






CIFAR10为数据集,该数据集共有10个分类。整个项目的处理步骤如下。
1)导入需要的库。包括与PyTorch相关的库(torch),与数据处理相关的库(如torchvision)、与张量操作方面的库(如einops)等。
2)对数据进行预处理。使用torchvision导入数据集CIFAR10,然后对数据集进行正则化、剪辑等操作,提升数据质量。
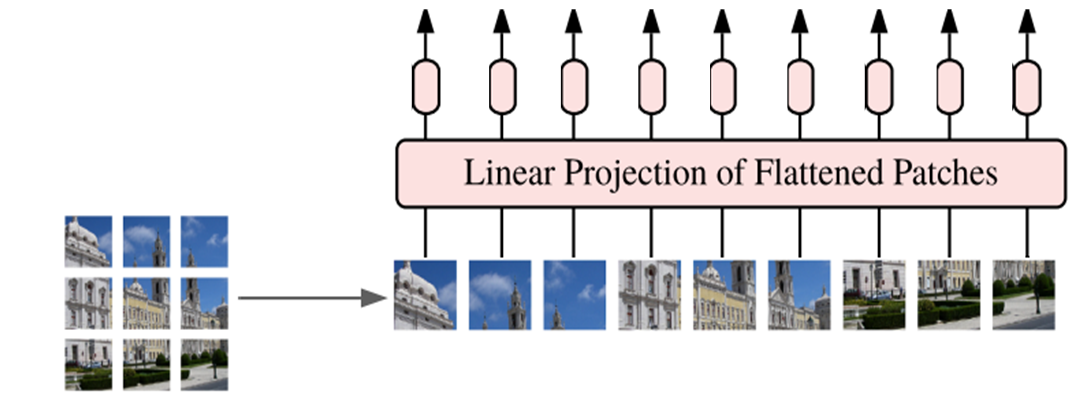
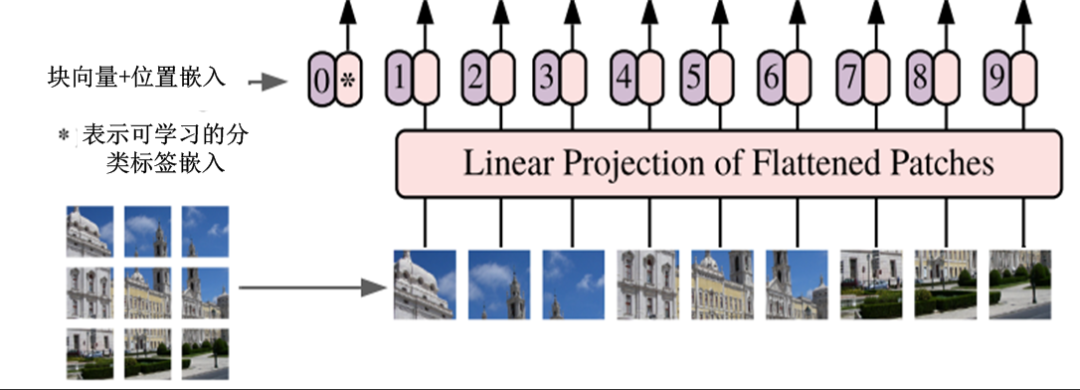
3)生成模型的输入数据。把预处理后的数据向量化,并加上位置嵌入、分类标志等信息,生成模型的输入数据。
4)构建模型。这里主要使用Transformer架构中编码器(Encoder),构建模型。
5)训练模型。定义损失函数,选择优化器,实例化模型,通过多次迭代训练模型。
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import torchvision
import torchvision.transforms as transforms
from torch import nn
from torch import Tensor
from PIL import Image
from torchvision.transforms import Compose, Resize, ToTensor
from einops import rearrange, reduce, repeat
from einops.layers.torch import Rearrange, Reduce
# 对训练数据实现数据增强方法,以便提升模型的泛化能力.
train_transform = transforms.Compose([transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop((32,32),scale=(0.8,1.0),ratio=(0.9,1.1)),
transforms.ToTensor(),
transforms.Normalize([0.49139968, 0.48215841, 0.44653091], [0.24703223, 0.24348513, 0.26158784])
])
test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize([0.49139968, 0.48215841, 0.44653091], [0.24703223, 0.24348513, 0.26158784])
])
trainset = torchvision.datasets.CIFAR10(root='../data/', train=True, download=False, transform=train_transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, drop_last=True, pin_memory=True, num_workers=4)
testset = torchvision.datasets.CIFAR10(root='../data', train=False,download=False, transform=test_transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, drop_last=False, num_workers=4)
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 随机可视化4张图片
NUM_IMAGES = 4
CIFAR_images = torch.stack([trainset[idx][0] for idx in range(NUM_IMAGES)], dim=0)
img_grid = torchvision.utils.make_grid(CIFAR_images, nrow=4, normalize=True, pad_value=0.9)
img_grid = img_grid.permute(1, 2, 0)
plt.figure(figsize=(8,8))
plt.title("Image examples of the CIFAR10 dataset")
plt.imshow(img_grid)
plt.axis('off')
plt.show()
plt.close()
class PatchEmbedding(nn.Module):
def __init__(self, in_channels = 3, patch_size = 4, emb_size = 256):
self.patch_size = patch_size
super().__init__()
self.projection = nn.Sequential(
# 在s1 x s2切片中分解图像并将其平面化
Rearrange('b c (h s1) (w s2) -> b (h w) (s1 s2 c)', s1=patch_size, s2=patch_size),
nn.Linear(patch_size * patch_size * in_channels, emb_size)
)
def forward(self, x):
x = self.projection(x)
return x
class PatchEmbedding(nn.Module):
def __init__(self, in_channels= 3, patch_size= 4, emb_size= 256):
self.patch_size = patch_size
super().__init__()
self.proj = nn.Sequential(
# 用卷积层代替线性层->性能提升
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e'),
)
self.cls_token = nn.Parameter(torch.randn(1,1, emb_size))
def forward(self, x):
b, _, _, _ = x.shape
x = self.proj(x)
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b)
# 在输入前添加cls标记
x = torch.cat([cls_tokens, x], dim=1)
return x
class PatchEmbedding(nn.Module):
def __init__(self, in_channels= 3, patch_size= 4, emb_size= 256, img_size= 32):
self.patch_size = patch_size
super().__init__()
self.projection = nn.Sequential(
# 用卷积层代替线性层->性能提升
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e'),
)
self.cls_token = nn.Parameter(torch.randn(1,1, emb_size))
self.positions = nn.Parameter(torch.randn((img_size // patch_size) **2 + 1, emb_size))
def forward(self, x):
b, _, _, _ = x.shape
x = self.projection(x)
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b)
# 在输入前添加cls标记
x = torch.cat([cls_tokens, x], dim=1)
# 加位置嵌入
x += self.positions
return x
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size = 256, num_heads = 8, dropout = 0):
super().__init__()
self.emb_size = emb_size
self.num_heads = num_heads
# 将查询、键和值融合到一个矩阵中
self.qkv = nn.Linear(emb_size, emb_size * 3)
self.att_drop = nn.Dropout(dropout)
self.projection = nn.Linear(emb_size, emb_size)
def forward(self, x , mask = None):
# 分割num_heads中的键、查询和值
qkv = rearrange(self.qkv(x), "b n (h d qkv) -> (qkv) b h n d", h=self.num_heads, qkv=3)
queries, keys, values = qkv[0], qkv[1], qkv[2]
# 最后一个轴上求和
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys) # batch, num_heads, query_len, key_len
if mask is not None:
fill_value = torch.finfo(torch.float32).min
energy.mask_fill(~mask, fill_value)
scaling = self.emb_size ** (1/2)
att = F.softmax(energy, dim=-1) / scaling
att = self.att_drop(att)
# 在第三个轴上求和
out = torch.einsum('bhal, bhlv -> bhav ', att, values)
out = rearrange(out, "b h n d -> b n (h d)")
out = self.projection(out)
return out
class ResidualAdd(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
res = x
x = self.fn(x, **kwargs)
x += res
return x
class FeedForwardBlock(nn.Sequential):
def __init__(self, emb_size=256, expansion= 4, drop_p= 0.):
super().__init__(
nn.Linear(emb_size, expansion * emb_size),
nn.GELU(),
nn.Dropout(drop_p),
nn.Linear(expansion * emb_size, emb_size),
)
class TransformerEncoderBlock(nn.Sequential):
def __init__(self,
emb_size= 256,
drop_p = 0.,
forward_expansion = 4,
forward_drop_p = 0.,
** kwargs):
super().__init__(
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
MultiHeadAttention(emb_size, **kwargs),
nn.Dropout(drop_p)
)),
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
FeedForwardBlock(
emb_size, expansion=forward_expansion, drop_p=forward_drop_p),
nn.Dropout(drop_p)
)
))
class TransformerEncoder(nn.Sequential):
def __init__(self, depth: int = 12, **kwargs):
super().__init__(*[TransformerEncoderBlock(**kwargs) for _ in range(depth)])
class ClassificationHead(nn.Sequential):
def __init__(self, emb_size= 256, n_classes = 10):
super().__init__(
Reduce('b n e -> b e', reduction='mean'),
nn.LayerNorm(emb_size),
nn.Linear(emb_size, n_classes))
class ViT(nn.Sequential):
def __init__(self,
in_channels = 3,
patch_size = 4,
emb_size = 256,
img_size = 32,
depth = 12,
n_classes = 10,
**kwargs):
super().__init__(
PatchEmbedding(in_channels, patch_size, emb_size, img_size),
TransformerEncoder(depth, emb_size=emb_size, **kwargs),
ClassificationHead(emb_size, n_classes)
)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
vit = ViT()
vit=vit.to(device)
import torch.optim as optim
LR=0.001
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(vit.parameters(), lr=0.001)
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 获取训练数据
#print(i)
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# 权重参数梯度清零
optimizer.zero_grad()
# 正向及反向传播
outputs = vit(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 显示损失值
running_loss += loss.item()
if i % 100 == 99: # print every 100 mini-batches
print('[%d, %5d] loss: %.3f' %(epoch + 1, i + 1, running_loss / 100))
running_loss = 0.0
print('Finished Training')

















 6127
6127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









