







数仓学习的特点
-
理论庞杂,跟业务紧密关联
分层建模
数仓架构类似于盖房子,有专业的土木、建筑、法规等,但每个房子都是独一无二的,跟房子的需求紧密结合。
-
注重实践,初级接触不到
-
技术、组件没有统一标准,灵活组合
一、概述
1. 数仓是什么,解决了什么问题,如果没有会怎样?
在小数据量的时代,企业的需求是建设各种应用来实现业务流程,此时的数据存储在关系型数据库中,范式模型也成为了业务系统的主要数据存储模型。
后来,企业逐渐有了数据分析的需求,数据量、数据的格式、来源发生了很大变化。虽然业务系统的范式模型也能满足一部分的分析需求,但是存在很多的缺陷,比如表关联复杂、查询效率低、一些需求需要跨系统取数等等,于是人们转而寻找更合适的数据模型来满足分析型应用的需求,在研究发展过程中,数仓的概念就诞生了。
类似于快递的集散中心,比如上海韵达的集散中心,全国各地的快递先汇总到这,暂存、根据地区分类、根据优先级确定顺序、分发到各个快递员,然后再送到手里,实际上这个仓库并不仅仅是存储,还有转换格式、分类聚合、分层的作用,所以用集散中心这个词更合适。既然是仓库,那必然要考虑数据怎么存,存什么样的格式,怎么取怎么用,这个就需要一套体系去组织和管理,这整套体系就形成了数仓的一系列理论。
总结大数据场景下企业面临的数据问题:多源异构、脏乱差的数据现象。
- 结构复杂
- 数据脏乱
- 理解困难
- 缺少历史
数据仓库,英文名称为DataWarehouse,可简写为DW或DWH。它出于分析性目的而创建。将不同来源的数据采集到统一的存储介质,对数据进行清洗、分析、分类、存储、计算、根据业务重组,为企业决策提供数据,为下游应用供数,实现数据赋能、数据驱动。
数仓的业务价值体现:
- 效果
- 诊断
- 预警
这里的企业决策,从业务的角度,其实分4块:
- BI,就是报表,比如分组求topN。
- 即席查询。
- 随机、自定义查询数据库。即席:当场、随时,就是当场去查询。自己键入的SQL代码就是即席查询,相对于提前写好来说。将SQL代码写在java代码里,通过某个按钮去触发就不是即席查询,
- 一般使用sql。
- 并不是大数据领域独有的概念。
- 并不意味着慢,也可以使用缓存、索引。秒级。
- Kylin、druid、presto、impala是常见的即席查询工具。四种即席查询工具比较
- 和实时数仓的区别
- 可视化
- 即席查询。
- ai
- 为ai模型提供训练数据
- 跑ai模型,为ai模型供数,比如为财务预警模型提供营业利润、无形资产比率、总利润增长率等数据
- 下游web应用,将ADS层数据同步到下游web应用的业务数据库中
比如数据管控平台的指标查询。
运营系统、业务系统 - 推荐系统和用户画像。
一般企业这2块算到大数据部门,数智,所以有些会要求会一些算法。
==>数仓是一切大数据应用的基础。
2. 数仓的特点
3. 数仓和数据库的区别
一个应用必然要存放数据。比如淘宝。物品的存货数量,货品的价格,用户的账户余额之类的。这些数据都是存放在后台数据库中。或者最简单理解,我们现在微博,QQ等账户的用户名和密码。在后台数据库必然有一张user表,字段起码有两个,即用户名和密码,然后我们的数据就一行一行的存在表上面。当我们登录的时候,我们填写了用户名和密码,这些数据就会被传回到后台去,去跟表上面的数据匹配,匹配成功了,你就能登录了。匹配不成功就会报错说密码错误或者没有此用户名等。
数据库的表设计往往是针对某一个应用进行设计的。比如刚才那个登录的功能,这张user表上就只有这两个字段,没有别的字段了。但是这张表符合应用,没有问题。但是这张表不符合分析。比如我想知道在哪个时间段,用户登录的量最多?哪个用户一年购物最多?诸如此类的指标。那就要重新设计数据库的表结构了。
对于数据分析和数据挖掘,我们引入数据仓库概念。数据仓库的表结构是依照分析需求,分析维度,分析指标进行设计的。
关于2者的区别,
我们先从OLTP与OLAP的区别来看?
OLTP系统的主要数据操作是随机读写,主要采用满足3NF的实体关系模型存储数据,在事务处理中解决数据的冗余和一致性问题:
而OLAP系统面向的主要数据操作是批量读写,事务处理的一致性不是OLAP关注的,其主要关注数据的整合,以及复杂大数据查询中的性能,因此它需要采用些不同的数据模方法。
| 比较项 | 操作型(OLTP) | 分析性(OLAP) |
|---|---|---|
| 关注 | 细节 | 综合或提炼 |
| 模型 | 实体 – 关系(E-R) | 星型或雪花 |
| 操作 | 可更新 | 只读,只追加 |
| 操作粒度 | 操作一个单元 | 操作一个集合 |
| 场景 | 面向事务 | 面向分析 |
| 数据量 | 小 | 大 |
| 需求 | 日常操作 | 决策需求 |
| 业务方向 | 客户信息、订单等查询 | 客户登录间隔时间,市场细分等 |
操作型处理,叫联机事务处理OLTP(On-Line Transaction Processing,),也可以称面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。
分析型处理,叫联机分析处理OLAP(On-Line Analytical Processing)一般针对某些主题的历史数据进行分析,支持管理决策。

4. 数仓和大数据平台的关系
数据仓库是一个数据集合,而大数据平台是给数仓提供底层技术基础的平台;
数仓是很久之前就有的概念,最开始的数仓不是基于大数据平台构建的,被称为传统数仓,传统数仓是基于Oracle、Teradata、DB2这些作为工具来开发,而现在是基于大数据平台。
4.1 数仓在数据平台中的位置

5. 几个概念
5.1 数据湖
每个应用会产生、存储大量数据,而这些数据并不能被其他应用程序使用,这种状况导致数据孤岛的产生。另外还有数据管理、数据所有权与访问控制等都亟须解决,因为企业寻求获得更高的使用有效数据的能力。
为了解决前面提及的各种问题,企业需要搭建自己的数据湖,数据湖不但能存储传统类型数据,也能存储任意其他类型数据(文本、图像、视频、音频),并且能在它们之上做进一步的处理与分析,产生最终输出供各类程序消费。而且随着数据多样性的发展,数据仓库这种提前规定schema的模式显得越来难以支持灵活的探索&分析需求,这时候便出现了一种数据湖技术,即把原始数据全部缓存到某个大数据存储上,后续分析时再根据需求去解析原始数据。简单的说,数据仓库模式是schema on write,数据湖模式是schema on read。
随着 Hadoop 技术日趋成熟,2010 年,Pentaho 创始人兼 CTO James Dixon 在纽约 Hadoop World 大会上提出了数据湖的概念,他提到:
数据湖(Data Lake)是一个以原始格式存储数据的存储库或系统。
数据湖就是把数据都集中到一个地方存储。
数据湖概念的提出,我认为是 Hadoop 从开源技术走向商业化成熟的标志。企业可以基于 Hadoop 构建数据湖,将数据作为一种企业核心资产。可以作为数仓的数据源,机器、深度学习可以从数据湖来拿数据。
5.2 数据集市
5.3 数据中台
数据资产
二、数仓的构建
构建 = 分析 + 搭建
数仓先分析后搭建
1. 数仓的分析
比如:甲方给出一个模糊的目标,比如从13个上游系统中采集数据,搭建数仓和报表系统。应该如何入手,流程是什么?
1.1 自下而上,从应用入手
数仓的目的:以数据驱动,为运营赋能
赋能赋的是运营,数据输出大部分面向运营。数据以大盘的形式,比如bi、可视化、数据产品
怎么实现数据驱动、赋能?告诉运营现状是什么、风险、目标、需要改进的东西是什么。
比如新客少,多维度分析,哪个城市少、哪个品类少,先看运营效果,再看原因。用户流程分析。这些东西都在一个大盘中。
从应用层往上游不断的抽象。可以是三层也可以是四层。先把指标分个类:用户增长的、运营的、供给的等等,然后往上一层抽象(主题域),比如用户,需要新客、活跃、留存、忠诚、流失,然后再往上抽象(主题):用户首单、用户末单、用户使用补贴,在往上就是贴源层了(ods),不多说了。
大盘的内容是什么?比如用户增长大盘,要关心新客、用户留存、转化==》指标
这些指标伴随很多维度,渠道、栏目维度
这些指标从哪来?要涵盖流量、商品、用户行为,==》dws层,dws不只是汇总,
dws 公共指标层,topic层(注意,这里的topic并不是dwd里的主题,可以翻译为场景,场景是一个动作,比如吃饭、用餐具、上厕所、点外卖)。dim和dwd组合生成面向分析、轻度汇总的表。app层逻辑下沉到dws
吃饭、不同的饭都是同一个场景,
用餐具、场景
去地点:饭店、酒吧
面向不同场景,场景就是动作,动作一定会落到主题中,比如吃饭,其所需要的主题就有食材、餐具、地点,主题就是分析域,分析域就已经可以匹配dwd上的表了。然后就有了维度和事实的问题。有些维度ods已经存在,有些不存在,比如入口,这种就是在数仓中算的,入口有很多不同的归因方式。
dwd 在主题的基础上汇总活动主题、交易主题。面向主题的明细层,业务基础上衍生。比如订单,订单首购明细、订单支付明细、
dim 大部分从ods来,有些自己生成
ods fact层
1.2 从实操的角度总结下:
- 先拿到业务过程
业务过程是一个业务生命周期内产生的行为。比如从产生订单到用户收到货这就是一个完整的业务过程 - 分析业务,不管零售、电商,先分析业务。业务过程是什么?
比如:
从进美团APP,下单,到送到手里
用户 到商家,找商品,下订单,配送,物流。涉及到流量转化 - 从业务得到最终大盘需要的指标,指标推导出场景,场景推导出主题,主题推导出事实和维度。
首先你应分层:
t1(ods原始)、t2(dwd明细)、t3(dws汇聚)、t4(ads应用)、公共(dim维度)
你少了一个t2的抽象过程,出现烟囱的几率非常大
解决烟囱的方案在于梳理业务过程:
你画一个excel表,纵向按照顺序描述所有的业务过程(动词),横向枚举所有过程中参与的对象(名词),【事实(量词)是这个业务过程的度,形容词与副词是各种粒度中的修饰】
这样你得到了一个参与者与参与过程组成的矩阵,你清楚的看到那些参与者在哪些过程中参与了,你可以将参与者构建成【维度表】,业务过程构成【事实表】,这样可以避免出现分析一个业务过程使用的参与者和分析另外一个业务过程的参与者出现id不统一的情况【一致性】
业务过程要适度抽象,既不能太粗,也不能太细,比如销售过程,有门店销售,有app销售,这些过程如果分成两个事实表则在汇总出报表的时候计算步骤太多
大概就是这些
1.3 此时,其实分层就已经确定好
{1} 为什么要分层(如何确定层数和每层的职责)?
最理想的情况,上游系统中已经有了想要的指标,此时,直接导入到数仓,或者直接取用即可。
次之,就是指标分析所需要的数据都在一张表中,直接从一张表取数即可。
但现实中,以上2种情况显然这是不可能的。需要自己实现这2种情况,对源数据进行加工。
-
加工,自然存在逻辑复用的问题。为了可扩展、可伸缩。将业务抽象为表和表之间关系后,有些重复的业务逻辑,没必要每次都算,自然需要建个表将这个结果存起来。类似于oracle中存储过程。复用的表多了,自然要需要分类管理,所以就有了DW开头的几层(dwd、dws)。类似于web开发中的dao、service、controller,本质都是为了可扩展、可伸缩。
-
同时,因为数仓面向分析,自然少不了表之间的关联,也就是join,而join是很浪费性能的,所以在数仓中建模,减少join是权重很高的考量因素,ER模型中,为了减少冗余往往遵循三范式,但在数仓中,为了减少join,会使用维度建模的理论,减少join,也就是尽可能的量把需要的数据都放到一张表里。
-
因为现在企业的业务改动很大,事实、维度变动也很大,而维度建模无论是修改还是扩展,都要比范式模型方便
-
数仓的模型有时要直接面向运营和分析人员,维度建模的数据结构更简单,更易于理解。
这也就是为什么要用维度建模而不是ER建模,为什么会有降维、维度退化的问题?
上面是从数据结构的角度分析分层,在实际数据的构建中,分层是跟业务紧密关联的,在维度建模理论的指导下,各个行业、公司都有自己的分层实现,比如阿里的ods、dw*、ads,美团的???
数仓层内部的划分不是为了分层而分层,分层是为了解决 ETL
任务及工作流的组织、数据的流向、读写权限的控制、不同需求的满足等各类问题,当然我们常说的分层也是面向行业而言的,也是我们常用分层方法,但是你需要注意的是分层仅仅是手段而已。
分层和建模的关系
分层和建模分不开,根据业务过程分层,分层控制模型的落地方式。
公共逻辑下沉,复用。
{2} 如何分层?
业务分析的角度:
本质是为了复用、扩展
不至于每个业务都要写个脚本,为了复用
标准实现的角度:
如何评价一个数仓的好坏:稳定性、可扩展性、可溯源、一致性
其实数仓在代码的表现就几个脚本:调度系统上的脚本。
有几个原则:
- ods和上面的集市层必须隔离
所以大公司一般分2个部分,一是基建部门,负责入仓、生成部分dwd,二是应用部分,负责集市层,用来支持不同的的集市。
===》
3层是必须有的:
ods是贴源层,直接照搬
dwd层,注意:维度建模不是只在这一层,但维度建模的基本的事实表、维度表在这一层。
ads层
维度 + 明细 = 维度建模
{3} 分层效果

数仓层级分成ODS、DWD、DWS、DIM、EDM四层。
ODS 贴源层,保持数据原生态,含历史信息表,一般为分区表;
DWD 数据仓库明细层,在贴源层的基础上过滤、清洗、解析成不同的事实表;
DWS 数据仓库公共指标汇总层,基于DWD层提取公共指标,合并公共指标计算逻辑;
EDM(ADS) 数据集市层,面向业务,给数据应用提供统计指标数据。
DIM 公共维度层,提取公共维度,保证维度一致性。
1.4 维度建模
{1} 为什么要用维度建模,ER模型的局限??
维度建模是自下而上的,需要什么就入仓什么,而er模型是自上而下的,需要把所有数据入到数仓然后构建一个实体模型。前者输出数据产品比较快,数据冗余多,烟囱式开发严重;后者输出产品较慢,构建数仓过程长,数据冗余少,烟囱式开发少。面对业务快速变化的背景,用er模型的难度较大,重构可能更大,而且大数据背景下,用hive构建的数仓因为hive本身的特点,不太好支持代理键的设计方式,更加擅长数据的冗余,因为分布式背景下存储不是问题。这也是为什么数仓发展到现在,数据质量问题越来越严重,所以才会有Onedata的出现。
-
适配大数据的处理方式
维度模型的非强范式的,可以更好的利用大数据处理框架的处理能力,避免范式操作的过多关联操作,可以实现高度的并行化。
数据仓库大多数时候是比较适合使用星型模型构建底层数据Hive表,通过大量的冗余来提升查询效率,星型模型对OLAP的分析引擎支持比较友好,这一点在Kylin中比较能体现。
雪花模型在关系型数据库中如MySQL,Oracle中非常常见,尤其像电商的数据库表。 -
自下而上的建设现状
表已经存在,业务已经开发完毕,需求直接提过来了,这几乎是一个普遍现状,因为很少有公司会提前成立数据部门,让数据部门跟随着业务从头开始一直成长,都是当业务发展到一定的阶段了,想通过数据来提高公司的运营效果 -
简单的模型 使用简单,迭代比较快速,比范式建模要简单易上手
这个模型相对来说是比较简单的,简单主要体现在两个方面
维度建模非常直观,紧紧围绕着业务模型,可以直观的反映出业务模型中的业务问题。不需要经过特别的抽象处理,即可以完成维度建模。这一点也是维度建模的优势。
星型结构的实现不用考虑很多正规化的因素,设计与实现都比较简单。
er模型设计流程比较长,不是来一个需求就做一个,而是面向整个业务,而hive因为冗余,这也意味着更灵活。
2种维度建模区别???
olap放在数仓内还是外,数据集市是否物理存在。
集市和数仓分离
kmball,集市和数仓放在同一套多维分析的数仓里,在上面架一些查询引擎。
流程分析
建模的小例子
一次网购引起的建模思考
购物小票核心信息:商品、单价、数量、总价
思考过程:
业务组成:人、货、场
借鉴ER模型进行业务矩阵拆解
实体:用户、商家、商品
关系:浏览、营销(活动)、订单、结算
建设思路
三大数据域建设:交易数据域、流量数据域、用户数据域
交易域:
优先建设订单相关,进而方便业务方查看日常交易信息以及财务盈亏信息。
其次建设商家相关,方便业务做商家运营(有C端必有B端)。
最后基于业务发展阶段以及业务的经营框架进行模型建设。
流量域:
切分子主题,做路径转化、漏斗转化、实验效果等分析模型
用户域:
基于AARRR以及RFM切分场景化的建设思路。
Q&A
-
er、维度建模、DV、anchor、图模型
-
维度建模不是只在dwd层,即使存在一些公共维度的退化,也是维度建模,dws层也有可能依赖dim层。
-
跟业务紧密相关,比如为啥媒体行业不能建很多层?
数仓分2种,业务数仓、用户行为数仓,零售业务复杂,是业务数仓 +用户行为数仓。媒体的用户行为很多,看新闻事件多,业务少,最多点个赞,分层不重要,计算很多,重计算,轻模型,层数3、4层即可,业务过程少,主题少,专题多。媒体不是完全面向主题,零售一般都是互联网公司,面向所有流量。 -
如何建模
- 建事实表:
如何设计事实,如何设计度量。判断一个事实表设计的好,就是抽象的怎么样,下游是否都能用到。
事实里面分事务,事务就是业务过程的操作,一个事实表可以用一或多个事务。所以事实表分单、多事务事实表。
比如提交订单、比如付款方式、补贴方式,多事务,每个事务都是一个动作。 - 建维度表:
如何确定维度?
全盘分析完会得到业务矩阵中的列就是维度,维度是看问题的角度,形成业务矩阵之后,维度其实就确定了。 - 影响建模的因素
- 调度工具?
- 建事实表:
1.5 全盘分析完会得到业务矩阵,相当于分析报告,然后会编写模型的mapping文件

数据构建
二、数仓构建
1. 如何分层,如何确定分几层(3、4、5)
分层和建模分不开,都是逻辑上的,根据业务过程分层,分层控制模型的落地方式。
业务分析的角度:
本质是为了复用、扩展
标准实现的角度:
如何评价一个数仓的好坏:稳定性、可扩展性、可溯源、迷瞪、一致性
数仓的表现就几个脚本:调度系统上的脚本。
3层是必须有的:
ods是贴源层,直接照搬
dwd层,维度建模只在这一层?因为维度建模,所以要建事实表、维度表。
2. 维度建模(不仅仅只有dwd)
维度建模
即使存在一些公共维度的退化,也是维度建模,dws层也有可能依赖dim层。
跟业务紧密相关,数据建设负担,为啥媒体行业不能建很多层:数仓分2种,业务数仓、用户行为数仓,零售业务复杂,是业务数仓 +用户行为数仓。媒体的用户行为很多,看新闻事件多,业务少,最多点个赞,分层不重要,计算很多,重计算,轻模型,层数3、4层即可,业务过程少,主题少,专题多。媒体不是完全面向主题,零售一般都是互联网公司,面向所有流量。
全盘分析完就是业务矩阵
ads层:指标计算
3. 如何建模
建事实表:
如何设计事实,如何设计度量。判断一个事实表设计的好,就是抽象的怎么样,下游是否都能用到。
事实里面分事务,事务就是业务过程的操作,一个事实表可以用一或多个事务。所以事实表分单、多事务事实表。
比如提交订单、比如付款方式、补贴方式,多事务,每个事务都是一个动作。
建维度表:
如何确定维度:根据业务?
事实表和维度表的对应关系:

4. 数仓规范
分析完,首先要有数仓的构建规范,每层怎么命名,事实表、维度表是啥,度量是啥,是业务库的度量,没生成指标前是度量,是业务数据库本身带的,不在维度建模里面叫度量,经过加工,即使原样,变成指标。
业务数据库入仓,ods,er模型
dwd开始分事实表,维度表。
如果不是新建数仓,要探查这数据是否存在,已有的事实表是否完整,是否能支撑需求,第三SLA(一个约定,产品几点出,跟产品经理沟通),数据量,我的产品要输出,要考虑何时输出,时间点
第四,数据质量DQC,数据可能有问题,数据是错的
5. 需求
6. 技术评审,起了一个数据开发任务,技术评审文档。
7. 然后开始开发。哪些域、哪些主题?
核心指标的计算口径和流程图,结果,
风险的兜底方案:SLA、DQC如何保证。兜底就是如果出现延迟、数据有问题要怎么办。
跟产品对一遍,再跟技术(数仓团队)过一遍,指标是否有问题,模型是否合理
然后才开始建表,跑批,输出。
8. 开发流程、模型都有了,剩下的就是技术相关的了。
{1} 大方向:实时还是离线,是否是即席查询
如果是离线,T+1还是T+N,离线用hive,风险点,比如用流量的数据,数据很大。
数据放在OLAP里面给应用方查,比如CK,麒麟。还是集市数仓都在hive里面,用impala等即席查询。
{2} 2种架构区别
2个模型的区别
集市和数仓分离
kmball,集市和数仓放在同一套多维分析的数仓里,在上面架一些查询引擎。
即席查询不管是给用户、运营看,除了看,还要分析,要多维分析,所以需要即席查询。所以需要一个东西来承接,
比如麒麟,把需要的维度放到hbase,提前算好了。空间换时间
内存、性能换时间,比如impala、spark、presto。
前端用报表还是接口展示都行。
实时
要考虑的点:
实时还是准实时,
实时就是流,产生就消费
=》技术解决方案,flink + kafka
准实时:延迟比较大,sparkstreaming
如果用flink,怎么分层,用sql还是flink代码。
此时离线和实时数据都有了,要考虑用什么架构
,有2个。lambda架构,把离线和实时合并,计算入口曝光,把昨天和实时的加起来,都是当前的入口曝光。可加指标都可以用lambda架构。
指标有可加、半可加、不可加。
比如活跃用户数,昨天和今天可能是同一个人,跨维度跨时间不可累加。lambda优点实时性能好,只计算(一个窗口内的数据,不能是所有),但部分指标无法做到。对同一个指标的计算口径离线和实时都有,要修改就要同时改,否则会有数据质量问题。
kappar架构,只有实时,没有离线,全部依赖消息队列,优点:什么指标都可以算,架构比较简单,只有一套实时。
缺点:消息队列压力大;指标不可能全部依赖实时。
流批一体
不是lambda,不是把离线实时结果放一起。而是2种的计算口径统一,把lambda离线实时路径缩短,都只到dwd层,指标口径放在dws和ads。这个地方需要存的多,速度快,并发性能好。hsap集服务和分析一体的混合结果,代表就是阿里的hologres。离线和实时都到dwd,然后放到hologres中实现批流一体。
数仓构建流程
- 去实现数据驱动的能力
- 顶层设计,业务分析
- 入仓
- 数据源有哪些
- 业务系统
- 文件:
- 日志
- 一般都是非结构化、半结构化
- 2种入仓的工具也不同(选型)
- 业务系统:datax、sqoop、kettle
- 文件 :flume
- 数据源有哪些
- 调度
- 想让数据跑起来,必然要把一个点一个点组织起来,形成任务流。
- 工具:azkaban、airflow、海豚
- 有了入仓和调度,会有很多问题
- 全量、增量、快照
- 缓慢变化维:拉链表、提新
- hive不能updata和delete。重跑、处理历史问题、多路输出(union all)
- 存储格式
- 参数优化
- 数据漂移
- 项目
- 媒体
- 零售
- 此时数据流向就有了,此时还有很多问题
- 数据治理:
- 能影响计算的:
- 数据质量DQC
- 完整性、一致性、及时性、准确性
- 为啥还没出来,为啥跟源库的不一样,为啥跟预测的不一样,为啥有的地方有,有的地方没有
- Griffin
- 完整性、一致性、及时性、准确性
- 元数据管理
- 如果有个指标计算结果有问题,如何溯源?如果程序员离职了咋办?
- 元数据不局限,表、指标、库,日志、etl任务也是。
- 数据血缘图,看到某个指标,就知道其上游涉及到什么表,解析sql(insert,from的是谁)(跟任务无关,跟脚本无关,只有表的血缘,没有任务血缘,目前还没有字段血缘,只有表血缘,都知道指标了和表了,肯定知道字段)
- Atlas
- SLA
- 服务约定,针对数仓etl任务的约定执行时间
- 比如凌晨5点,所有数据到岗
- 这个很重要,数据都是给领导和运营看的
- 命名规范
- 表
- 任务
- 指标
- 业务生成模型,生成之前要有命名规范
- 能影响存储的
- 数据存储的时长
2. 数仓的搭建
2.1 分析完,此时已经明确了分层,建模。此时就要把这些设计落实为库、表、表之间的关系。
-
首先要有数仓的构建规范,每层怎么命名,事实表、维度表是啥,
度量是啥?是业务库的度量,没生成指标前是度量,是业务数据库本身带的,不在维度建模里面叫度量,经过加工,即使原样,变成指标。 -
业务数据库入仓,ods,er模型
dwd开始分事实表,维度表。 -
数据探查
如果不是新建数仓,要探查这数据是否存在,已有的事实表是否完整,是否能支撑需求,第三SLA(一个约定,产品几点出,跟产品经理沟通),数据量,我的产品要输出,要考虑何时输出,时间点
第四,数据质量DQC,数据可能有问题,数据是错的 -
需求,技术评审,起了一个数据开发任务,技术评审文档。
然后开始开发。哪些域、哪些主题
核心指标的计算口径和流程图,结果, -
风险的兜底方案:SLA、DQC如何保证。兜底就是如果出现延迟、数据有问题要怎么办。
跟产品对一遍,再跟技术(数仓团队)过一遍,指标是否有问题,模型是否合理
然后才开始建表,跑批,输出。
2.2 开发流程、模型都有了,剩下的就是技术相关的了,技术选项 + 确定入仓、存储、计算、同步等方案。
{1} 大方向:实时还是离线
如果是离线,T+1还是T+N,离线用hive,风险点,比如用流量的数据,数据很大。
数据放在OLAP里面给应用方查,比如CK,麒麟。还是集市数仓都在hive里面,用impala等即席查询。
{2} 是否需要即席查询
[1] 即席查询
{3} 数仓的组件
2.3 此时离线和实时都可以跑了,如果是实时,要考虑用什么架构:3种区别

有3个。
lambda架构,把离线和实时合并,计算入口曝光,把昨天和实时的加起来,都是当前的入口曝光。可加指标都可以用lambda架构。
指标有可加、半可加、不可加。
比如活跃用户数,昨天和今天可能是同一个人,跨维度跨时间不可累加。lambda优点实时性能好,只计算(一个窗口内的数据,不能是所有),但部分指标无法做到。对同一个指标的计算口径离线和实时都有,要修改就要同时改,否则会有数据质量问题。
kappa架构,只有实时,没有离线,全部依赖消息队列,优点:什么指标都可以算,架构比较简单,只有一套实时。
缺点:消息队列压力大;指标不可能全部依赖实时。
Kappa架构最大的还有个问题是流式重新处理历史的吞吐能力会低于批处理,但这个可以通过增加计算资源来弥补
混合架构(流批一体):
即席查询不管是给用户、运营看,除了看,还要分析,要多维分析,所以需要即席查询。所以需要一个东西来承接,
比如麒麟,把需要的维度放到hbase,提前算好了。空间换时间
内存、性能换时间,比如impala、spark、presto。
前端用报表还是接口展示都行。
2.4 流程
- 入仓
- 数据源有哪些
- 业务系统
- 文件:
- 日志
- 一般都是非结构化、半结构化
- 2种入仓的工具也不同(选型)
- 业务系统:datax、sqoop、kettle
- 文件 :flume
- 数据源有哪些
- 调度
- 想让数据跑起来,必然要把一个点一个点组织起来,形成任务流。
- 工具:azkaban、airflow、海豚
- 有了入仓和调度,会有很多问题
- 全量、增量、快照
- 缓慢变化维:拉链表、提新
- hive不能updata和delete。重跑、处理历史问题、多路输出(union all)
- 存储格式
- 参数优化
- 数据漂移
- 项目
- 媒体
- 零售
- 此时数据流向就有了,此时还有很多问题
- 数据治理:
- 能影响计算的:
-
数据质量DQC
- 完整性、一致性、及时性、准确性
- 为啥数据量少了,为啥跟源库的不一样,
- 为啥有的地方有,有的地方没有
- 为啥还没出来,
- 为啥跟预测的不一样,
- Griffin
- 质量监控大盘
- 事前
规范
测试 - 事后
- 数据监控
- 异常值
- 指标
- 同环比
- 方差、标准差
- 时间序列
- 数据监控
- 事前
- 完整性、一致性、及时性、准确性
-
元数据管理
- 数据血缘
- 元数据不局限,表、指标、库,日志、etl任务也是。
- 数据血缘图,看到某个指标,就知道其上游涉及到什么表,解析sql(insert,from的是谁)
- 指标管理
- 如果有个指标计算结果有问题,如何溯源?如果程序员离职了咋办?
- Atlas
- (跟任务无关,跟脚本无关,只有表的血缘,没有任务血缘,目前还没有字段血缘,只有表血缘,都知道指标了和表了,肯定知道字段)
- 数据血缘
-
SLA
- 服务约定,针对数仓etl任务的约定执行时间
- 比如凌晨5点,所有数据到岗
- 这个很重要,数据都是给领导和运营看的
-
命名规范
- 表
- 任务
- 指标
- 业务生成模型,生成之前要有命名规范
-
- 能影响存储的???
- 数据存储的时长
- 数据是否被使用(删除不被使用的数据)
- 数据是否可以被压缩(冷热数据的处理)
- 数据存储是否合理(快照表是否可以改成全量或者增量)
- 能影响计算的:
3. 业务逻辑和技术常见问题
{1} 缓慢变化维
- 什么是?
维度表信息有更新的情况。因为有更新,会根据数据量大小和应用场景来选择如何处理。
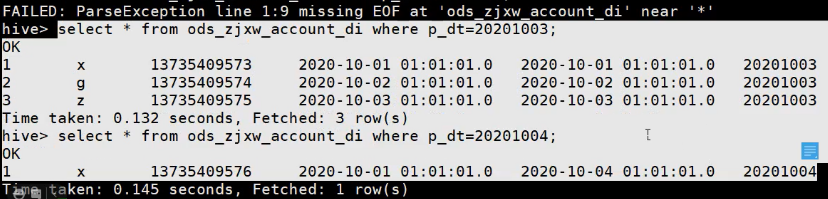
一条数据更新后,在第二天导入时,根据一般的导入策略,会新产生一条。此时20201003分区存的是旧的,20201004分区存的是新的。那么,这2条数据该怎么用呢???以下是处理方式: - 该怎么用呢?
增、全、快照都是缓慢变化维的一种方式。
- 全:直接覆盖,没有分区
- 增:添加新行
比如媒体行业,不关心历史数据,则取最新的即可。231
如果是金融行业,要下订单的。1231,全部4条都要,而且还要知道每条数据的有效区间,也就是状态,需要添加有效期的字段 - 增加新列:一般不用。不知道缓慢变化会变化哪些指标
- 快照:每个分区都是全量,比如每天一个快照
- 拉链:保留历史状态,多状态用拉链
https://blog.csdn.net/silentwolfyh/article/details/89361785
如下,每条数据都是有状态的。
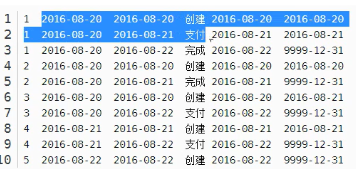
缺点:维护太麻烦,需要更新???
[1]
缓慢变化维
维度表里面的数据并非是始终不变的,总会随着时间发生变化。更新的时候主要有三种方法。
-
直接
UPDATE。与业务数据保持一致。 -
新增一条记录,ID不变,其他字段为修改后的信息。(这样能记录历史变化的信息)
但由于是新增的一条且ID相同,在统计时会重复计算两条数据,所以要加一个新的主键,叫
代理键, 即用来代替原本的ID键作为唯一字段。此外,往往还需要新增时间列,这样就能记录什么时间段内,这条记录是有效的,什么时间段变成另外一个值。同时也能记录到底是
a->b还是b->a -
有时,需求并不是需要那么详细,只需要记录两次内(有限次)的变化时,可以在加多个字段实现。
id name value value1 value2 1 陈 100 200 150 -
将个别容易变化的维度(有限的)抽离出来,单独构建成RFM微型维度,并在相关事实表中增加RFM键作为外键。
-
(1+4) 将抽离出来的维度ID放到事实表作为外键,以
UPDATE的方式更新。 -
(1+2+3) 每次变化,将更新当前行标识字段(1),新增一条记录(2), 更新历史字段和当前字段(3)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JATc5b2B-1612424015250)(img/weidu2.png)] -
将维度代理键分离出来作为事实表外键,维度的自然键也同时作为事实表外键。这样就有双重外键。更新时,同时新增维度表记录和事实表记录。(感觉有点麻烦)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tAEVFuib-1612424015251)(img/weidu3.png)] -
快照表,每天(每月)从事实表中复制一份,存为当前时间的分区。以空间换时间。
-
历史拉链表,相比(2)少了代理键,相比(8)降低了存储。
{2} 数据漂移
- 是什么?
1004的数据被更新到了1005,因为埋点网络延迟(发生时间和日志产生时间),入仓程序延迟等。
2个时间字段不一样,比如绿金中的etl_date和首次提交时间。
通常我们把从源系统同步进入数据仓库的第一层数据成为ODS层数据,我们公司目前只有ODS一层,虽说只有一层,但是仍然有有一个顽疾:数据漂移,简单来说就是ODS表的同一个业务日期数据中包含前一天或者后一天凌晨附近的数据或者丢失当天的变更数据。更新表来说会丢失变更数据,流水表一般会丢失上一天数据,或者说上一天数据漂移到下一天。
由于ODS需要承接面向历史的细节数据查询需求,这就是需要物理落地到数据仓库的ODS表按时间段来进行分区存储,通常的做法是按某些时间戳字段来切分,二实际上往往由于时间戳字段的准确性问题导致发生数据漂移。 - 解决
大数据之路:15分钟
1)多获取后一天的数据
既然很难解决数据漂移的问题,那么就在ODS每个时间分区中向前、向后多冗余一些数据,保证数据只会多不会少,而具体的数据切分让下游根据自身不同的业务场景用不同的业务时间proc_time来限制。但是这种方式会有一些数据误差,例如一个订单是当天支付的,但是第二天凌晨申请退款关闭了该订单,那么这条记录的订单状态会被更新,下游在统计支付订单状态时会出现错误。
(2)通过多个时间戳字段限制时间来获取相对准确的数据
1> 首先根据log-time分别冗余前一天最后15分钟的数据和后一天凌晨开始15分钟数据,并用modified_time过滤非当天数据,确保数据不会因为系统问题而被遗漏
2>然后根据log_time获取后一天15分钟的数据;针对此数据按照主键根据log_time做升序排列去重,因为我们要获取的是最接近当天记录变化的数据(数据库日志将保留所有变化的数据,但是落地到ODS表的是根据主键去重获取的最后状态的数据)
3>最后将前两步结果数据做全外连接,通过限制业务时间proc_time来获取我们所需要的数据
{3} hive
-
分区分桶
-
内外表
-
映射表
-
多路输出
from (select * from tabl_name) a
insert into table table_name1insert into table table_name2 insert into table table_name3 -
执行引擎
三、实现驱动、赋能
此时数仓不仅能运行跑出结果,还能保证正确。此时需要提供给应用层。怎么实现、以何种方式驱动、赋能?
报表
常规的数据输出方式。
反映运营效果。告诉领导、运营 效果如何。
- 比如核心指标:新客,成交量,补贴用了多少。
给出指标异动分析报告
- 还要给出指标异动的原因,比如新客少了
预警
- 用户留存、用户流式来体现用户流式预警
推荐系统
比如抖音,在刷的过程中采集用户数据,再推荐,给业务赋能,让用户一直粘在抖音里。
用户画像
比如判断某种商品的用户的年龄、性别、区域。让数据驱动
数据同步到业务系统数据库
数据API
数据集市
数据应用:ai模型
技术点
数据同步
数据倾斜
优化















 1446
1446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









