







 本文介绍了决策树的基本概念,重点解析了熵、条件熵和信息增益的定义及其关系。阐述了ID3算法的工作原理,并指出其对连续特征处理的不足以及可能产生的过拟合问题。同时提到了决策树的损失函数通常采用正则化的极大似然函数。
本文介绍了决策树的基本概念,重点解析了熵、条件熵和信息增益的定义及其关系。阐述了ID3算法的工作原理,并指出其对连续特征处理的不足以及可能产生的过拟合问题。同时提到了决策树的损失函数通常采用正则化的极大似然函数。
树模型是机器学习中非常常用的一种算法,既可以处理分类问题,也可以处理回归问题,更多的时候是用来处理分类问题的,下面就主要介绍有关于决策树的一些内容.
简介
- 决策树
- 熵
- 条件熵
- 信息增益
- 决策树的算法
- ID3算法
- 损失函数
一.决策树
定义: 是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果,本质是一颗由多个判断节点组成的树。
决策树的优点:
(1)具有可读性,如果给定一个模型,那么过呢据所产生的决策树很容易推理出相应的逻辑表达。
(2)分类速度快,能在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
决策树的缺点:
(1)对未知的测试数据未必有好的分类、泛化能力,即可能发生过拟合现象,此时可采用剪枝或随机森林。
1.熵
熵(entropy)是随机变量不确定性的度量,也就是熵越大,则随机变量的不确定性越大。设X是一个取有限个值得离散随机变量,则随机变量X的熵定义为:
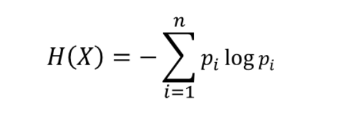
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1195
1195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









