






基于Pyspark的大众点评数据分析和可视化项目
一、项目简介
在当今数据驱动的时代,大数据分析已经成为商业决策的重要依据。本项目旨在利用Pyspark这一强大的大数据处理工具,对从大众点评收集的商家数据进行深度分析和可视化。通过处理大规模数据集,揭示商家运营的关键趋势,为决策者提供数据驱动的洞察,助力商家优化策略,提升顾客满意度。
二、数据概述
本项目所使用的数据涵盖商家ID、名称、地址、城市、州、邮编、经纬度、星级评分、评论数量、营业状态、属性、类别及营业时间等丰富维度。这些数据能够帮助我们全面了解商家的运营情况,为后续的分析提供坚实的数据基础。
三、数据分析流程
- 数据清洗:运用Pyspark对原始数据进行清洗,去除重复、错误或无效的数据,保证数据的准确性。
- 数据转换:根据分析需求,对数据进行转换,如对文本数据进行分词、去除停用词等操作,以便进行进一步的分析。
- 数据聚合:对转换后的数据进行聚合,如按城市、商家类别等进行聚合,以便分析各城市商家分布、商家类别销量等。
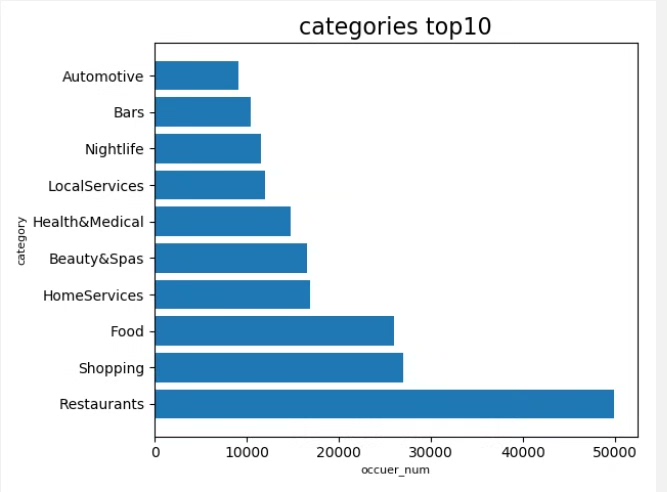
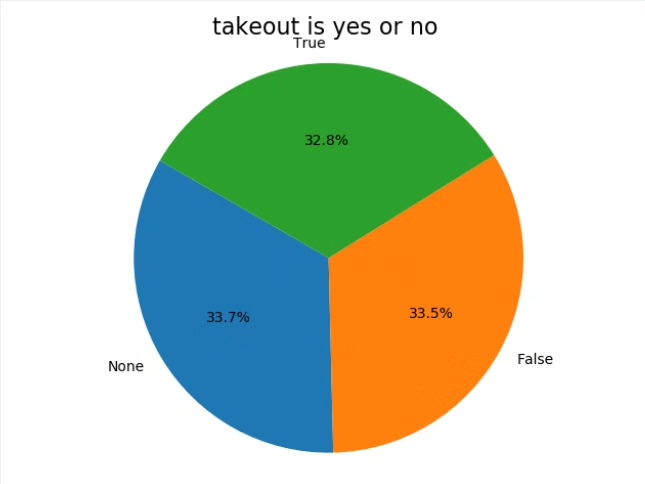
- 数据分析:通过Pyspark的SQL和DataFrame API进行数据分析,探索商家类别销量前十、各城市商家分布、评论活跃度、星级评价分布以及外卖服务渗透率等核心业务指标。
四、可视化展示
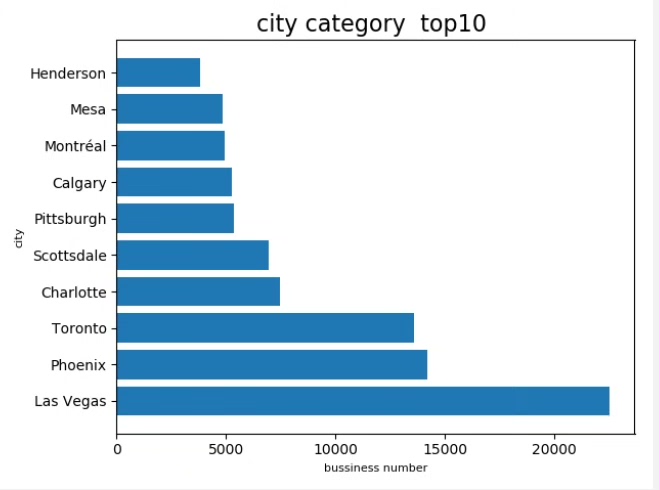
- 柱状图:用于展示各城市商家分布、商家类别销量等。通过柱状图,可以直观地看出各城市商家的数量及各类别商家的销量情况。
- 折线图:用于展示评论活跃度、星级评价分布等随时间的变化趋势。通过折线图,可以了解评论活跃度和星级评价的波动情况,为商家提供优化策略的依据。
- 饼图:用于展示各类型商家的占比、星级评价的分布等。通过饼图,可以清晰地看出各类商家的占比情况以及星级评价的分布情况。
五、项目价值
本项目通过Pyspark对大众点评商家数据进行深度分析和可视化,为决策者提供数据驱动的洞察。这些洞察可以帮助商家优化策略,提升顾客满意度,从而提高商家的业绩。同时,本项目也为其他行业的大数据分析和可视化提供了参考和借鉴。
六、总结
本项目利用Pyspark对大众点评商家数据进行深度分析和可视化,揭示了商家运营的关键趋势。通过直观的图表形式呈现分析结果,为决策者提供了数据驱动的洞察。未来,我们将继续优化分析模型和可视化效果,为商家提供更准确、更有价值的洞察,助力商家优化策略,提升顾客满意度。
项目51: 基于pyspark的大众点评数据分析和可视化项目
简介
本项目旨在对从大众点评收集的商家数据进行深度分析和可视化,运用Pyspark高效处理大规模数据集,揭示商家运营的关键趋势。
数据涵盖商家ID、名称、地址、城市、州、邮编、经纬度、星级评分、评论数量、营业状态、属性、类别及营业时间等丰富维度。
通过Pyspark对数据进行清洗、转换和聚合,我们将探索商家类别销量前十、各城市商家分布、评论活跃度、星级评价分布以及外卖服务渗透率等核心业务指标。
最终,借助Matplotlib和Pandas的强大绘图功能,将以直观的柱状图、折线图和饼图形式呈现分析结果,为决策者提供数据驱动的洞察,助力商家优化策略,提升顾客满意度。
Pyspark:用于大数据的分布式计算,实现数据的高效处理与分析。
Matplotlib:数据可视化工具,用于创建高质量的图表。
Pandas:提供高性能、灵活的数据结构和数据分析工具。
JSON:数据格式,用于解析和处理非结构化数据源。
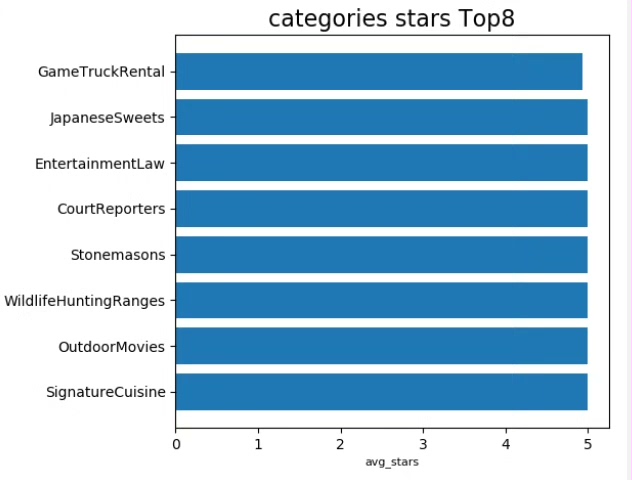
项目目标:分析并可视化商家类别销量TOP10;探究不同城市商家数量分布,识别TOP10城市;展示商家评论次数最多的前八名;揭示商家类别中星级评分最高的前八位。



















 1726
1726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









