







一、项目背景
1、项目概况:
前期将业务库中,数据全部都落地到了Hbase当中的四张表(order_info", "renter_info", "driver_info", "opt_alliance_business)里面去了,
针对Hbase中的四张表:车辆表、用户表,订单表以及司管方表 ,进行统计分析,
实现步骤:
- 1) 自定义sparkSQL数据源**,读取Hbase业务表数据 ,直接生成DataFrame;
- 2)DataFrame注册成表 并进行缓存后,进行SparkSQL查询分析,写SQL ;
- 3)SparkSQL查询分析,测试好每一条SQL后,合并成一个大SQL,查出关于用户的所有主题, 返回dataFrame。
- 4) sparkSQL的数据保存,将统计的结果保存到Hbase里面去
2、spark读hbase三种方式:
- 1、
context.newAPIHadoopRDD==> RDD ==>转换成为rdd里面包含样例类, ==> 转换成为DF ==> 写sql- 数量量大,scan在客户端过滤查询,效果不好,regionserver容易挂
- 2、hive整合hbase,sparkSQL整合hive
- 3、自定义数据源,继承
DataSourceV2类,重写createReader方法,- 也是使用了scan,但涉及到RDD的底层,使用了谓词下推和列剪枝,在服务端执行过滤,性能好一些
- 自定义sparksQL的数据源,目的就是通过sparksQL中的逻辑优化阶段Optimizer,实现谓词下推以及列剪枝
- 列剪枝: 就是select 列,对于没用到的列,则没有必要读取它们的数据去浪费无谓的IO,在hive调优中也有,
- 谓词下推:谓词就是我们的查询条件 where。谓词下推,将查询条件尽可能下推到距离数据源最近的地方,推到服务端去执行。
3、统计指标:
平台层rowkey: 园区id+时间戳,
具体车辆层面rowkey:车辆id+时间戳
时间维度,日周月年
园区维度,+ 平台
日:date_format(last_logon_time,‘yyyy-MM-dd’) = ‘2019-07-15’
周:weekofyear(date_format(last_logon_time , ‘yyyy-MM-dd’)) = ‘29’
月:date_format(last_logon_time , ‘yyyy-MM’) = ‘2019-07’
1)平台层用户统计
- rk : 园区id()+每天时间戳: value: 当前园区的用户统计指标
- 当日/周/月/季度,用户新增、活跃、留存、以及总数
- 乘客表renter_info:乘客id, 乘客姓名,电话,createTime、last_logon_time
2)平台层车辆统计
- rk : 园区id()+每天时间戳: value: 当前园区的车辆统计指标
- 当日/周/月/季度,车辆新增、车辆总数、 车辆类型数,
- 司机表driver_info:司机id 、电话、车辆id、车辆类型、createTime、last_lo
3)平台层订单统计
- rk : 园区id()+每天时间戳: value: 当前园区的车辆统计指标
- 当日/周/月/季度,有效订单数,全部订单数、订单的完成率、收入金额、订单车辆类型
-订单表order_info:订单id, 车辆id、乘客id、订单类型(0实时订单1预约订单)、订单状态cancel:(0未取消,1用户取消,2司机取消,3超时未接单)、订单里程、支付费用、行驶花费时间、订单创建时间、完成时间
4)具体层面车辆分析:
-
rowkey: 车辆id+时间戳,
-
当日/周/月/季度,该车辆的有效订单,全部订单数、订单的完成率、收入金额、 车辆行驶公里
-
订单表order_info:订单id, 车辆id、乘客id、订单类型(0实时订单1预约订单)、订单状态cancel:(0未取消,1用户取消,2司机取消,3超时未接单)、订单里程、支付费用、行驶花费时间、订单创建时间、完成时间
-
select 园区id,count() from order where 时间group 园区
二、sparkSQL 采集存储hbase数据
1、Spark数据源 API
Spark 1.3 引入了第一版的数据源 API,我们可以使用它将常见的数据格式整合到 Spark SQL 中。但是,随着 Spark 的不断发展,这一API 也体现出了其局限性,故而 Spark 团队不得不加入越来越多的专有代码来编写数据源,以获得更好的性能。
Spark 2.3 中,新一版的数据源 API 初见雏形,它克服了上一版 API 的种种问题,原来的数据源代码也在逐步重写。
DataSourceV1 API由一系列的抽象类和接口组成,它们位于 spark/sql/sources/ interfaces.scala 文件中。
DataSourceV2 API 首先使用了一个标记性的 DataSourceV2 接口,实现了该接口的类,还必须实现 ReadSupport 或 WriteSupport,用来表示自身支持读或写操作。
ReadSupport接口中的方法,会被用来创建DataSourceReader类,同时接收到初始化参数;该类继而创建DataReaderFactory和DataReader类,后者负责真正的读操作,接口中定义的方法和迭代器类似。- 此外,DataSourceReader 还可以实现各类 Support 接口,表明自己支持某些优化下推操作,如裁剪字段、过滤条件等。
WriteSupportAPI 的层级结构与之类似。
这些接口都是用 Java 语言编写,以获得更好的交互支持。
https://blog.csdn.net/shirukai/article/details/88036913
2、sparkSQL自定义数据源,获取Hbase当中的数据
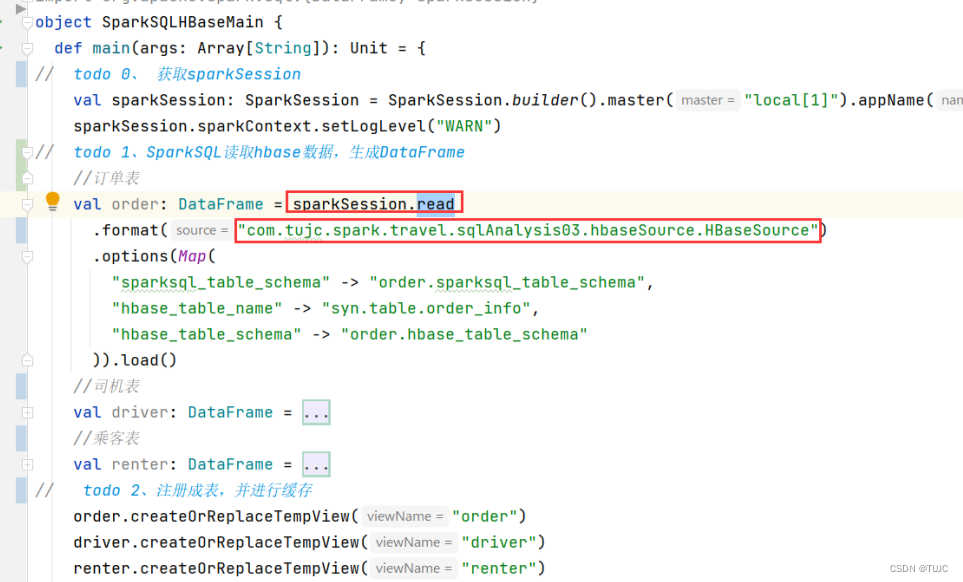
1)自定义一个sparkSql数据源,继承DataSourceV2 类,重写createReader方法,返回一个sourceReader对象。
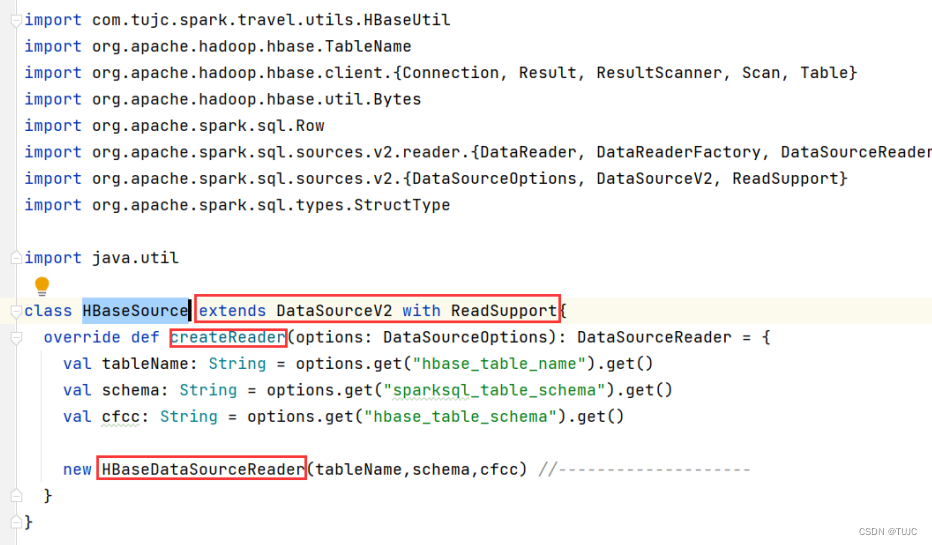
2)自定义一个sourceReader类,继承DataSourceReader 类,重写createDataReaderFactories方法,返回一个DataReaderFactory对象。
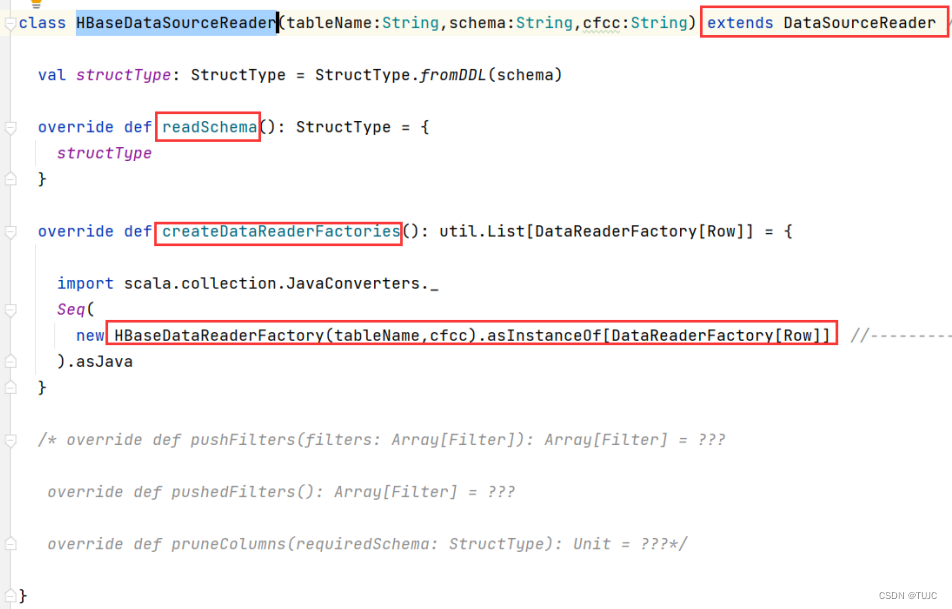
3)自定义一个DataReaderFactory类,继承DataReaderFactory 类,重写createDataReader方法,返回一个DataReader对象。
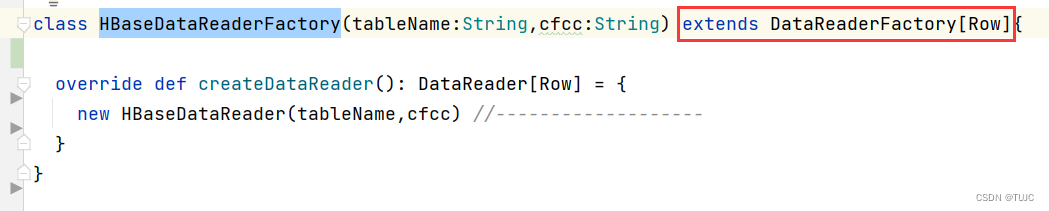
4)自定义一个HbaseDataReader类,继承DataReader[Row] 类,重写next、get、close方法,返回一个Row对象。
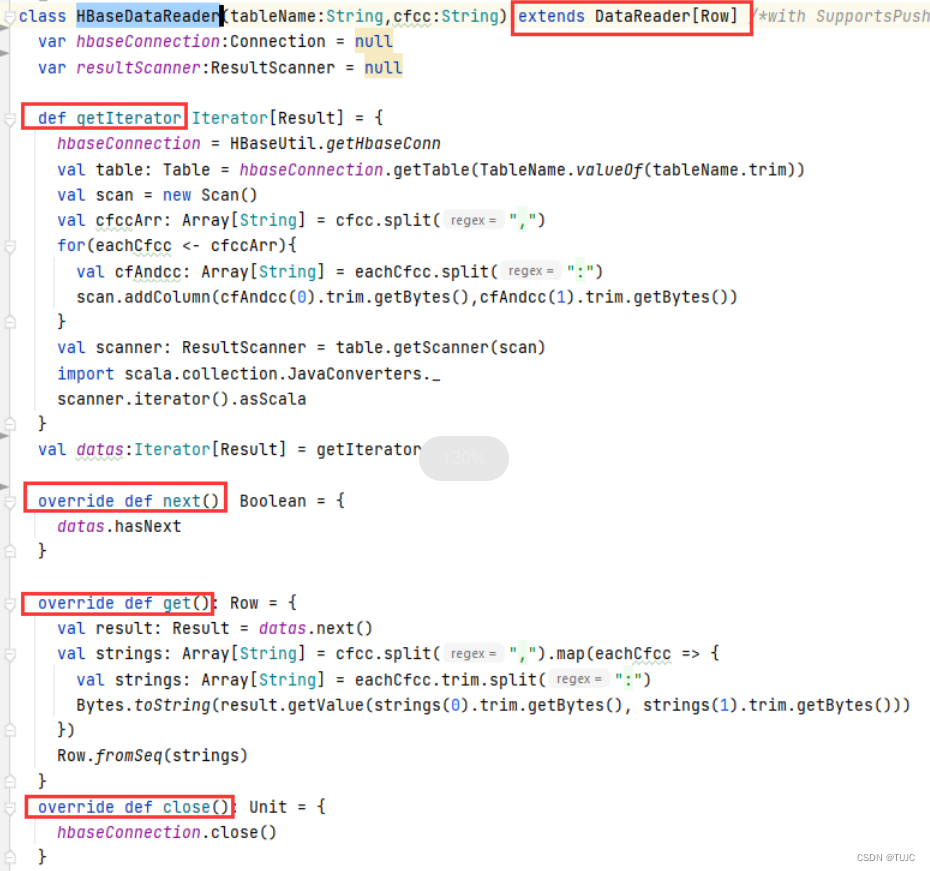
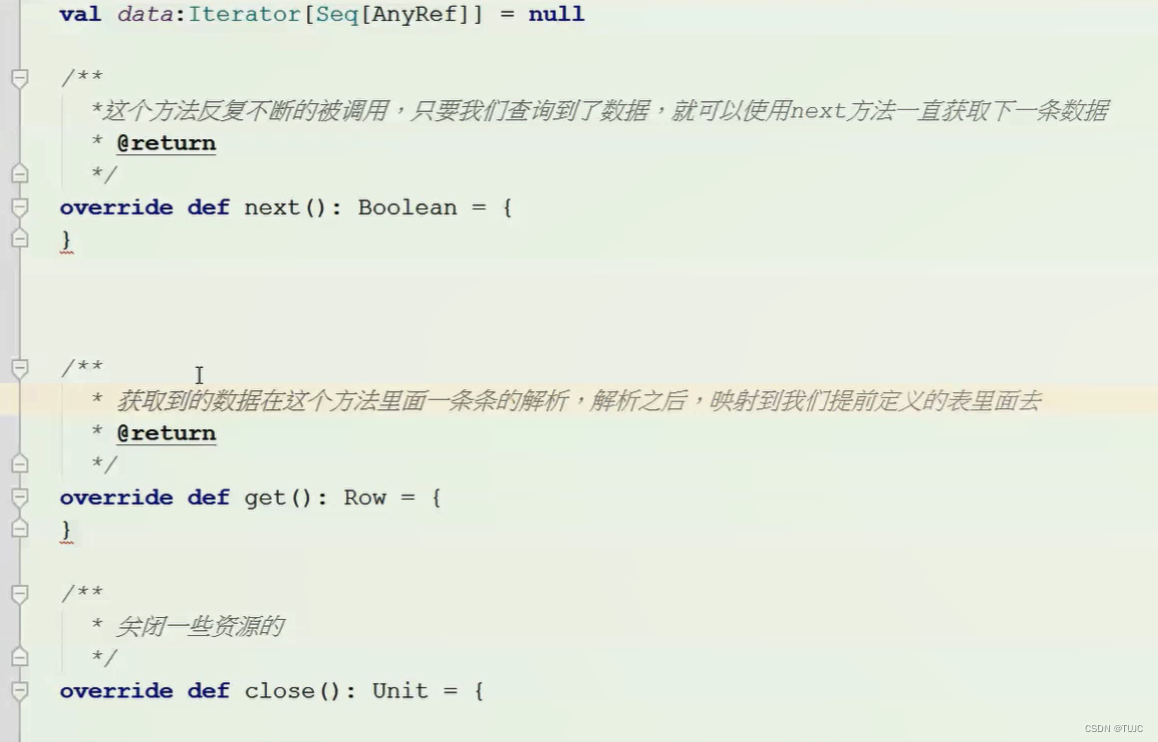
3、sparkSQL自定义输出源,保存数据到Hbase
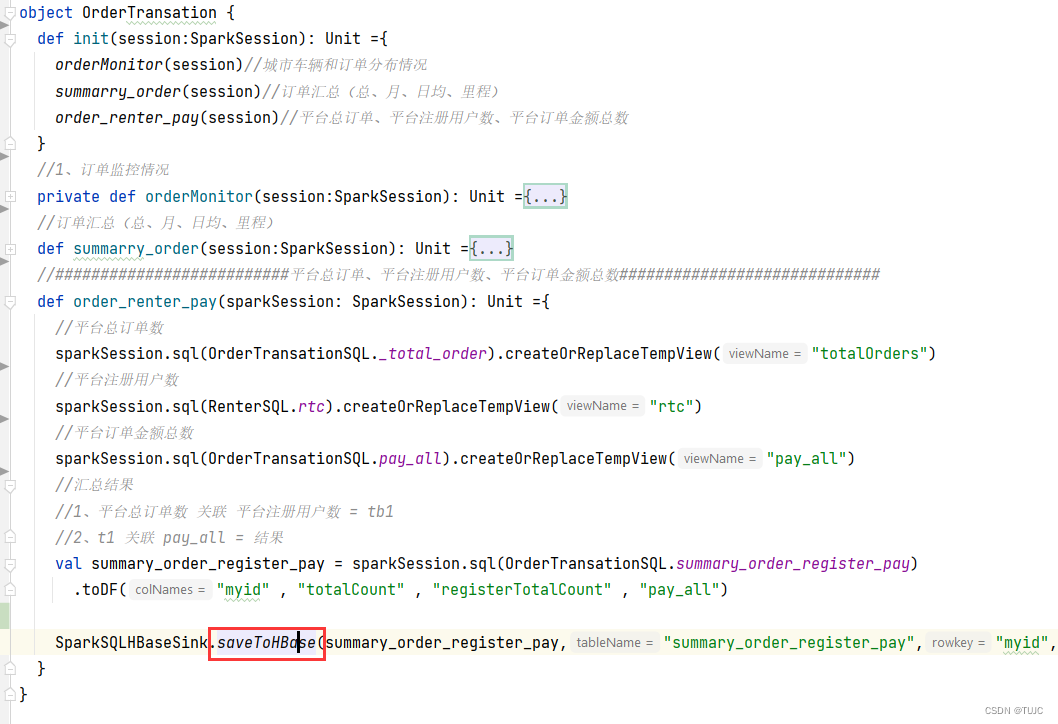
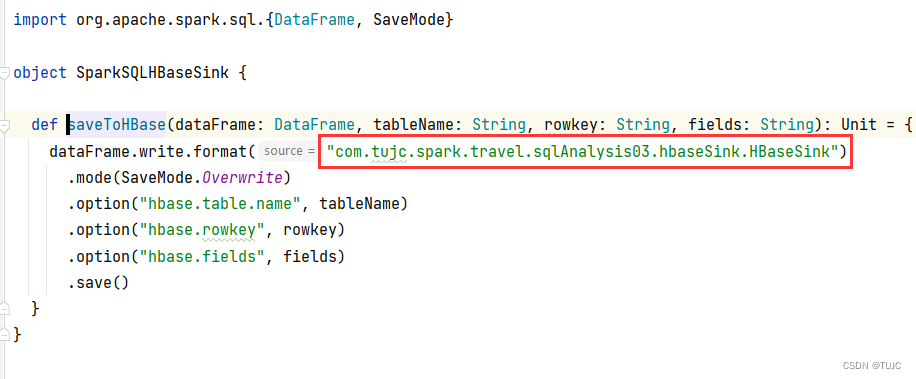
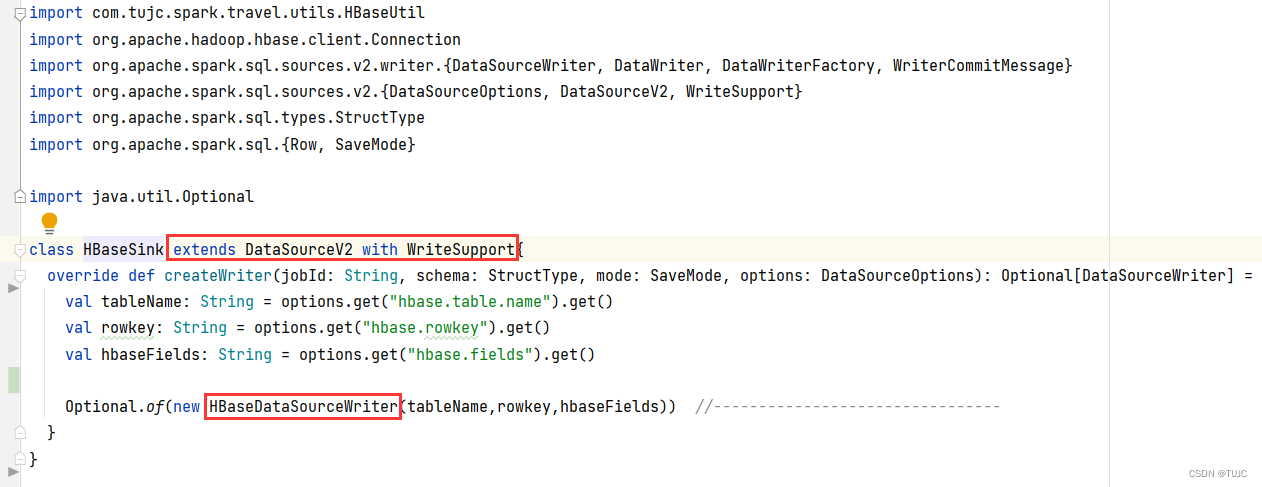
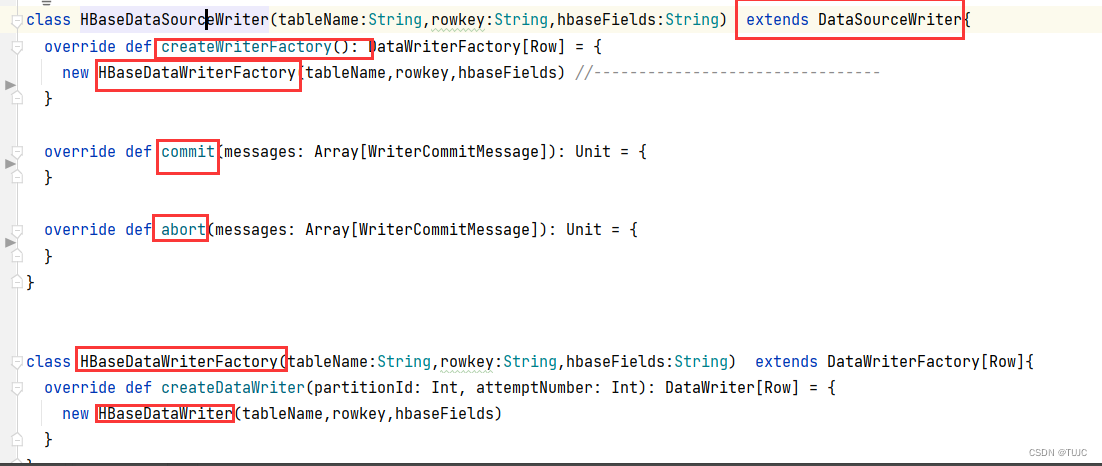

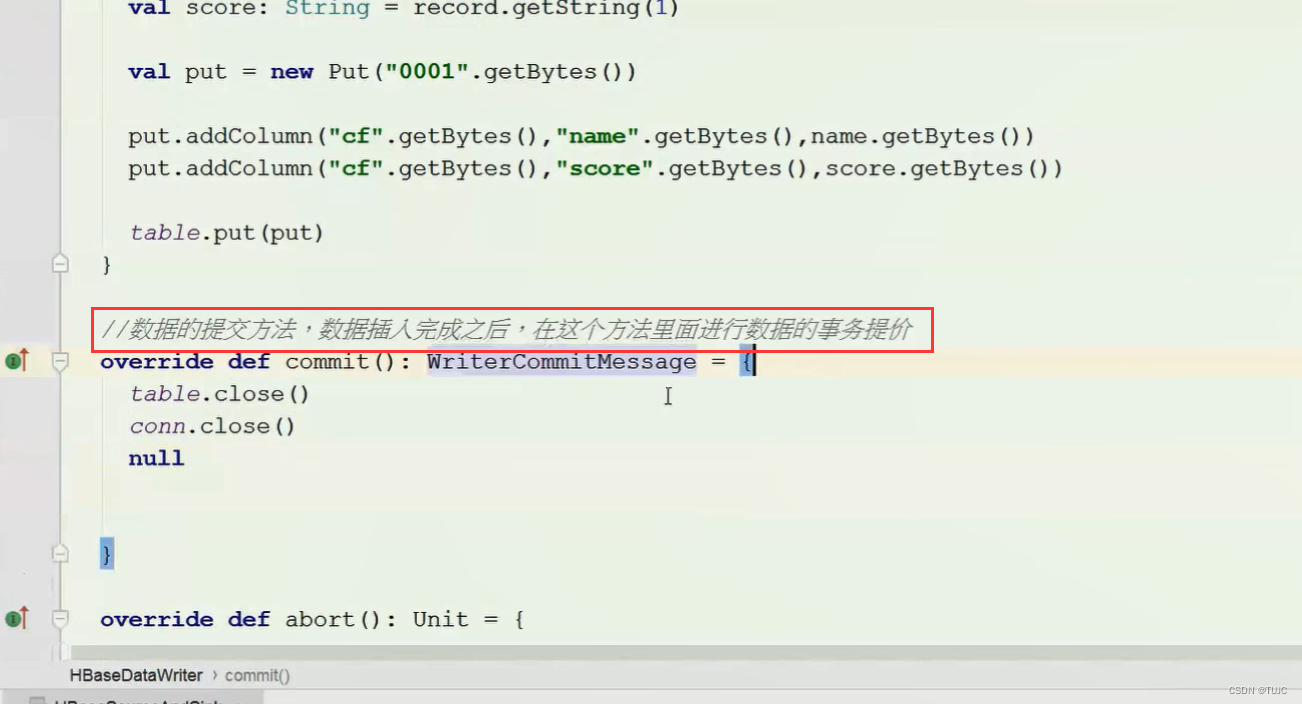
三、SparkSQL
- 1、自定义数据源读取后,形成DataFrame,
- 2、DataFrame注册成相应表,并进行缓存,
- 3、SQL分析查询对应表,保存结果
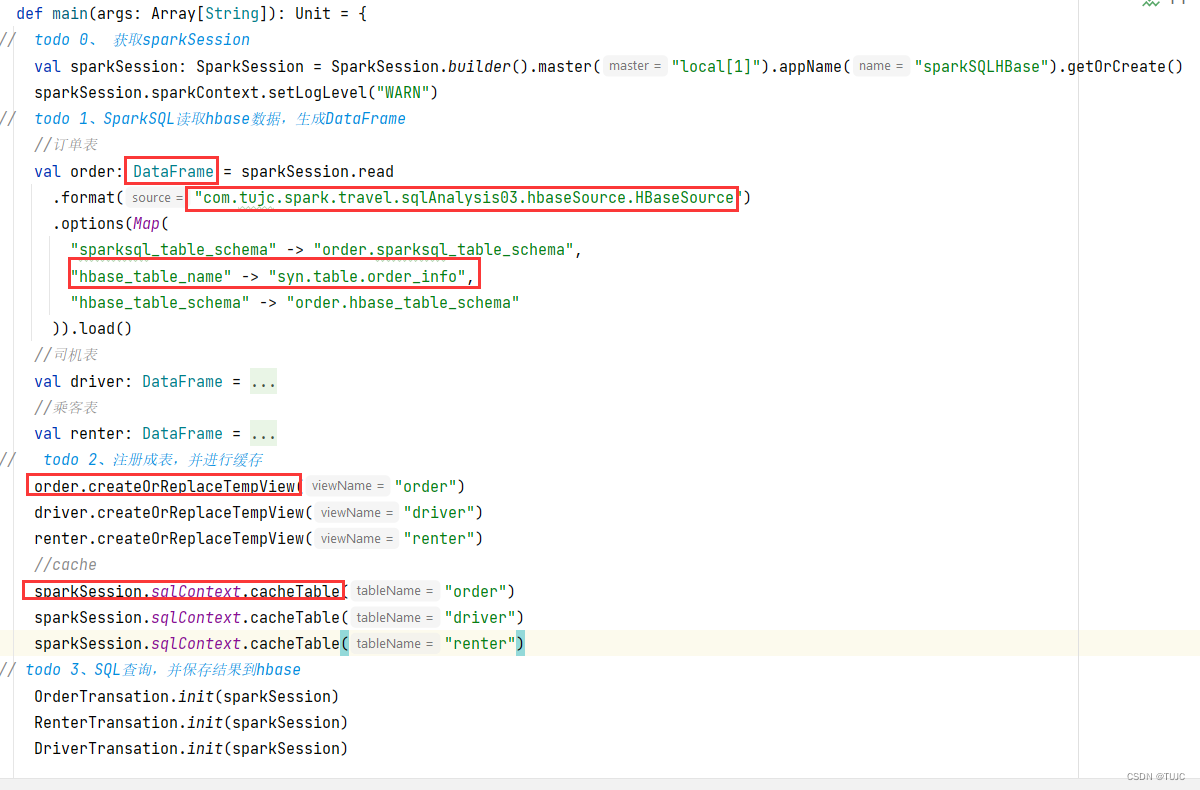
1、平台层用户统计
rk : 园区id()+每天时间戳: value: 当前园区的用户统计指标
(当日/周/月/季度用户新增、活跃、留存、以及用户总数、 连续登录的用户,沉默用户)
表:renter_info用户表
1)新增用户数
create_time
select
substr(last_login_city , 1 , 4) as last_login_city ,
count(1) as _day_new_user
from
(
select last_login_city from renter
where
date_format(create_time,'yyyy-MM-dd') = '2019-07-15'
and last_login_city != ''
) tb group by substr(last_login_city , 1 , 4)
2)活跃用户数
日:date_format(last_logon_time,‘yyyy-MM-dd’) = ‘2019-07-15’
周:weekofyear(date_format(last_logon_time , ‘yyyy-MM-dd’)) = ‘29’
月:date_format(last_logon_time , ‘yyyy-MM’) = ‘2019-07’
select
substr(last_login_city, 1, 4) as last_login_city ,
count(distinct id) DAU
from
(
select last_login_city , id from renter
where
date_format(last_logon_time,'yyyy-MM-dd') = '2019-07-15'
and last_login_city != ''
) tb group by substr(last_login_city, 1, 4)
周:weekofyear
select
1 tmpID ,
count(distinct id) WAU
from renter
where weekofyear(date_format(last_logon_time , 'yyyy-MM-dd')) = '29'
月:date_format(last_logon_time , ‘yyyy-MM’) = ‘2019-07’
select
1 tmpID ,
count(distinct id) MAU
from renter
where date_format(last_logon_time , 'yyyy-MM') = '2019-07'
3)统计次日留存率
select
1 as myid ,
concat(cast( count(tb2.last_logon_time)* 100 / count(tb1.create_time) as string )'%' ) as dayStateRate
from
(
select id , date_format(create_time ,'yyyy-MM-dd') create_time
from renter
where date_format(create_time , 'yyyy-MM-dd') = '2019-07-14'
) tb1
left outer join
(
select id , date_format(last_logon_time , 'yyyy-MM-dd' ) last_logon_time
from renter
where date_format(last_logon_time , 'yyyy-MM-dd') = '2019-07-15'
) tb2
on tb1.id = tb2.id
2、平台层车辆统计
rk : 园区id()+每天时间戳: value: 当前园区的车辆统计指标
当日/周/月/季度新增车辆数、车辆总数、运行里程,
1)新增车辆数
2)车辆总数
3)运行总里程
3、平台层订单统计
rk : 园区id()+每天时间戳: value: 当前园区的车辆统计指标
当日/周/月/季度,有效订单数,全部订单数、订单的完成率、收入金额、平均订单价格
平台,以及各个园区。
订单表order_info:订单id, 车辆id、乘客id、订单状态cancel(0未取消,1用户取消,2司机取消,3超时未接单)、订单里程、支付费用、行驶花费时间、订单创建时间、完成时间、订单类型(0实时订单1预约订单)、
1)有效订单数
cancel = 0
select
city_name ,
count(1) as _effective_num_day
from order
where
date_format(create_time , 'yyyy-MM-dd') = '2019-07-15' and cancel = 0
group by city_name
2)总订单数
cancel = 0
select
city_name ,
count(1) as _effective_num_day
from order
where
date_format(create_time , 'yyyy-MM-dd') = '2019-07-15'
group by city_name
3)当日订单完成率:有效订单/总订单
select
city_name ,
case when _effective_num_day = 0 then '0.0%' else
CONCAT(cast( round( _effective_num_day * 100 / _total_num_day, 2 ) as string), '%' ) end as _day_comple_rate
from
(
select
_effective_order_day.city_name ,
_effective_order_day._effective_num_day ,
_total_order_day._total_num_day
from
_effective_order_day left join _total_order_day on _effective_order_day.city_name = _total_order_day.city_name
) tb
4)订单总额
4、具体层面车辆分析:
rowkey: 车辆id+时间戳,车辆
当日/周/月/季度该车辆的有效订单,总订单数、订单的完成率、收入金额、 车辆行驶公里
order 表
1)该车辆的有效订单
select
driver_id ,
driver_name,
count(1) as _effective_num_day
from order
where
date_format(create_time , 'yyyy-MM-dd') = '2019-07-15' and cancel = 0
group by driver_id , driver_name
2)该车辆总订单数
select
driver_id ,
driver_name ,
count(1) as _effective_num_month
from order
where date_format(create_time , 'yyyy-MM') = '2019-07' and cancel = 0
group by driver_id ,driver_name
3)该车辆的订单完成率
select
driver_id ,
driver_name ,
case when _effective_num_day = 0 then '0.0%' else CONCAT(
cast(
round(
_effective_num_day * 100 / _total_num_day,
2
) as string
),
'%'
) end as _day_comple_rate
from
(
select
_effective_driver_order_day.driver_id ,
_effective_driver_order_day.driver_name ,
_effective_driver_order_day._effective_num_day ,
_total_driver_order_day._total_num_day
from
_effective_driver_order_day left join _total_driver_order_day on _effective_driver_order_day.driver_id = _total_driver_order_day.driver_id
) tb
4)该车辆的订单里程
四、项目经验
1、sparkSQL读取hbase数据方式
以前sparkSQL分析hbase数据,先hive 映射hbase,再sparkSQL整合hive,相当于加了hive一层,
sparksql+hive读取hbase的映射表;效果没有直接读取hbase好
可实现自定义sparkSQL的数据源,直接查询hbase的数据,不需要整合hive了,直接查询出来hbase的数据,映射成为一张表。
自定义sparkStreaming的数据源,需要定义表的结构与hbase的结构能够对应得上,查询hbase哪张表,以及哪些列族,哪些列,都需要提前定义;
最后的HBaseDataReader,还是用scanner取出数据,但是比直接用scanner性能好,涉及到rdd的底层,可以直接做列剪枝,以及谓词下推到服务端去执行。
这和newAPIHadoopRDD的区别是什么,内部不还是获取scan数据,涉及到rdd的底层,可以直接做列剪枝,以及谓词下推到服务端去执行
可以通自定义数据源,不管你是什么样的数据源,都可以通过sparkSQL去查询数据,实现一个大数据的查询平台,
这里不需要批量写入吧?
不需要,每一条数据都是一个Row对象,可以封装到集合里面去,集合满了就批量提交一次,也是一个优化点
自定义sparkSQL的数据源,目的就是实现谓词下推以及列剪枝
列剪枝:简单来说只获取我们需要的数据
谓词下推:在服务端对数据提前进行过滤,将查询条件,推到服务端去执行了
涉及到antlr语法的解析
咨询个问题,phoniex这个的并发和内存消耗大概的范围在多少?
并发看的是HBase支持的并发,hbase天生支持高并发的操作
高并发跟你hbase的集群有关系
例如5台集群,每秒钟来2000个请求应该没问题
手动搭建的hbase集群不支持snappy压缩,如果使用CM,天生支持
按理说 phoniex 也只用到我们后台展示用 自己公司的后台的并发应该不是很大吧 ,按理说不会很大
都不敢投简历,怂
千万不要怂,上去就是干,大不了就删库,不行就跑路,就算进去了,几年之后出来又是一条好汉
kafka0.8版本之前,元数据需要存储到zookeeper中,需要启动zookeeper ;那kafka0.8版本之后,元数据存储到kafka自身上,还需要启动zookeeper ,是由于zk上面保存了broker的信息,以及一些元数据信息,例如topic的信息
2、spark调优:
用到一个共同的配置文件,SparkConf这个对象
sparkcore调优: 调优 关于数据的拉取,以及资源的划分
sparkSQL调优:
sparkStreaming调优:调优 背压机制,以及动态资源划分
sparkStreaming的背压机制:只能保证程序不会宕机,不能解决数据积压问题
spark的资源的动态划分:主要是用于sparkStreaming程序,动态的划分资源了,如果是峰值数据量比较多,spark程序可以自动的多申请一些资源
如果不是高峰期,数据量比较小的时候,可以自动的归还资源
spark的推测执行:与mr的任务一样,也有推测执行
哪有这公司 东风出行
隶属于国企东风集团
30多台的服务器配置如何啊
大数据服务集群给了三十多台:
还有业务服务器,大概给了十几台:
一共五十多台阿里云,全部都开公网:
内存一般都是64到128G的
cpu核数一般都是32核
出行项目的总结:你们来使用xmind总结整个流程图
从日志数据到业务库数据:
flume:
redis:
kafka:
maxwell:
sparkStreaming
sparkSQL
hbase
phoenix
springBoot 了解
线上环境总结:
使用了多少台服务器,每天数据增量
每天的job的个数
以及每天任务运行需要多长时间:
统一发文档出来
















 8066
8066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









