






前言
本篇主要讲解深度学习的基础BP神经网络,结合了其他博客内容。
BP神经网络(反向传播神经网络)是一种用于监督学习任务。BP神经网络是深度学习的基础,是一种最基本的人工神经网络,它由输入层、多个隐层和输出层组成。BP神经网络通过反向传播算法来训练网络,即通过不断调整神经元之间的连接权重,使得网络的输出与标记数据之间的误差最小化。这种算法的核心思想是利用梯度下降法来更新网络中的权重,使得网络能够逐渐学习到输入数据之间的模式和关联性。BP神经网络在许多领域如图像识别、语音识别、预测分析等方面有广泛的应用。
1.基本知识
1.1人工神经网络
人工神经网络(ANN)也简称为神经网络,是一种模仿动物大脑神经网络运行特征,进行分布式并行信息处理的数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。
分布式并行处理是指在人工神经网络中,信息处理过程同时在多个节点之间进行,并且这些节点之间可以相互独立地处理信息。这种并行处理方式有助于加快信息处理速度,并提高网络的效率和性能。
1.2 什么是监督学习任务?
监督学习任务是机器学习中的一种任务,其特点是在训练集中给每个样本(样本即数据)打上标签(标签:每条数据对应的已知结果或类别)。在监督学习任务中,算法会通过学习这些标注数据来构建一个模型,然后用这个模型来预测新的未知数据的结果。
监督学习任务包括分类和回归问题。在分类问题中,算法预测样本属于哪个类别;在回归问题中,算法预测连续数值。监督学习是机器学习中最常见和广泛应用的一种方法。
1.2 激活函数
激活函数是神经网络中的一种函数,用来引入非线性特性,从而使神经网络能够学习并解决复杂的模式。激活函数接收神经元的输入,对它们进行加权和求和,然后将结果输入激活函数以产生神经元的输出,作为下一层神经元的输入。
作用包括:
- 引入非线性:激活函数引入了非线性特性,使得神经网络具备了学习和表示复杂模式和关系的能力。如果没有激活函数,多层神经网络将等同于单层线性模型。
- 支持网络学习复杂函数:通过使用非线性的激活函数,神经网络可以学习和表示各种非线性函数,从而提高模型的表达能力。
- 解决梯度消失问题:某些激活函数能够有效地缓解梯度消失问题,有助于训练深层神经网络。
- 输出范围控制:激活函数可以控制神经元输出的范围,确保在适当的范围内。例如,Sigmoid激活函数将输出值缩放到0到1之间,而tanh函数将其缩放到-1到1之间。
1.2.1常见的激活函数
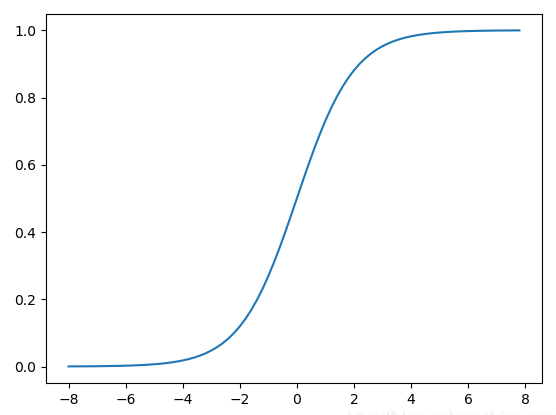
- Sigmoid函数(Logistic函数):
公式: σ ( x ) = 1 1 + e − x \text{公式:} σ(x) = \frac{1}{1+e^{-x}} 公式:σ(x)=1+e−x1
作用:将输入函数映射到0-1之间,适合用于输出层的二分类问题。
Sigmoid函数的特性:
- Sigmoid函数的输出范围是0到1。由于输出值限定在0到1,因此它对每个神经元的输出进行了归一化。
- 用于将预测概率作为输出的模型。由于概率的取值范围是0到1,因此Sigmoid函数非常合适
梯度平滑,避免跳跃的输出值 - 函数是可微的。这意味着可以找到任意两个点的Sigmoid曲线的斜率
明确的预测,即非常接近1或0。
函数图:
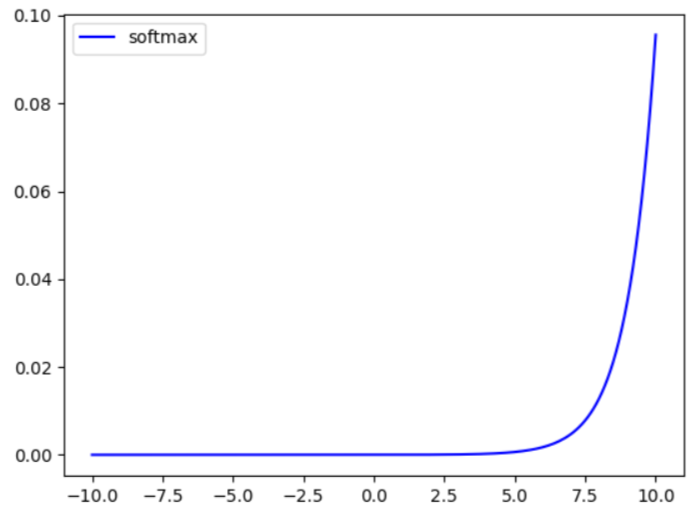
2. Softmax函数:
公式:
S
o
f
t
m
a
x
(
X
i
)
=
e
x
j
∑
j
−
1
N
e
x
j
\text{公式:}Softmax(X_i) = \frac{e^{x_j}}{\sum^N_{j-1}e^xj}
公式:Softmax(Xi)=∑j−1Nexjexj
作用:将向量映射为概率分布,常用于多分类问题的输出层。
函数图:
-
ReLU函数(修正线性单元)
公式: R e L U ( x ) = m a x ( 0 , x ) \text{公式:} ReLU(x) = max(0,x) 公式:ReLU(x)=max(0,x)
作用:提供了快速的收敛速度和稀疏激活性,解决了梯度消失的问题,适合用于隐藏层,但存在神经元死亡问题。。
函数图:
](https://img-blog.csdnimg.cn/direct/625b7579dc0d4af68fcdaf5677e0fd96.png)
-
Leaky ReLU函数:
公式: L e a k y R e L U ( x ) = { a x , i f x ≤ 0 x , i f x > 0 \text{公式:} Leaky\text{ }ReLU(x) = \{ ^{x,\text{ } if\text{ } x > 0}_{ax,\text{ } if\text{ } x ≤ 0} 公式:Leaky ReLU(x)={ax, if x≤0x, if x>0
作用:在负数部分引入小的斜率,解决了ReLU函数中神经元死亡的问题。
函数图: -
Tanh函数(双曲正切函数):
公式: t a n h ( x ) = e x − e − x e x + e − x \text{公式:} tanh(x) = \frac{e^x-e^{-x}}{e^x+e{-x}} 公式:tanh(x)=ex+e−xex−e−x
作用:将输入映射到-1到1之间,解决了Sigmoid函数梯度消失的问题,适合用于隐藏层。
公式: J α ( x ) = ∑ m = 0 ∞ ( − 1 ) m m ! Γ ( m + α + 1 ) ( x 2 ) 2 m + α \text{公式:} J_\alpha(x) = \sum_{m=0}^\infty \frac{(-1)^m}{m! \Gamma (m + \alpha + 1)} {\left({ \frac{x}{2} }\right)}^{2m + \alpha} 公式:Jα(x)=m=0∑∞m!Γ(m+α+1)(−1)m(2x)2m+α
深度学习的模型 就像 高中就函数的 系数一样,训练模型就是求系数的过程。

















 2073
2073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











