









Scrapy 是一套基于Twisted的异步处理框架,是纯Python实现的爬虫框架,只需要定制开发几个模块就可以轻松实现一个爬虫,用来抓取网页内容。
一 开发环境:
Ubuntu18.04 Scrapy1.5 Python3 Mongodb3.6 Pycharm
pip3 install scrapy
sudo apt-get install mongodb
二 Scrapy结构
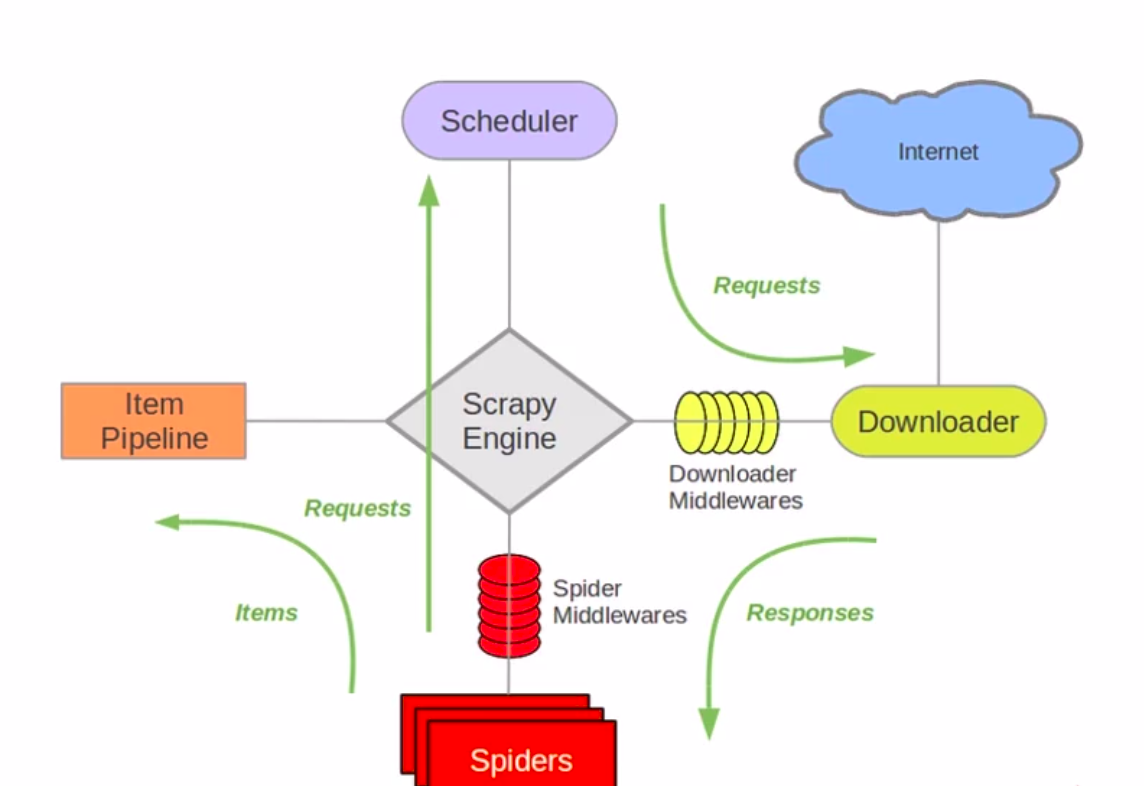
- Scrapy Engine:Scrapy引擎
- Schedule:一个队列。用来接收引擎发送的请求,将请求排队,并在引擎需要数据时向引擎发送数据。
- Downloader:下载器。负责下载引擎发送过来的Request请求,并将下载到的数据交还给引擎,并由引擎交给Spider进行解析。
- Spider:爬虫组件。用来分析和提取数据.
- Item Pipeline:管道组件。对数据进行后期处理及过滤。
- Downloader Middlewares:下载中间件。用来封装代理、http头。
- Spider Middlewares:Spider中间件。
三 Scrapy项目实例—抓取豆瓣网电影信息
1.新建项目
#新建项目
scrapy startproject douban
cd douban/spiders
#生成douban_spider.py文件 movie.douban.com是要爬取内容的域名
scrapy genspider douban_spider movie.douban.com
项目目录:
-douban
-spiders
-__init__.py
-douban_spider.py
-__init__.py
-items.py
-middlewares.py
-pipelines.py
-settings.py
-scrapy.cfg
- scrapy.cfg:项目配置文件。定义了项目设置文件路径、部署信息等内容。
- items.py:定义Item数据结构的文件。编写所有的Item数据定义。
- settings.py:项目设置文件。可以定义项目的全局设置,比如USER_AGENT等。
- douban_spider.py:爬虫文件。编写xpath和正则表达式的文件。
- pipelines.py:数据处理文件。对爬取到的数据进行处理保存等。
- middlewares.py:项目中间件文件。
2. 分析目标网站
1.确定要爬取的内容
- 电影名称
- 电影序号
- 电影介绍
- 电影星级
- 评价数
- 电影描述
2.编写items.py文件
在DoubanItem类中定义数据结构
# 序号
serial_number = scrapy.Field()
# 名称
movie_name = scrapy.Field()
# 介绍
introduce = scrapy.Field()
# 星级
star = scrapy.Field()
# 评论数
evaluate = scrapy.Field()
# 描述
describe = scrapy.Field()
3. 编写爬虫
1.编写douban_spider.py文件
import scrapy
from douban.items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
# 爬虫名字
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口url,扔进调度器
start_urls = ['https://movie.douban.com/top250']
# 对数据进行解析
def parse(self, response):
# 循环电影条目
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
for i_item in movie_list:
# item文件导入
douban_item = DoubanItem()
# 写详细的xpath,进行数据的解析
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']/div[@class='hd']/a/span[1]/text()").extract_first()
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
# 数据处理
for i_content in content:
content_s = "".join(i_content.split())
douban_item['introduce'] = content_s
print(douban_item)
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
# 需要将数据yield到pipelines里去
yield douban_item
# 解析下一页规则,取后页的xpath
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
2.运行爬虫文件
① 在终端进入爬虫项目,执行命令:
scrapy crawl douban_spider
② 或者在项目文件夹下新建main.py文件,用pycharm运行
from scrapy import cmdline
cmdline.execute('scrapy crawl douban_spider'.split())
4. 数据存储
1.保存为json或csv文件:
在终端进入项目文件,执行命令:
scrapy crawl douban_spider -o douban.json
scrapy crawl douban_spider -o douban.csv
2.保存到mongodb数据库中:
① 在settings.py中定义变量:
mongo_host = '127.0.0.1'
mongo_port = 27017
mongo_db_name = 'douban'
mongo_db_collection = 'douban_movie'
**注意:一定要在settings.py中打开ITEM_PIPELINES**
# -*- coding: utf-8 -*-
import pymongo
from douban.settings import mongo_host,mongo_port,mongo_db_name,mongo_db_collection
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class DoubanPipeline(object):
def __init__(self):
host = mongo_host
port = mongo_port
dbname = mongo_db_name
sheetname = mongo_db_collection
client = pymongo.MongoClient(host=host,port=port)
mydb = client[dbname]
self.post = mydb[sheetname]
def process_item(self, item, spider):
data = dict(item)
self.post.insert(data)
return item
3.在mongodb中查看:
终端输入mongo进入数据库
show databases;
use douban;
show collections;
db.douban_movie.find().pretty();
可能遇到的问题
1. 运行爬虫文件时 No module named ‘_sqlite3’
sudo apt-get install sqlite*
2. Crawled(403)<GET https://movie.douban.com/top250>
在settings.py中修改USER_AGENT
打开目标网页,打开请求页面(Chrome F12),在‘top250’请求中找到USER_AGENT,复制添加到settings.py文件中。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









