







目录
(3)数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
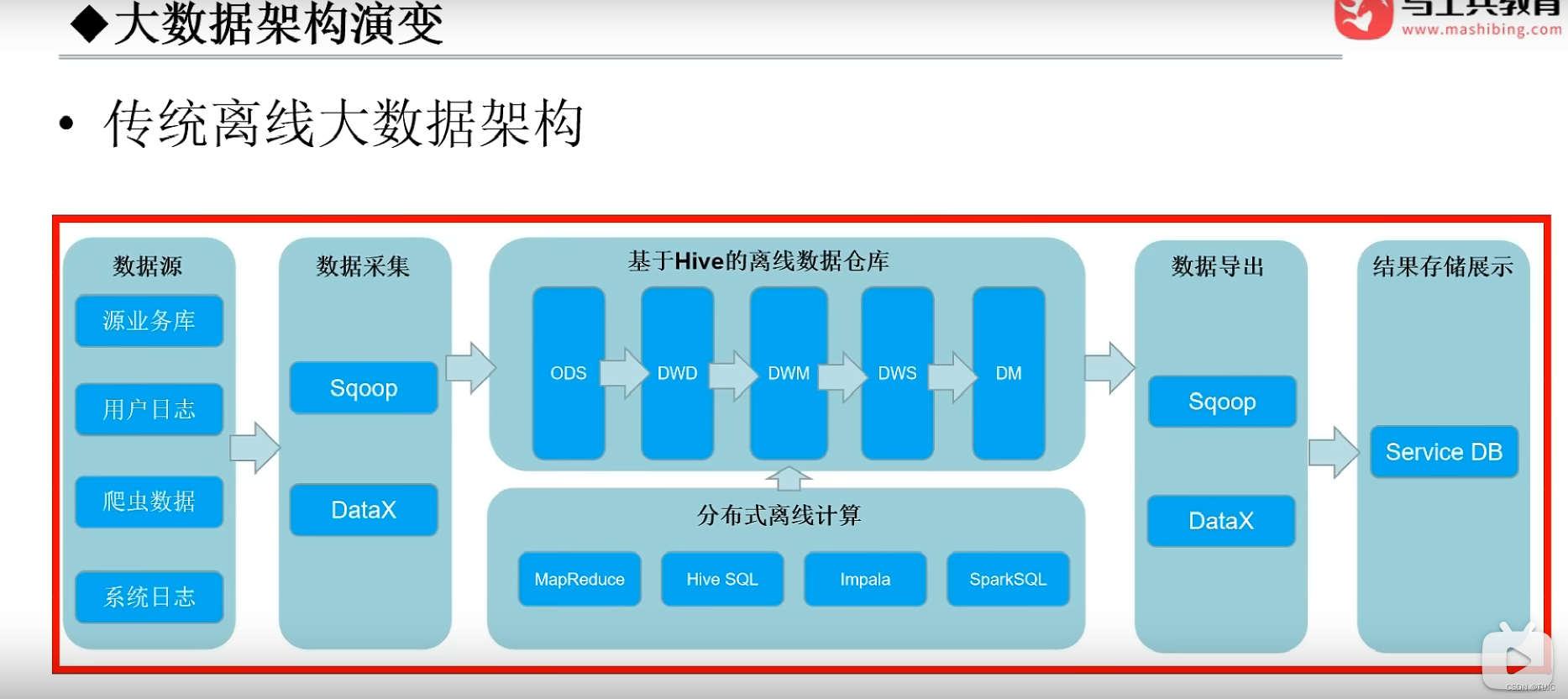
(1)第一阶段:基于hive的离线数仓,分层在hive表,计算通过MR或者Spark
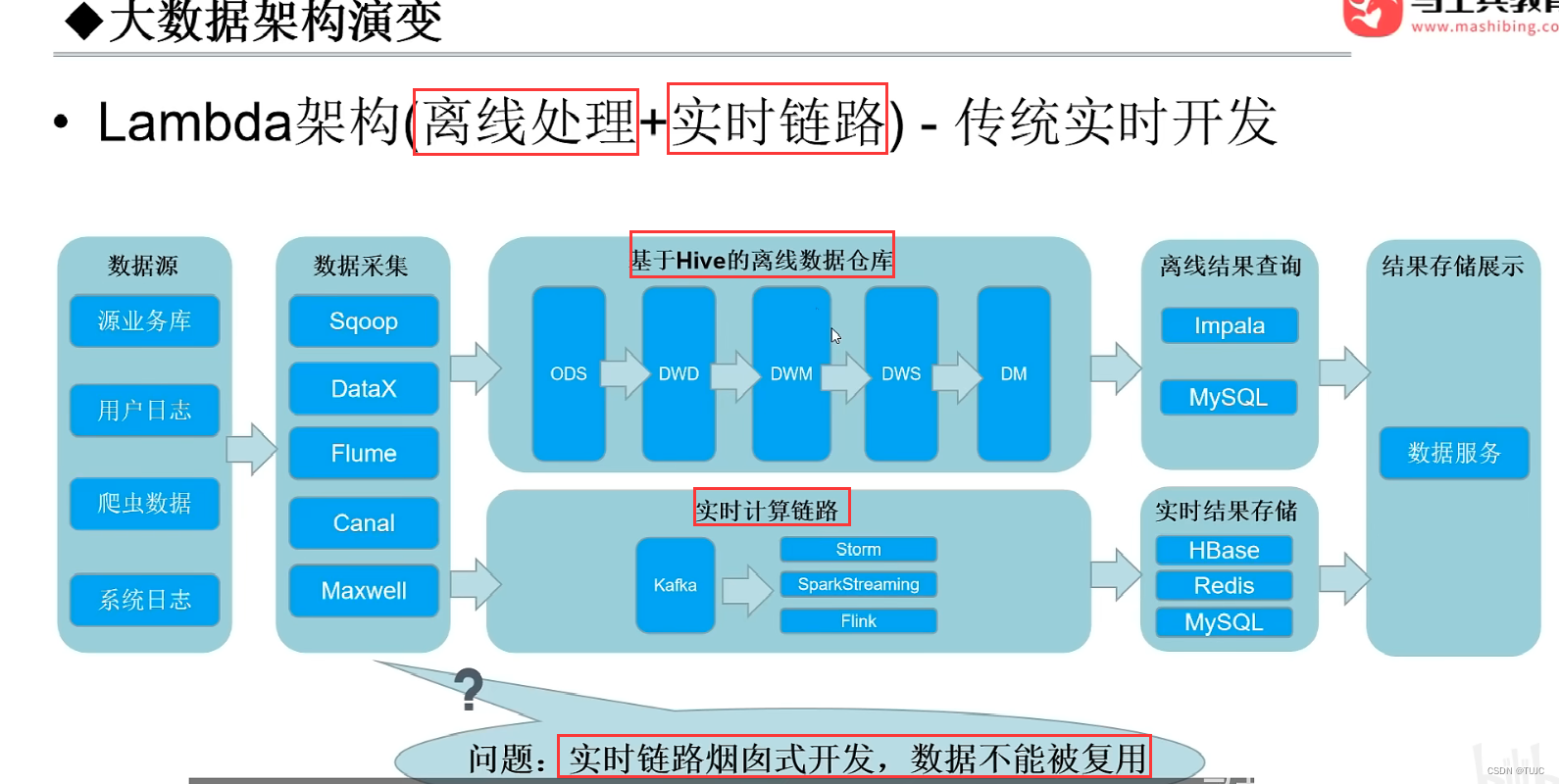
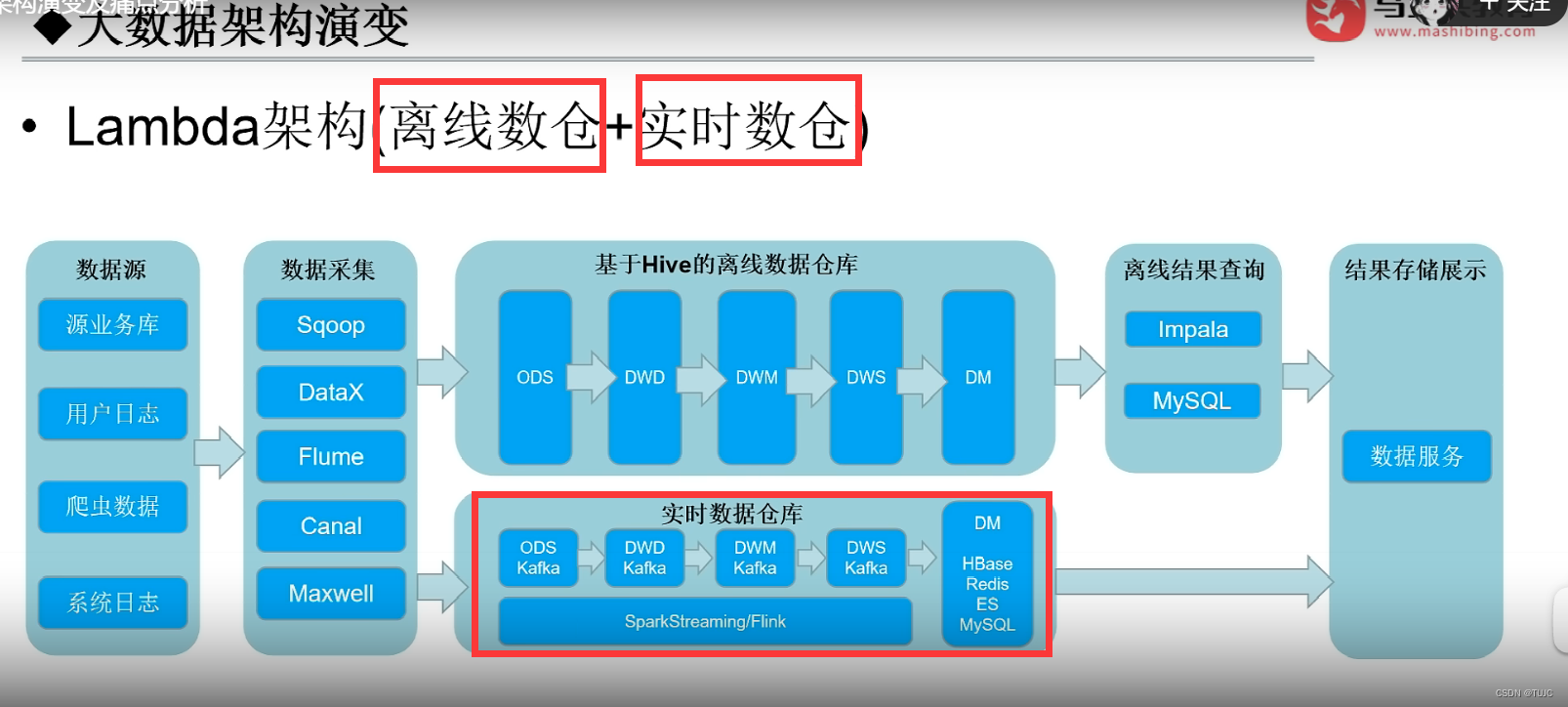
(2)第二阶段:lambda架构,基于hive的离线数仓+实时链路(kafka到spark或flink的实时计算)
(3)第三阶段:lambda架构,基于hive的离线数仓+实时数仓(kafka分层分表存储,spark或flink的实时计算)
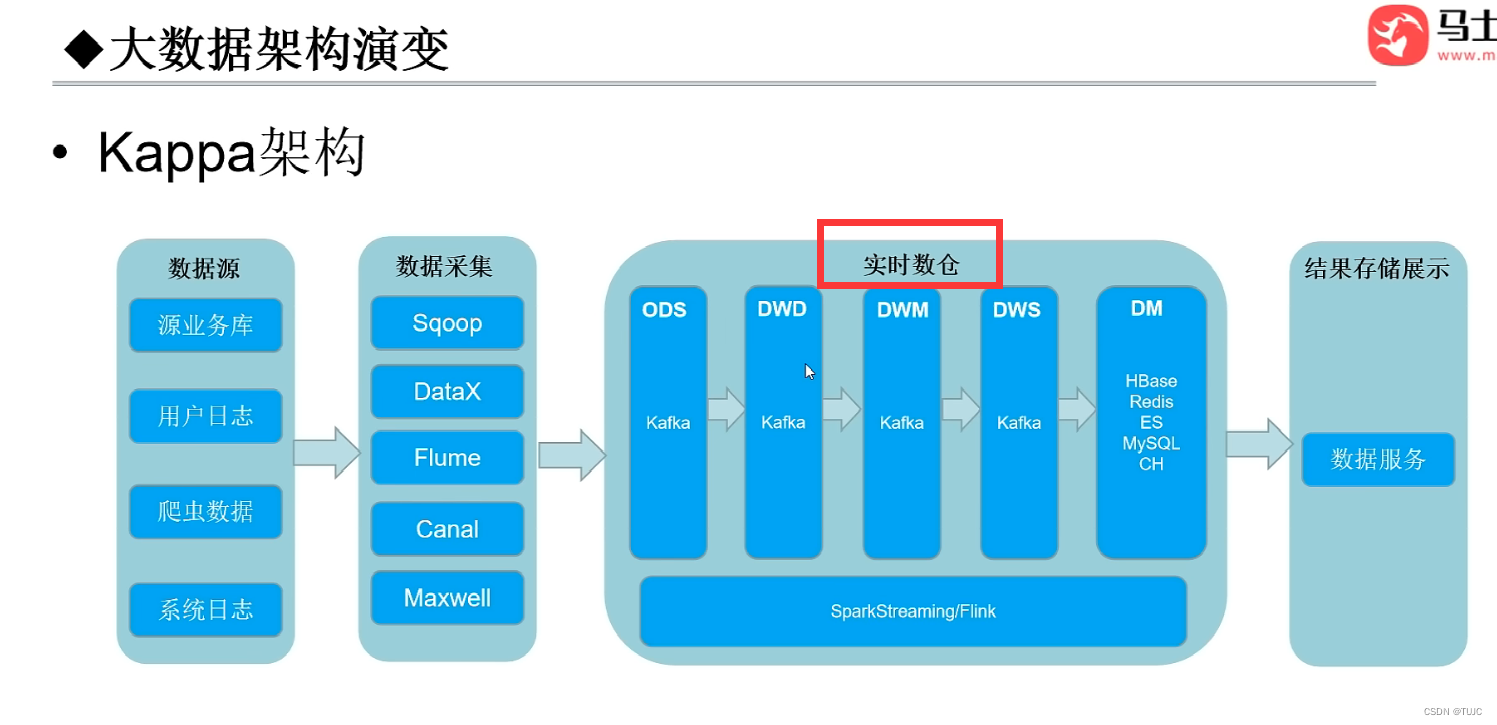
(4)第四阶段:Kappa架构,只有实时仓库,基于 kafka分层分表存储,spark或flink的实时计算
1、什么是数据仓库?如何构建数据仓?
数据仓库Data Warehouse,简写为DW或DWH。是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,目的是构建面向分析的集成化数据环境,为企业提供决策支持。它出于分析性报告和决策支持目的而创建。本身并不“生产”任何数据,也不需要“消费”任何的数据,数据来源于外部,并且开放给外部应用,这也是为什么叫“仓库”,而不叫“工厂”的原因。
一句话总结数仓建设:
1). 前期调研:通过三步调研(业务调研、需求调研、数据调研),划分主题域,确定主题。
2). 提炼业务模型:然后构建总线矩阵,维度建模(星型模型、四步建模),
3). 分层架构与定制规范:设计数仓分层架构(ods-dwd-dws-ads),定制规范(命名规范、模型规范、开发规范、流程规范)。
3). 数据治理:(数据质量,数据安全,元数据管理)。开工ETL/BI,迭代开发。
2、数仓如何分层 ? 每一层的作用? 为什么要这么分层?


1)ODS层(原始数据层):存储原始数据,直接加载原始日志、数据,数据保持原貌不做处理。
2)DWD层(明细层):对ODS层数据进行清洗(去除空值、脏数据,超过极限范围的数据)
3)DWS层(服务数据层):以DWD层为基础,进行轻度汇总。比如:用户当日、设备当日、商品当日。
4)ADS层(数据应用层)
用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大。
通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,相当于把一个复杂的工作拆成了多个简单的工作,把一个大的黑盒变成了一个白盒,每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性,当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。
DM数据集市
DM(Data Market)数据集市是以某个业务应用为出发点而建设的局部的数据仓库,所以DM数据集市的特点在于结构清晰,针对性强且扩展性良好,由于仅仅对某一个领域建立,容易维护修改。
数据集市分为独立数据集市与非独立数据集市,其中独立数据集市有独有的源数据库与ETL架构。而非独立数据集市则没有自己的源数据,全部数据位于数据仓库,开发人员通过权限的设置,为用户提供面向其业务的数据,该数据为数据仓库的子集。
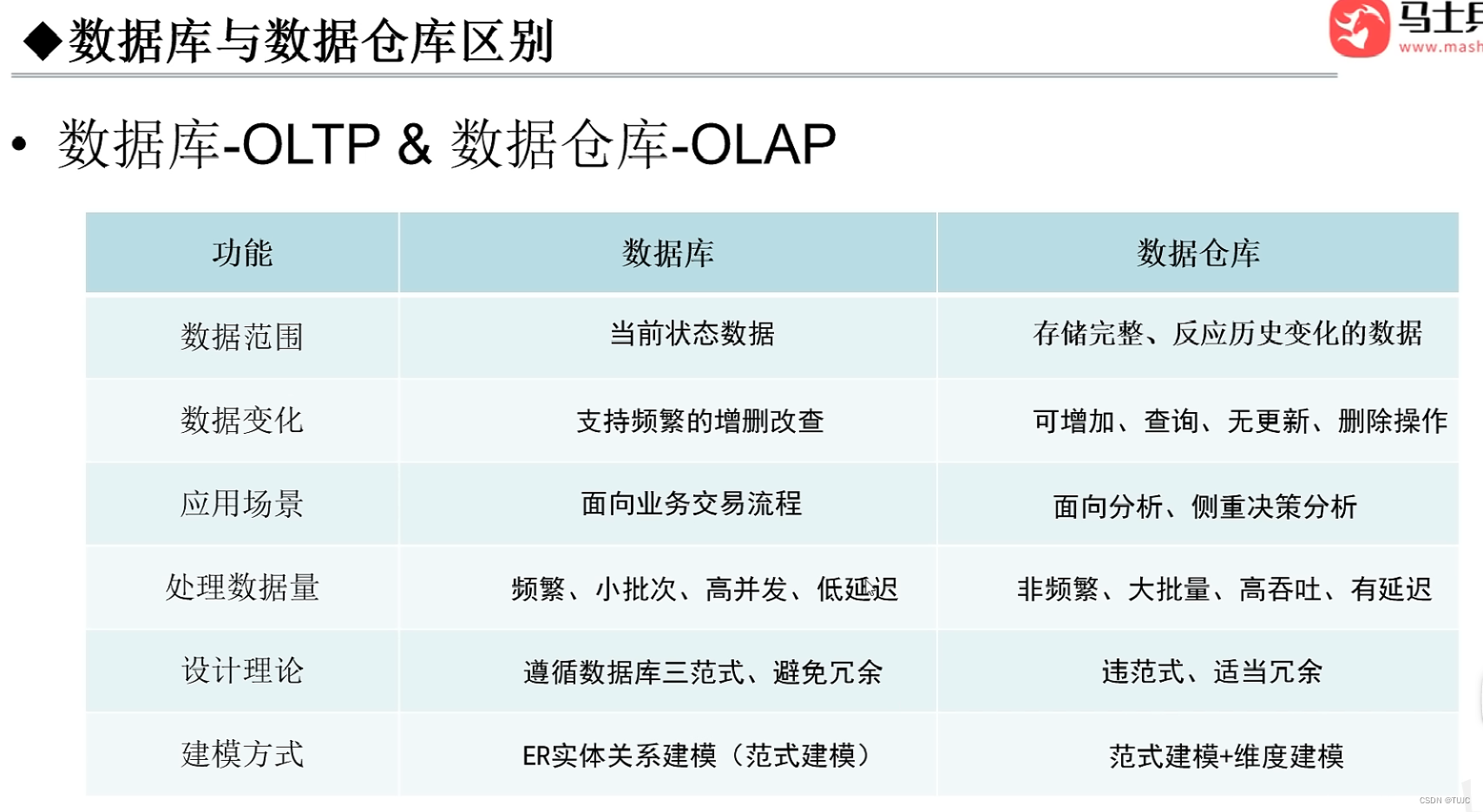
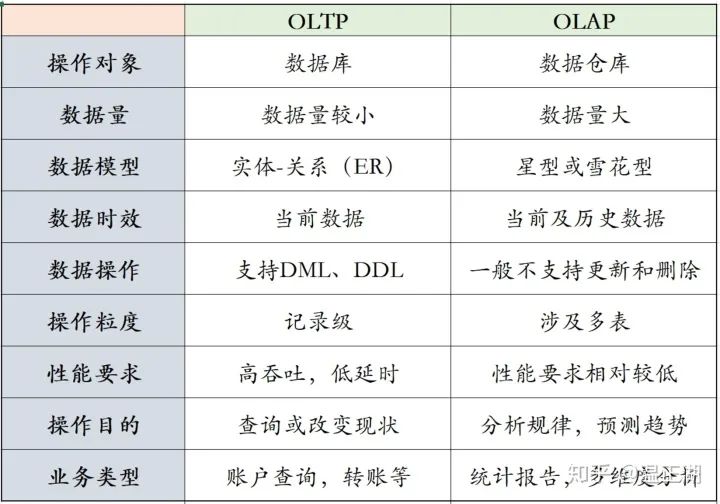
3、 数据仓库与数据库区别,
(1)是 OLTP 与 OLAP 的区别。
OLTP(On-Line Transaction Processing)操作型处理,叫联机事务处理, 主要是针对数据库中的数据进行增删改查,操作主体一般是产品的用户。关心操作响应时间、数据安全性、完整性和并发支持的用户数等问题,数据库系统 。
OLAP(On-Line Analytical Processing)分析型处理,叫联机分析处理 ,一般针对某些主题的历史数据进行分析,j进行管理决策。通过分析数据库中的数据来得出一些结论性的东西。比如给老总们看的报表。
(2)数据库设计是尽量避免冗余。
数据仓库在设计是有意引入冗余,依照分析需求,分析维度、分析指标进行设计。
(3)数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
4、传统数仓和大数据数仓的异同?有哪些大的变化?
主要数数仓数据存储的地方不同,传统数仓数据存储在mysql /oracle等关系型数据库上,大数据数仓存储在hadoop 平台的hive中(实际上是HDFS中),当然也有其他的数仓产品比如TD、greenplum等。
5、数仓架构
(1)第一阶段:基于hive的离线数仓,分层在hive表,计算通过MR或者Spark
(2)第二阶段:lambda架构,基于hive的离线数仓+实时链路(kafka到spark或flink的实时计算)
(3)第三阶段:lambda架构,基于hive的离线数仓+实时数仓(kafka分层分表存储,spark或flink的实时计算)
(4)第四阶段:Kappa架构,只有实时仓库,基于 kafka分层分表存储,spark或flink的实时计算
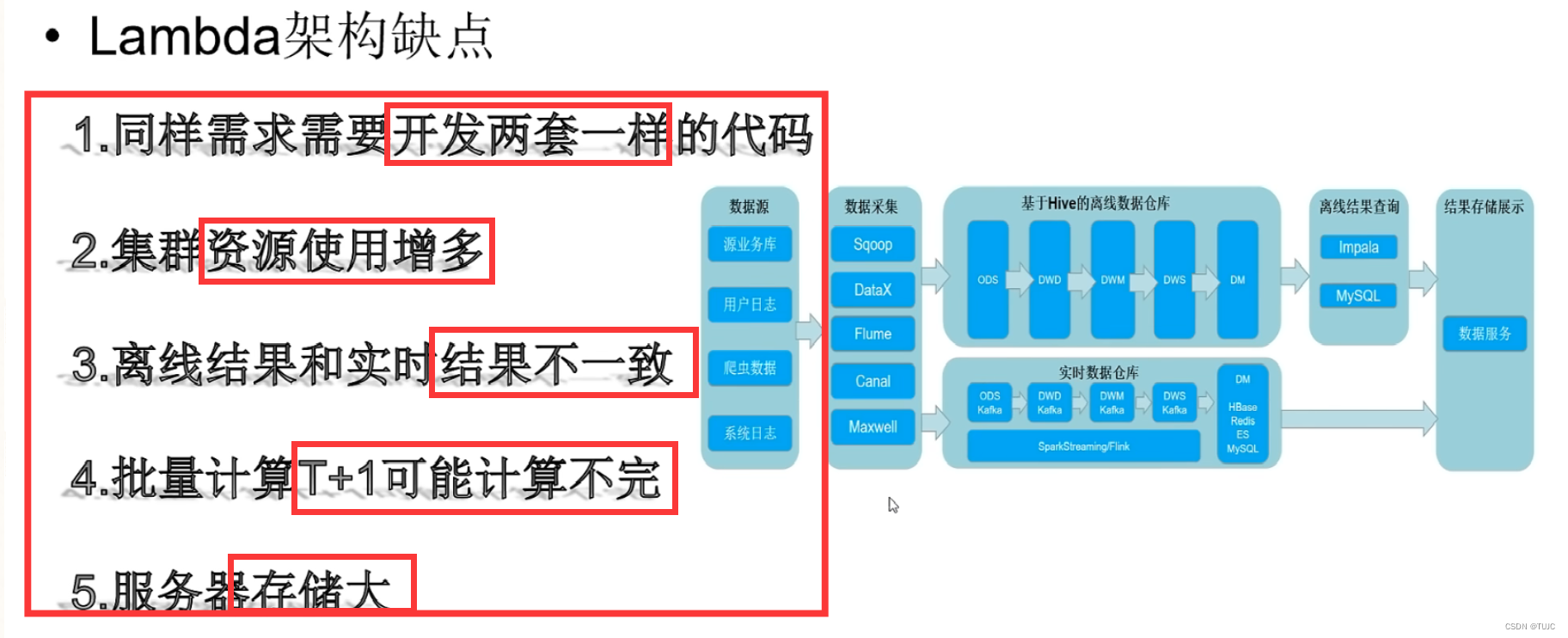
(5)架构优缺点
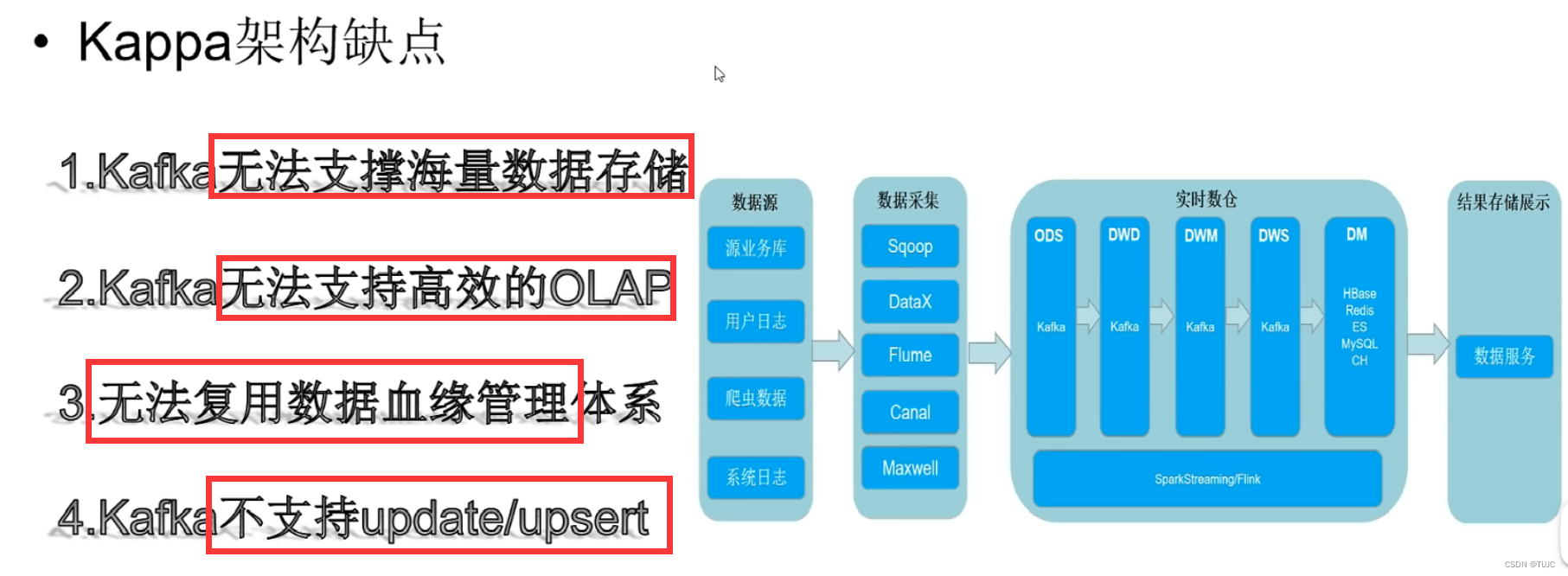
(6)架构的选择


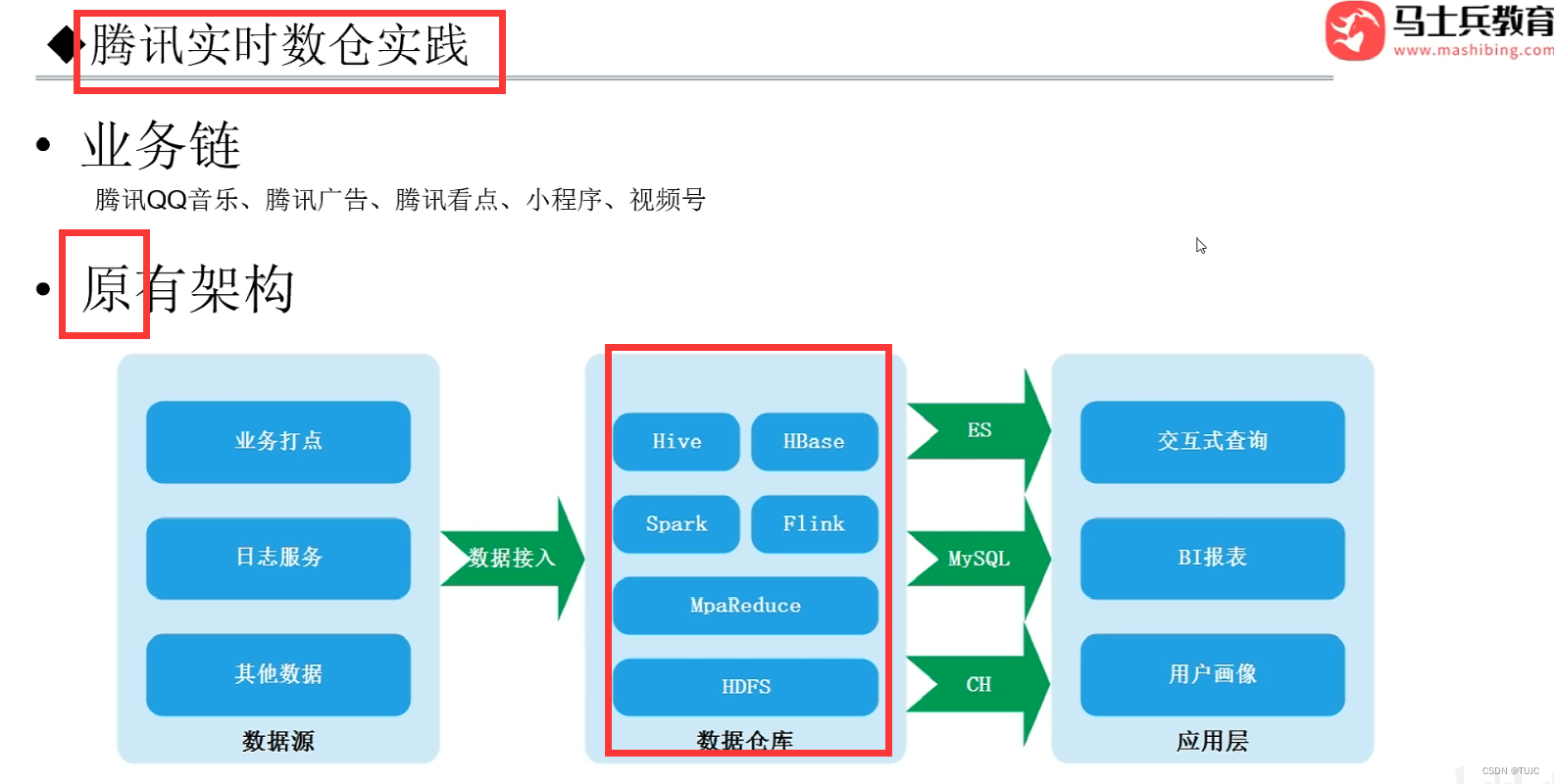
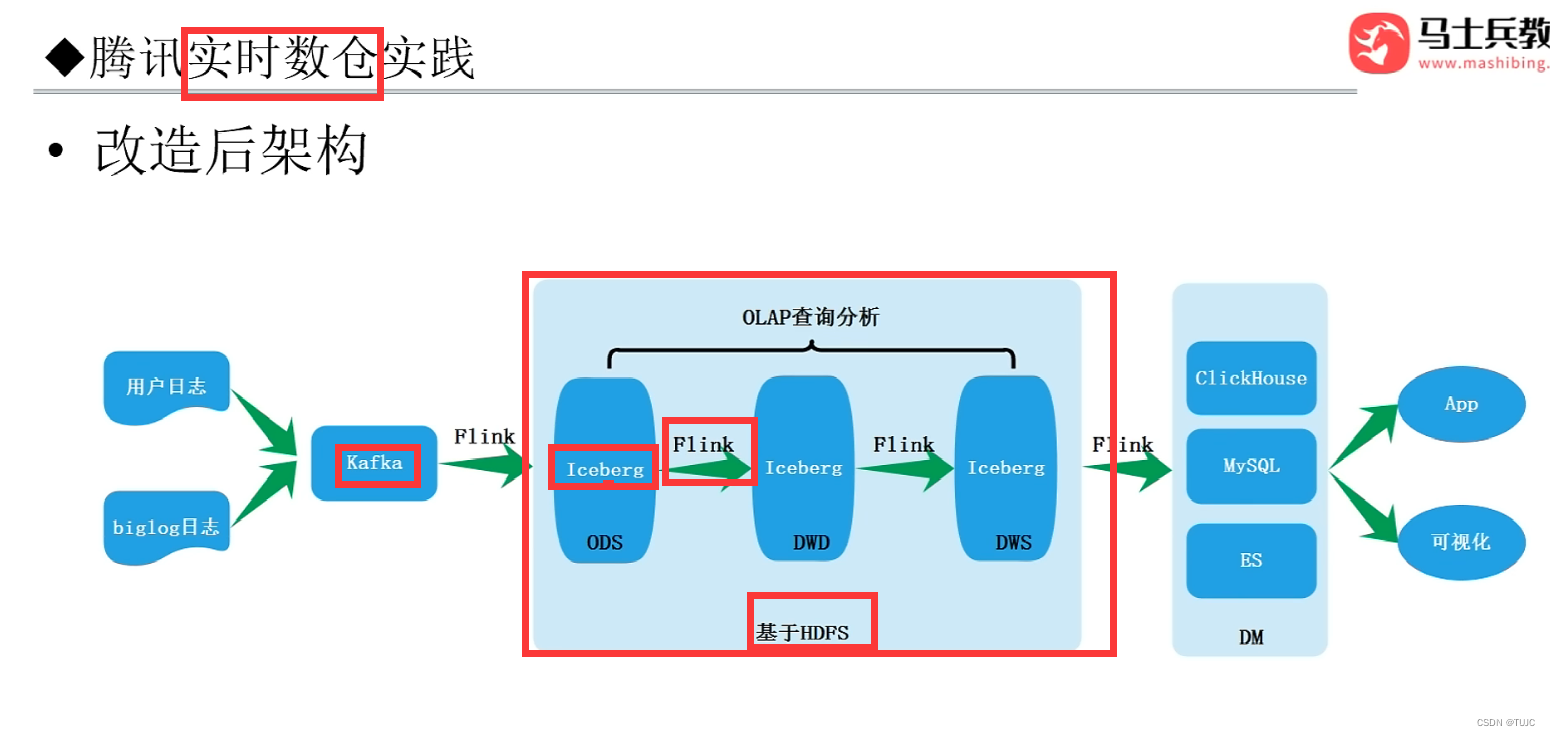
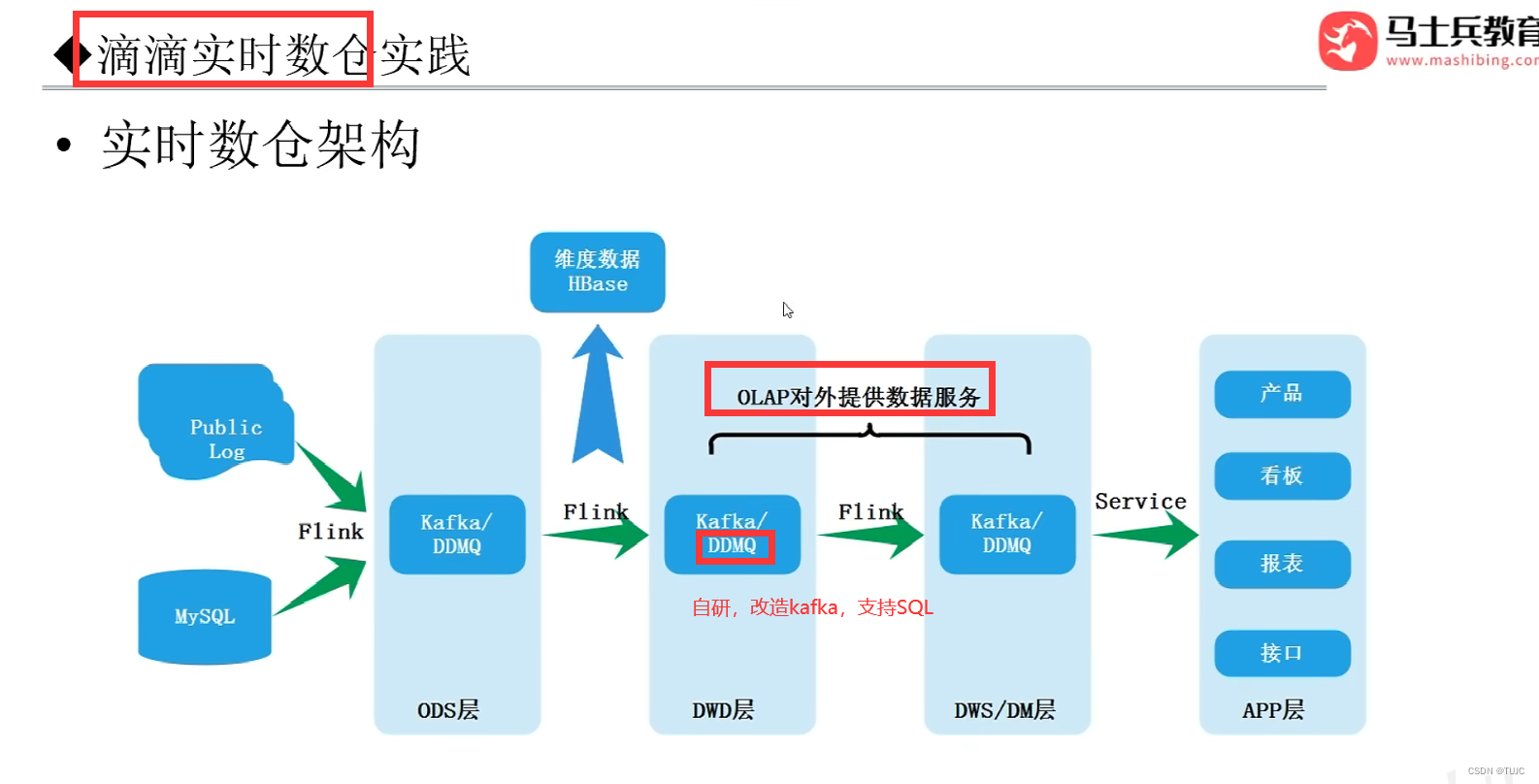
(7)大厂架构
6、数据湖
数据湖,是一个集中式的存储库,允许你以任意规模存储多个来源、所有结构化和非结构化数据,可以按照原样存储数据,无需对数据进行结构化处理,并运行不同类型的分析,对数据进行加工,例如︰大数据处理、实时分析、机器学习,以指导做出更好地决策。

Kappa架构可以称为真正的实时数仓,目前在业界最常用实现就是Flink + Kafka,然而基于Kafka+Flink的实时数仓方案也有几个非常明显的缺陷,所以在目前很多企业中实时数仓构建中经常使用混合架构,没有实现所有业务都采用Kappa架构中实时处理实现。
Kappa架构缺陷如下:
1.Kafka无法支持海量数据存储。对于海量数据量的业务线来说,Kafka一般只能存储非常短时间的数据,比如最近一周,甚至最近一天。
2.Kafka无法支持高效的OLAP查询,大多数业务都希望能在DWD\DWS层支持即席查询的,但是Kafka无法非常友好地支持这样的需求。
3.无法复用目前已经非常成熟的基于离线数仓的数据血缘、数据质量管理体系。需要重新实现一套数据血缘、数据质量管理体系。
4.Kafka不支持update/upsert,目前Kafka仅支持append。
为了解决Kappa架构的痛点问题,业界最主流是采用“批流一体”方式,这里批流一体可以理解为批和流使用SQL同一处理,也可以理解为处理框架的统一,例如: Spark、Flink,但这里更重要指的是存储层上的统一,只要存储层面上做到“批流一体”就可以解决以上Kappa遇到的各种问题。 数据湖技术,可以很好的实现存储层面上的“批流一体”,这就是为什么大数据中需要数据湖的原因。
数据湖具有以下特点:
a) 容量大
数据湖汇 聚吸收各个业务数据源流,容纳散落在各处的数据,理论上,存储空间巨大。
b) 格式多
数据湖架构面向多数据源的信息存储,可以快 速高效地采集、存储、处理大量来源不同、格式不同 的原始数据,这其中包括文本、图片、视频、音频、网 页等各类无序的非结构化数据,能把不同种类的数 据汇聚存储在一起,并对汇聚后的数据进行管理, 建立数据之间的关联关系,具有很强的兼容性。
c) 处理速度快
数据湖技术能将各类原始数据快速转化为可 以直接提取的、分析、使用的标准格式,统一优化数 据结构并对数据进行分类存储,根据业务需求,对 存储的数据进行快速的查询、挖掘、关联和处理,并实时传输给末端用户。
d) 体系结构
由于Hadoop也能基于分布式文件系统来存储处理多类型数据,因此许多人认为Hadoop的工作机理就是数据湖的处理机制。当然,Hadoop基于其分布式、可横向扩展的文件系统架构,可以管理和处理海量数据,但是它无法提供数据湖所需要的复杂元数据管理功能,最直观的表现是,数据湖的体系结构表明数据湖是由多个组件构成的生态系统,而Hadoop仅仅提供了其中的部分组件功能。
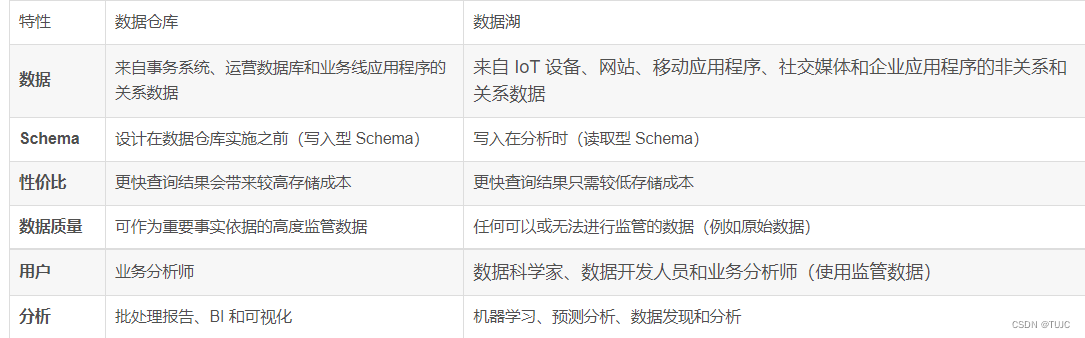
数据仓库:数仓这样的一种数据存储架构,它主要存储的是以关系型数据库组织起来的结构化数据。数据通过转换、整合以及清理,并导入到目标表中。在数仓中,数据存储的结构与其定义的schema是强匹配的。
数据湖:数据湖这样的一种数据存储结构,它可以存储任何类型的数据,包括像图片、文档这样的非结构化数据。数据湖通常更大,其存储成本也更为廉价。存储其中的数据不需要满足特定的schema,数据湖也不会尝试去将特定的schema施行其上。相反的是,数据的拥有者通常会在读取数据的时候解析schema(schema-on-read),当处理相应的数据时,将转换施加其上。
数据湖基本概念--什么是数据湖,数据湖又能干什么?为什么是Hudi_一个数据小开发的博客-CSDN博客_数据湖技术
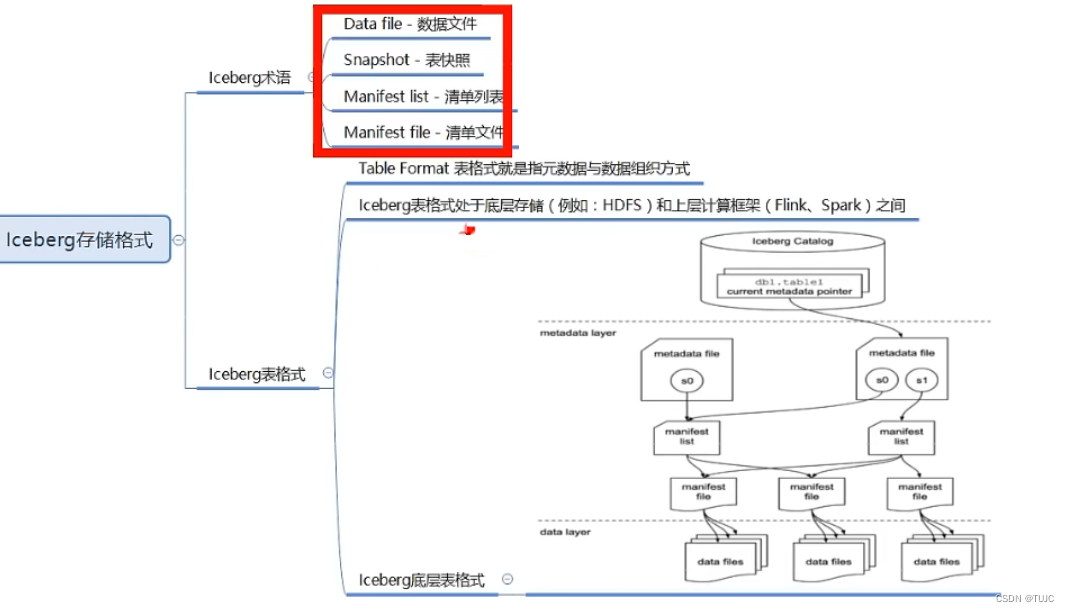
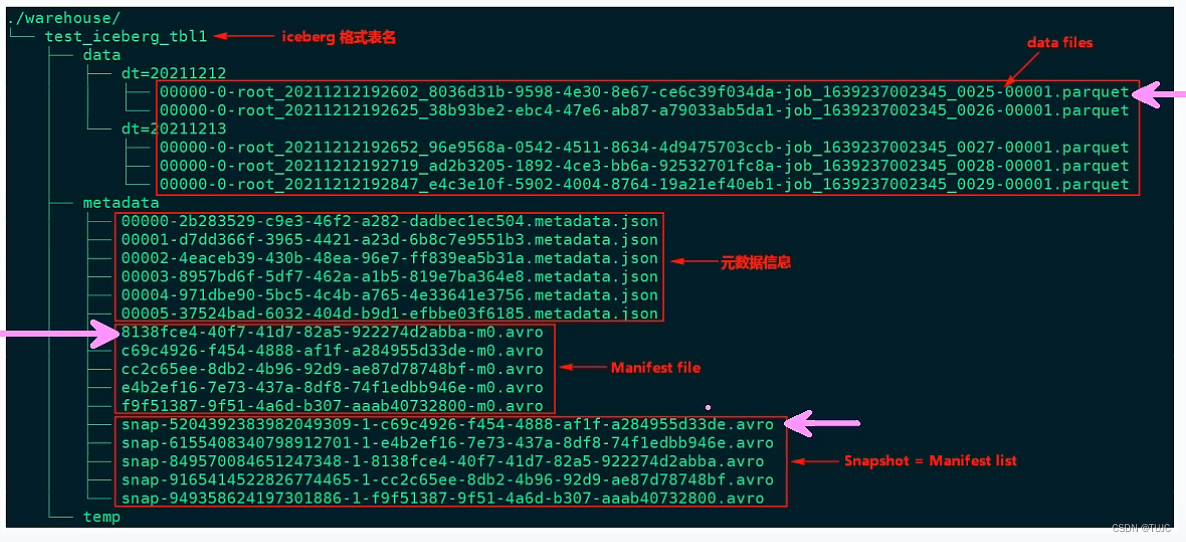
7、 lceberg概念及特点

Apache lceberg是一种用于大型数据分析场景的开放表格式(Table Format ) 。Iceberg使用一种类似FSQL表的高性能表格式,lcebera格式表单表可以存储数十PB数据,适配Spark、Trino、PrestoDB、Flink和Hive等计算引擎提供高性能的读写和元数据管理力能,lceberg是一种数据湖解决方案。
8、数据中台
数据中台不是简单的一套软件系统或者一个标准化产品,更多的是一种强调资源整合、集中配置、能力沉淀、分步执行的运作机制。 以数字化的手段,将数据抽像成服务,响应前端业务的快速变化,一套持续不断把数据变成资产并服务于业务的机制。
在传统的前台-后台架构中,各个项目相对独立,许多项目都在重复发明同样的轮子,即让项目本身越来越臃肿,也让开发效率越来越低。这种时候,为提高开发效率,我们有必要整合出一个中间组织,为所有的项目提供一些公共资源。而这个中间组织,就是人们所说的“中台”
数据中台一般会具备4个能力:数据采集整合、数据提纯加工、数据服务可视化、数据价值变现。
1、 数据采集整合:创建企业数据中台第一步,打破企业内部各个业务系统的数据隔阂,形成统一的数据中心,为后续数据价值的挖掘提供基础。主要通过数据采集和数据交换实现。
2、数据提纯加工:主要是对数据统一标准、补充属性,然后根据维度汇总成数据表、最后汇总出所需要的报表,满足企业对数据的需求。
3、数据服务可视化:对数据进行计算逻辑的封装,生成API服务,上层数据应用可以对接数据服务API,让数据快速应用到业务场景中。数据服务API对接的3种常见数据应用包括数据大屏、数据报表、智能应用。
4、 数据价值变现:通过打通企业数据,提供以前单个部门或者单个业务部门无法提供的数据服务能力,为赋能前端应用、数据价值变现提供基础。
9、数据仓库、数据中台、数据湖的理解
数据仓库, 是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,目的是构建面向分析的集成化数据环境,为企业提供决策支持。 本身并不“生产”任何数据,也不需要“消费”任何的数据,数据来源于外部,并且开放给外部应用 。
数据湖,是一个集中式的存储库,允许你以任意规模存储多个来源、所有结构化和非结构化数据,可以按照原样存储数据,无需对数据进行结构化处理,并运行不同类型的分析,对数据进行加工,例如︰大数据处理、实时分析、机器学习,以指导做出更好地决策。
数据中台,不是简单的一套软件系统或者一个标准化产品,更多的是一种强调资源整合、集中配置、能力沉淀、分步执行的运作机制。 以数字化的手段,将数据抽像成服务,响应前端业务的快速变化,一套持续不断把数据变成资产并服务于业务的机制。提高开发效率,我们有必要整合出一个中间组织,为所有的项目提供一些公共资源。
10、表的分类
1)实体表:
一般是指一个现实存在的业务对象,比如用户,商品,商家,销售员等等。类似于我们创建的javaBean映射数据库当中的表 (User表 , 商品表,商家表,销售员表)
2)维度表:
一般是指对应一些业务状态,编号的解释表。也可以称之为码表。比如地区表,订单状态,支付方式,审批状态,商品分类等等。
3)事务性的事实表:
一般指随着业务发生不断产生的数据。特点是一旦发生不会再变化。比如,交易流水,操作日志,出库入库记录等等。
4)周期性的事实表:
随着业务发展,不断产生的数据。比如订单,其中订单状态会周期性变化。再比如,请假、贷款申请,随着批复状态在周期性变化。
11、同步策略
(1) 数据同步策略
的类型包括:全量表、增量表、新增及变化表、拉链表
- 全量表:存储完整的数据。全表所有的数据都同步一次
- 增量表:存储新增加的数据。
- 新增及变化表:存储新增加的数据和变化的数据。
- 拉链表:对新增及变化表做定期合并。用于解决hive当中单个字段更新的问题 ,可以细致的观察到每条数据每一个时间段的发展变化情况
(2) 表的同步策略
- 实体表(全量)
- 维度表(全量)
- 事务型事实表(增量)
- 周期型事实表(新增和变化、拉链表)
12、范式理论
一范式原则:属性不可切割;
二范式原则:不能存在部分函数依赖;
三范式原则:不能存在传递函数依赖;
关系型数据库设计时,遵照一定的规范要求,目的在于降低数据的冗余性,目前业界范式有:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)、第五范式(5NF)。
范式可以理解为设计一张数据表的表结构,符合的标准级别。
使用范式的根本目的是:
1)减少数据冗余,尽量让每个数据只出现一次。
2)保证数据一致性
缺点是获取数据时,需要通过Join拼接出最后的数据。
(1)三范式区分
1、第─范式1NF: 属性不可切割,保证每列的原子性。
2、第二范式2NF:不能存在“部分函数依赖”,保证一张表只描述一件事情。
3、第三范式3NF: 不能存在传递函数依赖,保证每列都和主键直接相关。
(2) 函数依赖

13、表模型
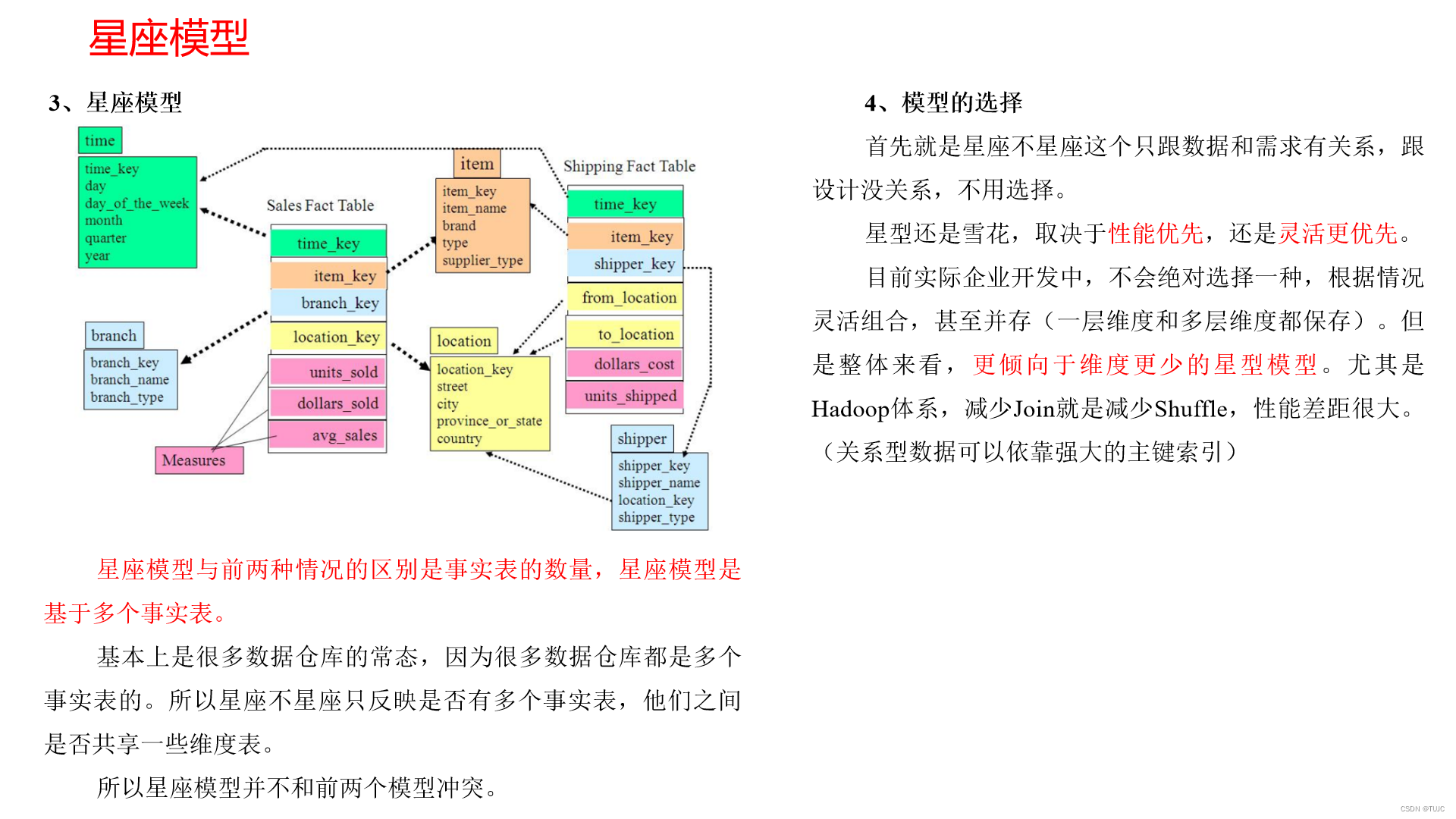
星型模型,维度一层;
雪花模型,维度多层;
星座模型,多个事实表;
性能优先选择星型模型,灵活优先选择雪花模型。企业中星型模型多一些。
(1) 关系建模与维度建模
关系模型主要应用与OLTP系统中,为了保证数据的一致性以及避免冗余,所以大部分业务系统的表都是遵循第三范式的。
维度模型主要应用于OLAP系统中,因为关系模型虽然冗余少,但是在大规模数据,跨表分析统计查询过程中,会造成多表关联,这会大大降低执行效率。
所以把相关各种表整理成两种:事实表和维度表两种。所有维度表围绕着事实表进行解释。
(2)星型模型、雪花模型、星座模型
在维度建模的基础上又分为三种模型:星型模型、雪花模型、星座模型。
数仓维度建模模型 ,使用星型的建模方式

电商指标
1、SPU(Standard Product Unit):是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息集合。
如:买一台iPhoneX手机,iPhoneX手机就是一个SPU;
2、SKU(Stock Keeping Unit,库存量基本单位):现在已经被引申为产品统一编号的简称,每种产品均对应有唯一的SKU号。
如:一台银色、128G内存的、支持联通网络的iPhoneX是一个SKU;
SPU表示一类商品。好处就是:可以共用商品图片,海报、销售属性等。
3、GMV:一段时间内的网站成交金额(包括付款和未付款)
















 2286
2286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









