







## 介绍 ##
van Emde Boas trees 支持所有优先级优先级队列的操作,并且巧妙的是它对于SEARCH, INSERT,DELETE,MINIMUM,MAXMUN,SUCCESSOR,和PREDECESSOR这些操作的支持都在最坏复 杂度O(lglgn)之内。不过有些限制的是,所有的Kye值都必须在 0…n−1之间,且不能有重复值。换言之,他的算法复杂度不由数据的规模 有多 大而决定,而由key值的取值范围而决定。
算导上这一章的讲述方式我非常喜欢,循序渐进,从最基础最简单的一个结构开始,最终 演化成Van Emde Boas trees,这样的方式更能让人捕捉到发明人思路发展的一个演变过 程,毫无疑问,这一章得多记点笔记。
## 基础方法 ##
这部分会有三种方法来存储动态集合,尽管它们没有一个能达到O(lglgu), 但是通过这三种方法却能让我们得到理解Van Emde Boas trees的真知灼见
## Direct Address ##
Direct Addressing提供一种最简单的方法来存储一组数据。Direct Addressing直接用 一个大小为u的位数组A[0..u−1]来存储这组属于集合{0,1,2,…,u−1}的数。如果这组数中有x,那么A[x]的值存1, 否则存0。
这种简单粗暴的方法,显然不能达到预期。对于INSERT、DELETE、MEMBER这些操作复杂 度在O(1)内。而对于MINIMUM、MAXMIMUM、SUCCESSOR、PREDECESSOR这些操作 每一个都要θ(u)。我们不妨对Direct Addressing进行改进一下。几个 θ(u)的操作皆因必须对数组进行迭代才能得到结果的缘故。那么如果我 们在Direct Addressing之上建立一棵二叉树想必有所改善。
## Superimposing a binary tree structure ##

二叉树中的结点存储着0或1,当两个孩子中有一个为1时它为1,只有当两个孩子都为0 的时候它才为0。
在Direct Addressing中花费θ(u)的操作,依赖于这棵二叉树现在都有了 一个更低的上限O(lgu)。但这个上限还并不理想,不然我们不如使用一棵 红黑树,好歹人家还是O(lgn)的上限。如果把这棵树的高度降低,说不定 是一个突破口,姑且试试。
## Superimposing a tree of constant height ##
要降低树的高度,我们可以直接通过增加树的度数来实现,将二叉树将变为多叉树。假 设全域的大小是u=22k,其中k是一个整数,那么u√ 也是一个整数。
和在位数组上建立一棵二叉树不同,现在我们在位数组上建立一棵度数为u√ 的树,如下图(a)。这棵树的高度是2。树中的每个结点存储了各子树的逻辑与结果。
如下图(b)所示,可以将那些结点看作是一个数组summary[0..u√−1],当 且仅当A[iu√..(i+1)u√−1]含1,summary[i]才为1。
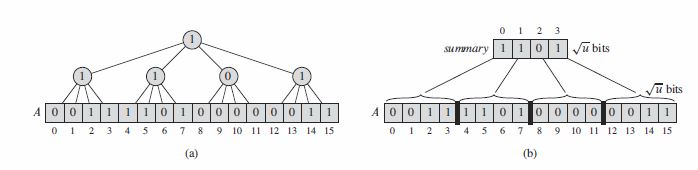
我们把A中的u√位的子数组称为簇,对于一个给定值x, 位A[x]存在于第⌊x/u√⌋个簇中。现在INSERT将在 O(1)内完成——对于插入一个x,分别将A[x]和⌊x/u√⌋设为1。对于MINIMUM、MAXIMUM、SUCCESSOR、PREDECESSOR和 DELETE这些操作将花费O(u√)。具体操作不做赘述。
比起Superimposing a binary tree,现在的结构似乎反而更糟了,前者最差劲的操作 也只要lgu,现在都要u√了,但是透过这个结构带来了一点 新的想法,如果我们把数组summary也变作一个Superimposinga tree of constant height怎么样,一路递归下去情况会如何?
## A recursive structure ##
前面用u√度数的树给了我们一个启示,假如我们能够把问题的规模以开平 方的规模缩小的话,会有一个什么效果?假设我们能做到以开平方的规模递归减小一个 数据结构的规模,而且每个操作在每一级递归上只产生一次新的递归调用,那么 对于一 个大小为u的数据结构的操作有: [ T(u) = T(\sqrt{u}) + O(1) ] 令m=lgu, 有u=2m。那么可以有: [ T(2^m) = T(2^{m/2}) + O(1)] 设S(m)=T(2m),可得新方程: [ S(m) = S(m/2) + O(1)] 可以得出S(m)=O(lgm),回到T(u)上来,那么 T(u)=T(2m)=S(m)=O(lgm)=O(lglgu)。
这个假设说明如果我们能够以递归方式以开平方的规模来缩小数据的规模大小,并在每 一级递归上花费O(1)的时间的话,我们这个假设的数据结构的操作的复杂度将 是O(lglgu)。
围绕方程 T(u)=T(u√+O(1)),我们来设计一个递归的数据结构,以开 平方的规模来减小每一次递归的大小。当然,我们可能不能一步达到让所有的操作都达 到O(lglgu),但是我们还是可以先设计出一个原型。自u起,我们 用一个u√=u1/2项的数据结构来持有u1/4项的,以 u1/4项的递归持有u1/8项的,以u1/8项的递归持有 … u=22k,如此,u1/2,u1/4,u1/8,…都为整数。
对于一个全域为{0,1,2,…u−1}的van Emde Boas数据结构为原 型,我们简称为proto-vEB(u)。它遵循以下这些规则:
如果u=2,那么已是基础大小,那么它包含两个标志位A[0…1]
否则,u=22k, 且整数k≥1, 所以u≥4, 这时,proto-vEB(u)包含两个属性:
一个名为summary指向proto-vEB(u√)的指针。
一个u√大的指针数组cluster[0…1],其中每一个指 针指向一个proto-vEB(u√)。
如果cluster的第i个指针所指向的的集合含有元素,那么i也存在于summary所指向 的集合中,否则i也不存在于summary中。
对于一个u=16的集合{2,3,4,5,7,14,15}情况就是 下面这样的:
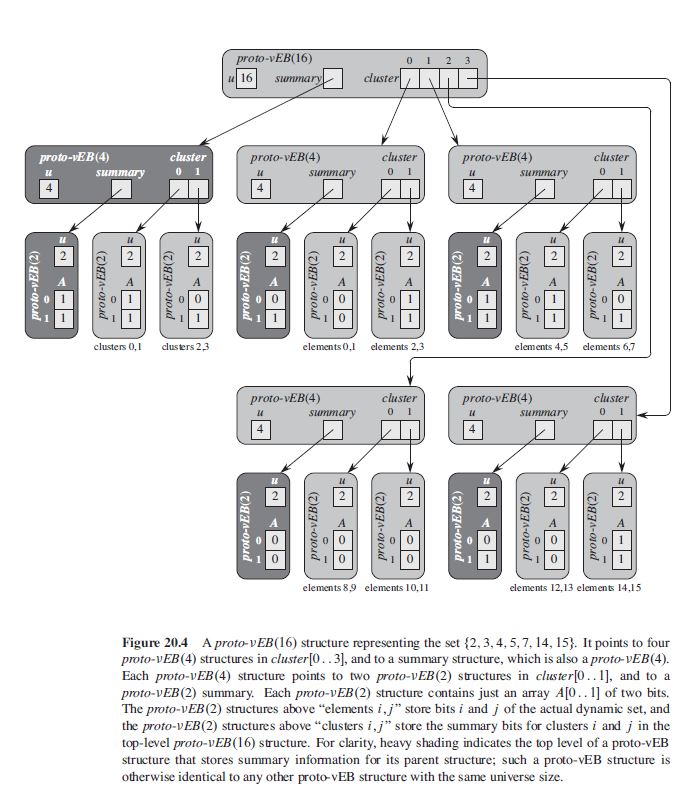
在proto-VEB(u)中,一个给定值x,那么他应该储存在proto-VEB(u)中cluster的 第⌊x/u√⌋个指针指向的proto-VEB(u√) 的第xmodu√个值。鉴于此,在分析各项操作之前,先定义几个有用 的工具函数: [ high(x) = \lfloor{x} / \sqrt{u} \rfloor ] [ low(x) = x \mod \sqrt{u} ] [ index(x, y) = x\sqrt{u} + y ]
## 判断一个值是否存在 ##
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
## 找最小值 ##
从summary中得到最小值i,那么最小值必定存在于cluster[i]所表示的集合中, 在从cluster[i]表示的集合中得到最小值,结合i值可以得到全局的最小值。伪 码:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
复杂度 [ T(u) = 2T(\sqrt u) + O(1)] 设u=2m [ T(2^m) = 2T(2^{m/2}) + O(1)] 设S(m)=T(2m),得: [S(m) = 2S(m/2) + O(1)] [T(u) = S(m) = \theta(m) = \theta(lg u)]
## 找X的后继 ##
1.从x所在的子集中找后继
2.找不到的话,先从summary中得到下一个子集的索引,从下一个子集中找最小值。
3.转换成全局的值。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
复杂度: [ T(u) = 2T(\sqrt u) + \theta(\lg{\sqrt u})] [ = 2T(\sqrt u) + \theta(\lg u)] 用与前文类似的方法可以化得T(u)=θ(lgulglgu)
## 插入元素 ##
一路向下递归插入,并将summary相应设为1即可。
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
复杂度和PROTO-VEB-MINIMUN一样 [ T(u) = 2T(\sqrt u) + O(1)] 即 θ(lgu)
## 删除元素##
相对于插入,删除要麻烦一点,因为不能直接从summary中删除元素。要确保相对应的 cluser所代表的子集不包含任何元素才能在smmary中置0。探查一个proto-VEB是否只 包含一个元素,以目前的结构可以有几种方式,但没有一种快于 θ(lgu) 的方式。也就是说PROTO-VEB-DELETE注定要超过 θ(lgu)。这儿先别急 着实现proto-VEB的删除操作,先来回顾一下,所有的基本操作我们都已经分析过一遍 了。拿最大值、最小值很慢,拿前驱、后继很慢,插入删除也要比预期的慢,似乎除 了MEMBER操作,所有的操作都很慢,但是仔细分析发现,找前驱慢是因为取最小值太 慢了,找后继慢是因为取最大值太慢了。插入慢是因为要额外对summary执行一次插入, 删除慢是因为对这个结构的判空慢,实际上插入和删除慢是因为同一个问题,没法快 速知道一个proto-VEB的尺寸和极限值。归根结底,这些操作慢的症结在于,没法快速 知道最大值最小值,因为知道最大值最小值以后,尺寸便能在θ(1)之内得 到了。既然如此,我们不如直接将最大值,最小值直接记录在proto-VEB的结构中。 Van Emde Boas Trees的最终模型就得到了,给proto-VEB添加记录最大值和最小值的 两个属性。
The van Emde Boas tree
先约定,将van Emde Boas tree简称为vEb。
在给proto-VEB加上min和max两个属性之前,还得有一个问题要解决,proto-VEB 要求 u=22k,这个要求显然有点太过苛刻了,现在我们把这个范围放宽到 u=2k。放宽要面对的第一个问题就是u√不一定是整数了,解决的 办法便是,我们的规模不再要求以开平方的规模来缩小了,而是以接近开平方的规模缩 小,简言之,原来将proto-VEB(u)分解为u√个proto-VEB(u√), 现在则是将vEB(u)分解成⌈(lgu)/2⌉个 vEB(⌊(lgu)/2⌋)。直观起见,将 ⌈(lgu)/2⌉用u√↑表示,将 ⌊(lgu)/2⌋以u√↓表示, u=u√↑⋅u√↓.
相较于proto-VEB结构上有以下两个变化:
增加min和max两个属性
对于u=2的VEB来说,不需要数组A[0..1]了,因为min和max足以来 记录两个值。
对于u>2的VEB来说,min不储存在任何一个cluster中,但是max值要, 为什么这么做,可以让在空集合中插入元素和删除集合中唯一元素的操作都为 O(1)。
重新定义一下几个方法: [high(x) = \lfloor x / \sqrt[\downarrow] u \rfloor] [low(x) = x \mod \sqrt[\downarrow] u] [index(x, y) = x \sqrt[\uparrow] u + y]















 1670
1670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









