






基于CNN的船只目标检测
一、目的
完成本学期所学课程《神经网络与深度学习》的课程设计,同时发现CSDN上没找到相关的博文,本来想偷个懒,本着天下文章大家抄的思想糊弄一下这个,最后还是老老实实自己做这个小项目了。
博客最后会以网盘链接的形式给大家分享源码和数据集!!!
二、整体大纲
主要工作内容包括以下几个方面:
1、数据收集与预处理:收集包含船只目标的图像数据集,并进行预处理,包括图像增强、尺寸统一化、数据划分等,为后续的训练和测试做准备。
2、模型设计与训练:基于CNN的船只目标检测模型的设计,包括卷积层、池化层、全连接层等结构的搭建。使用收集到的图像数据集进行模型的训练,通过反向传播算法优化模型参数,使其能够准确地检测船只目标。
3、模型评估与调优:对训练得到的模型进行评估和调优,使用测试数据集进行性能评估,包括准确率、召回率、精确率等指标。根据评估结果对模型进行调优,以提高其检测性能和泛化能力。
4、实验和结果分析:进行实验验证,使用真实的船只图像数据进行目标检测,对检测结果进行分析和评价。通过对比实验和结果分析,评估所提出方法的有效性和优势,并对其应用场景和潜在问题进行讨论。
三、数据集获取
数据集名称:
《shipnet.json》
数据简介:
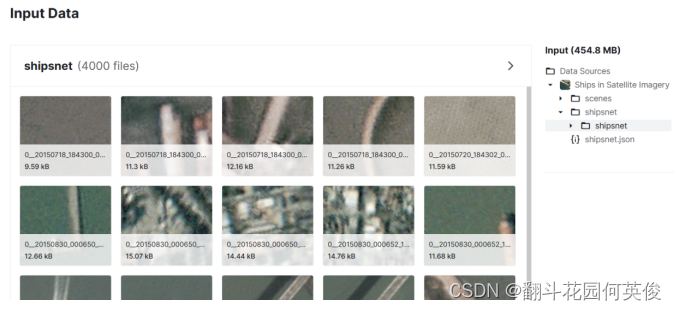
如上图所示,ship数据集包含4000张图片,每张图片的分辨率为80x80, 其中图片中有船只的有3000张,没有船只的图片有1000张,总大小在455MB左右。
此外为了方便处理,该数据集可转换为json形式,即将每张图片的RGB值以及相关信息的存储。
四、模型搭建
(一)网络结构
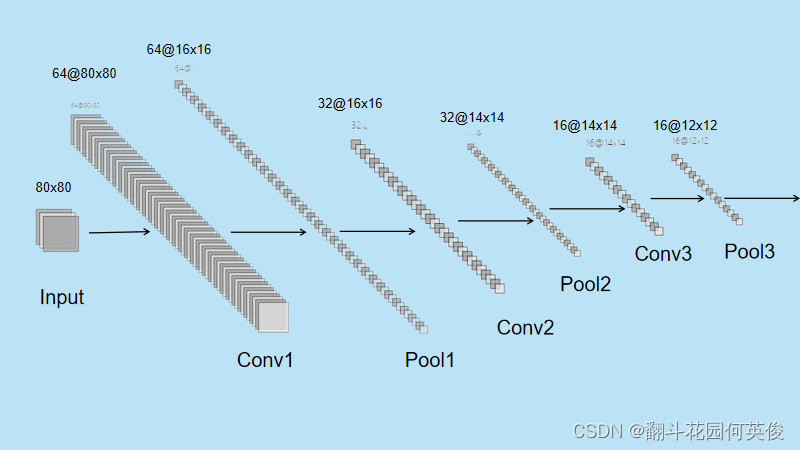
C1层 (卷积层):
·过滤器数量 (filters): 64
·卷积核大小 (kernel_size): (4, 4)
·填充方式 (padding): ‘Same’
·激活函数 (activation): ‘relu’
·输入形状 (input_shape): (80, 80, 3)
·输出大小: (80, 80, 64)
池化层 (MaxPool2D):
·池化窗口大小 (pool_size): (5, 5)
·默认步幅 (strides): 与池化窗口大小相同
·输出大小: (16, 16, 64)
Dropout层:
·丢弃率 (dropout rate): 0.25
·输出大小: (16, 16, 64)
C2层 (卷积层):
·过滤器数量 (filters): 32
·卷积核大小 (kernel_size): (3, 3)
·填充方式 (padding): ‘Same’
·激活函数 (activation): ‘relu’
·输出大小: (16, 16, 32)
池化层 (MaxPool2D):
·池化窗口大小 (pool_size): (3, 3)
·步幅 (strides): (1, 1)
·输出大小: (14, 14, 32)
Dropout层:
·丢弃率 (dropout rate): 0.25
·输出大小: (14, 14, 32)
C3层 (卷积层):
·过滤器数量 (filters): 16
·卷积核大小 (kernel_size): (2, 2)
·填充方式 (padding): ‘Same’
·激活函数 (activation): ‘relu’
·输出大小: (14, 14, 16)
池化层 (MaxPool2D):
·池化窗口大小 (pool_size): (3, 3)
·步幅 (strides): (1, 1)
·输出大小: (12, 12, 16)
Dropout层:
·丢弃率 (dropout rate): 0.25
·输出大小: (12, 12, 16)
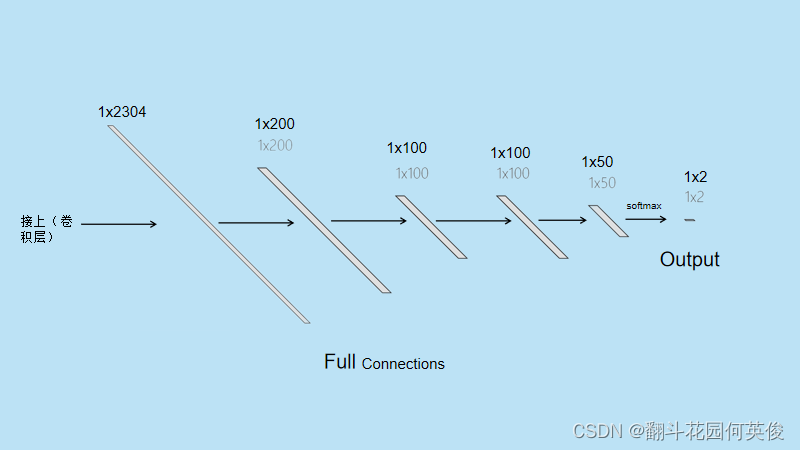
Flatten层:
·用于将多维输入展平为一维向量,12x12x16=2304个神经元
FC1层 (全连接层):
·神经元数量: 200
·激活函数: “relu”
·丢弃率 (dropout rate): 0.5
FC2层 (全连接层):
·神经元数量: 100
·激活函数: “relu”
·丢弃率 (dropout rate): 0.5
FC3层 (全连接层):
·神经元数量: 100
·激活函数: “relu”
·丢弃率 (dropout rate): 0.5
FC4层 (全连接层):
·神经元数量: 50
·激活函数: “relu”
·丢弃率 (dropout rate): 0.5
Softmax层 (全连接层):
·神经元数量: 2
·激活函数: “softmax”
(二)运行结果
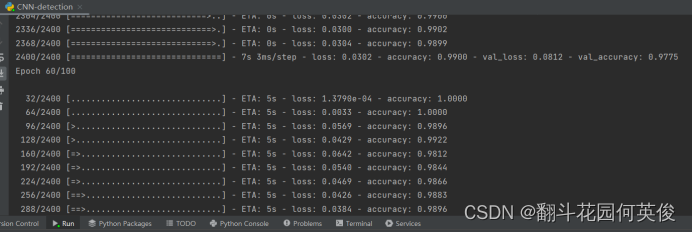
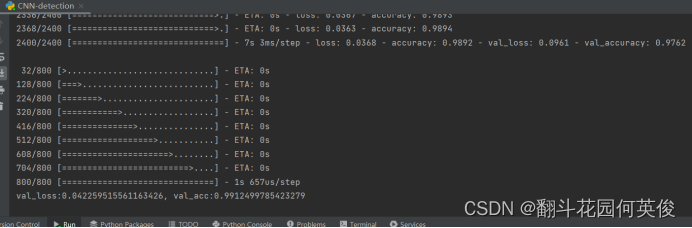
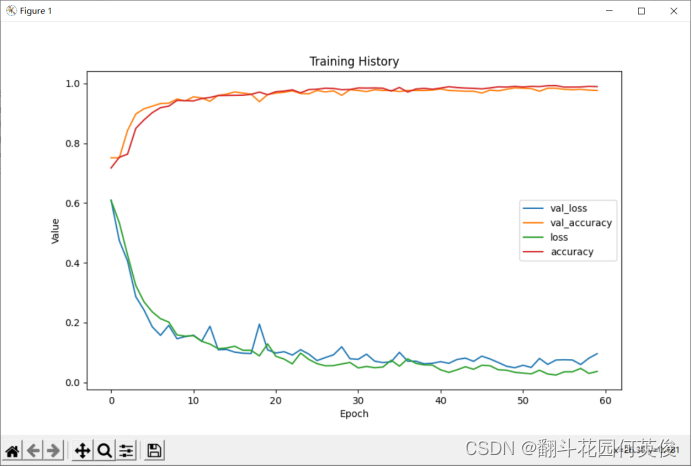
简单分析一下:
实验结果显示模型训练了60次达到了提前停止的条件,模型在训练集上的损失较小,准确率能达到98.92%接近100%,而在验证集上的损失较大,准确率也比训练集低,然而在测试集上的准确率能达到99%。Loss和accuracy可视化图可以看出,loss刚开始的下降幅度很快,然后小范围震荡,最后趋近平稳。
Accuracy最开始能达到70%多。经过短暂的几轮训练可以快速爬升到90%以上,然后速度降低,小幅度波动,最后平稳。训练集与测试集上的loss和accuracy曲线几乎一致。
五、模型优化
模型的优化可以从以下几个方面考虑
(一)优化器
模型优化在优化器选择上参考了吴恩达老师在斯坦福《深度学习》网络在线课程的建议。Adam优化器结合了动量优化和自适应学习率的特性,它在很多深度学习任务中表现出色,并被广泛使用。
(二)损失函数
至于损失函数选择交叉熵损失函数是符合多分类任务需求的,目前还想不到更好的损失函数。
(三)正则化
权重衰减
我给Adam优化器的权重值设为0.9和0.999,当然你可以尝试给它再添加个衰减参数值decay=0.9这样的。
提前停止
实验中我使用了Keras中的EarlyStopping回调函数,用于在训练过程中实现提前停止。指定监测的指标是验证集的损失函数,在连续patience=10轮训练中没有改善就终止进程。
丢弃法(Dropout)
使用Dropout随机丢弃一部分神经元来避免过拟合,当然dropout rate是可以自己定的。
当然还有很多其他的优化方法,我就不再赘述。有兴趣的可以自己去尝试和摸索!















 6904
6904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









