









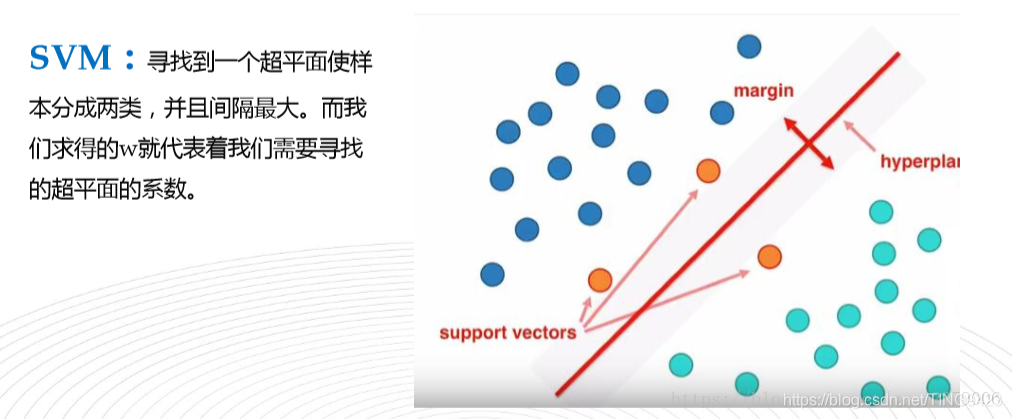
支持向量机:
随机森林
由整个样本集随机取出M个子集,并将这些子集生成M个决策树,将新数据投入到这M个决策树中,得到M个结果,计数看哪一类的结果最多。并将这一结果作为最后结果。随机森林是如何缓解决策树的过拟合问题,又能提高精度的呢?
a. Random Forest, 本质上是多个算法平等的聚集在一起。每个单个的决策树,都是随机生成的训练集(行),随机生成的特征集(列),来进行训练而得到的。
b. 随机性的引入使得随机森林不容易陷入过拟合,具有很好的抗噪能力,有效的缓解了单棵决策树的过拟合问题。
c. 每一颗决策树训练样本是随机的有样本的放回抽样。
K近邻算法
给一个新的数据时,离它最近的 k 个点中,哪个类别多,这个数据就属于哪一类。
逻辑回归算法
K表示K个邻居,不表示距离,因为需要求所有邻居的距离,所以效率低下。
优点:可以用来填充缺失值,可以处理非线性问题
调优方法:K值的选择,k值太小,容易过拟合
朴素贝叶斯
通过特征的描述,来判断事物的类别。它经常用于文本分析,例如判断垃圾邮件等。它们使用用户输入的类标记数据来比较新数据并对其进行适当分类。
决策树
根据一些 feature(特征) 进行分类,每个节点提一个问题,通过判断,将数据分为两类,再继续提问。这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的问题,将数据划分到合适的叶子上。
K均值算法
先确定常数K,k意味着最终聚类的类别数;
先选出K个初始值,将剩下的样本分到距离最近的类中
再重新选出每个类中的质点,重新分类,直到每个类中的值不再变化
Adaboost
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器。使用adaboost分类器可以排除一些不必要的训练数据特征,并放在关键的训练数据上面。
过程分析
该算法其实是一个简单的弱分类算法提升过程,这个过程通过不断的训练,可以提高对数据的分类能力。整个过程如下所示:
- 先通过对N个训练样本的学习得到第一个弱分类器;
- 将分错的样本和其他的新数据一起构成一个新的N个的训练样本,通过对这个样本的学习得到第二个弱分类器 ;
- 将1和2都分错了的样本加上其他的新样本构成另一个新的N个的训练样本,通过对这个样本的学习得到第三个弱分类器;
- 最终经过提升的强分类器。即某个数据被分为哪一类要由各分类器权值决定
马尔代夫
第一,s1,s2,s3,…是一个马尔可夫链,也就是说,si只由si-1决定(详见系列一);
第二,第i时刻的接收信号oi只由发送信号si决定(又称为独立输出假设,即P(o1,o2,o3,…|s1,s2,s3…)=P(o1|s1)*P(o2|s2)P(o3|s3)…。
那么人们就可以很容易利用算法Viterbi找出上面式子的最大值,进而找出要识别的句子s1,s2,s3,…。
神经网络
input输入到网络中,被激活,计算的分数被传递到下一层,激活后面的神经层,最后output层的节点上的分数代表属于各类的分数,
人工神经网络算法基于生物神经网络的结构,深度学习采用神经网络模型并对其进行更新。它们是大、且极其复杂的神经网络,使用少量的标记数据和更多的未标记数据。神经网络和深度学习有许多输入,它们经过几个隐藏层后才产生一个或多个输出。这些连接形成一个特定的循环,模仿人脑处理信息和建立逻辑连接的方式。此外,随着算法的运行,隐藏层往往变得更小、更细微。














 212
212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









