host} -w /target_xxx.cap
tcpdump tcp -i eno16777736 -s 0 -c 10000 and port 22 and host 192.168.137.13 -w target_13.cap
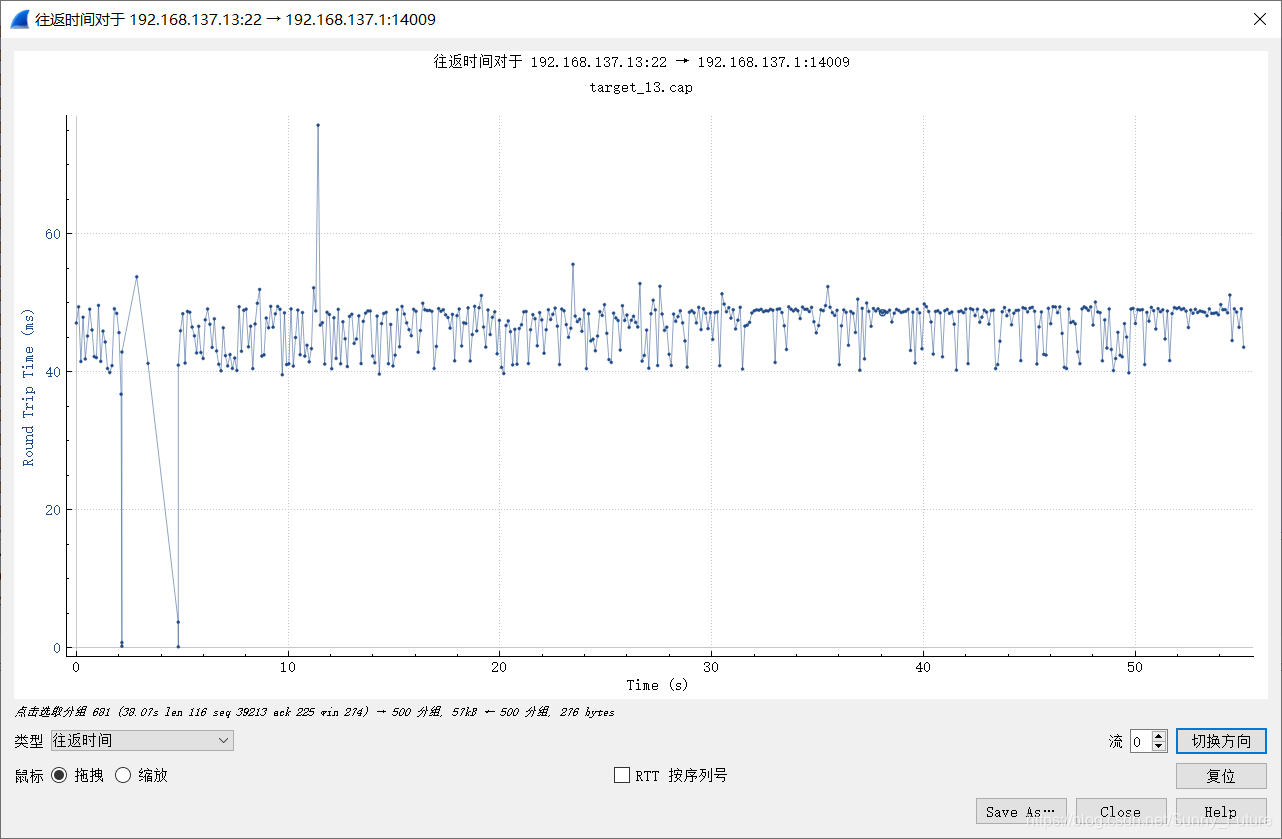
2.2 结合wireshark

















 1308
1308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









