







灵感艺术家项目,旨在通过AIGC绘图能力,联合商家打造低门槛+高趣味性的宣传海报设计大赛,本文分享我们的方案和优化方向。建议对AIGC感兴趣的工程、算法方向的同学阅读。

项目背景
灵感艺术家项目,旨在通过AIGC绘图能力,联合商家打造低门槛+高趣味性的宣传海报设计大赛,为新品进行宣传和造势。同时也是为了给消费者提供参与新品宣发的通道。

目标拆解
GPT部分采用通义千问大语言模型,详见其技术文档。本文重点介绍海报风格的图像生成部分,分为商品海报、皮克斯,二次元,写实四种风格:




皮克斯、二次元、写实三个风格,实现思路比较清晰,属于标准的文生图,基于MJ、SD都可以实现。分析MJ和SD的优缺点的文章有很多,不做赘述,我们最终选择SD作为文生图的算法方案,核心在于SD开源,可塑性强。基于diffusers,我们重写了一套SD实现,支持VAE、ControlNet、Lora、Embedings等功能,根据业务特点,定制了warmup、auto_predict等能力。比较轻松的解决了这三个风格的生成问题。
算法的难点在于商品海报的风格生成,品牌方要求商品高度还原,并且生成的海报,像素清晰、细节丰富、具备高级感。要求是丰满的,而现实是骨感的。商品细节复杂,特别是带有文字时,很难生成。并且绘图灵感由用户文字随机输入,出图效果几乎是不可控的。为此,我们进行了大量调研,并做了一些优化尝试。

方案调研
以香奈儿5号香水为例,初步尝试了4套方案。
▐ 方案一 SD + Outpainting
简述:固定商品位置,重绘商品之外的区域。
优点:不会影响香水的外观。
缺点:图片中人物、背景与香水的位置关系很难控制,有比较明显的违和感。
▐ 方案二 SD Inpainting + Reference Only
简述:以商品图信息注入attention层中,来控制unet生成相似的图像。
优点:可以完全保留预生成的背景。
缺点:香水还原度低。

▐ 方案三 基于Reference的Diffusion算法
简述:基于一张参考商品图,生成较相似的商品
代表:PBE, IP Adapter, Anydoor…
优点:泛化性强,无需对每个商品单独训练
缺点:商品细节依旧不够还原copy&paste过于严重



▐ 方案四 SD + Lora/Dreambooth
简述:微调模型,注入商品外貌信息
优点:商品外貌还原度较高,且出图率较稳定
缺点:文字等细节还原度仍然不够高;且细节部分越小,其扭曲失真程度就越严重

方案四最接近想要的效果,但距离我们的要求,还有很大的差距。

优化方向
▐ 探索一 VAE增强
对LDM(SD的主要引用论文)模型的结构进行分析,初步怀疑细节还原不足的核心原因在于VAE从像素空间到隐空间相互转换过程中,丢失了细节信息。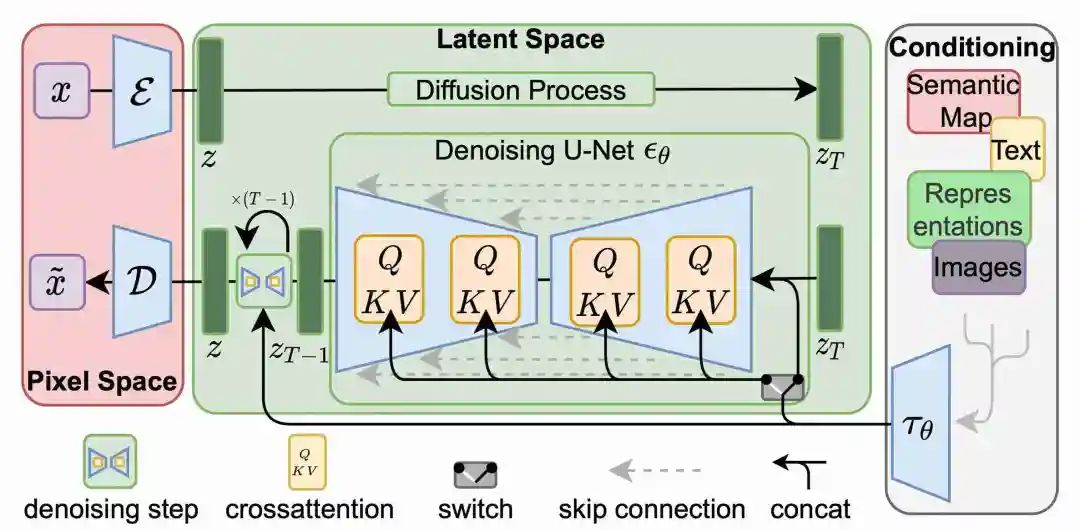
为了验证猜想,我们做了一个测试,对一张图片进行十次encoder和decoder操作,文字等图像细节已经开始模糊。我们想了一个方法,对VAE丢失的信息进行补偿,还原度有比较可观的增强。

但距离完美还原,依然还有差距。
▐ 探索二 图像超分
既然细节难以还原,那么把细节放大,是否还原度就可以提升?为了验证这个猜想,我们做了如下的实验。
在256 * 256分辨率下,文字几乎无法辨认。

在512 512分辨率下,相对256 256有明显改善,而且 2.X版本的还原度优于1.X版本。

升级到SDXL后,文字还原度进一步增强。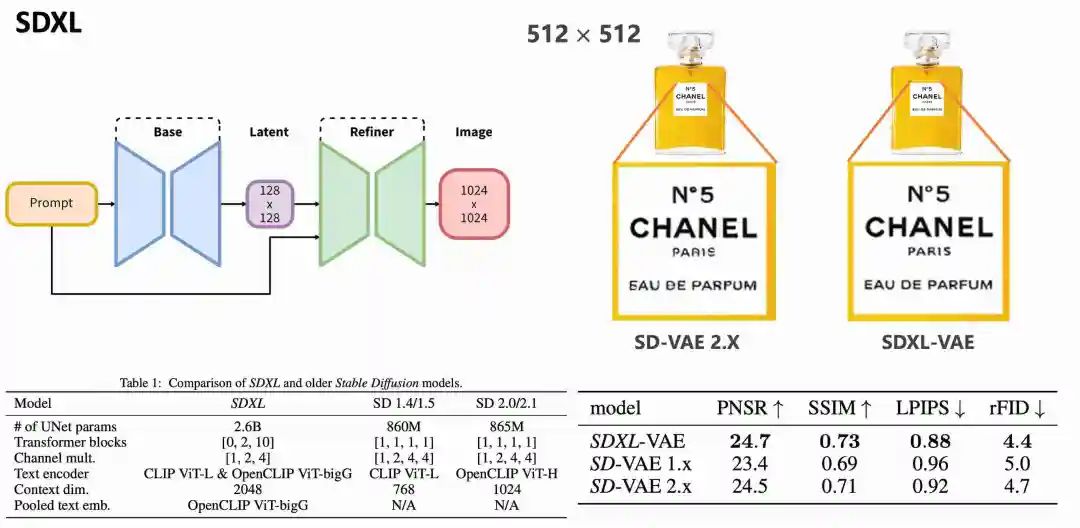
像素提升,还原度确实有提升。很自然的,我们想到可以在生成的图像上,对文字等细节部分进行超分,然后在refiner阶段,训练专属的 controlnet,进一步提升还原度。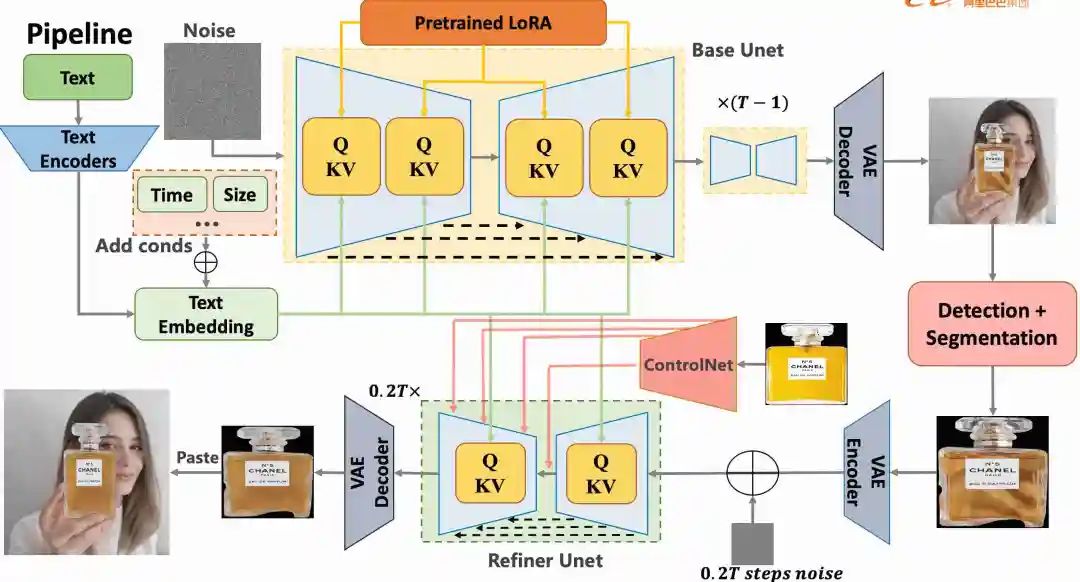
经过多次调整,细节还原度能达到90%以上。但距离完美还原,依然还有一点差距。
▐ 探索三 贴图
既然文字等细节非常难还原,那么是否可以直接把文字部分复制粘贴回去?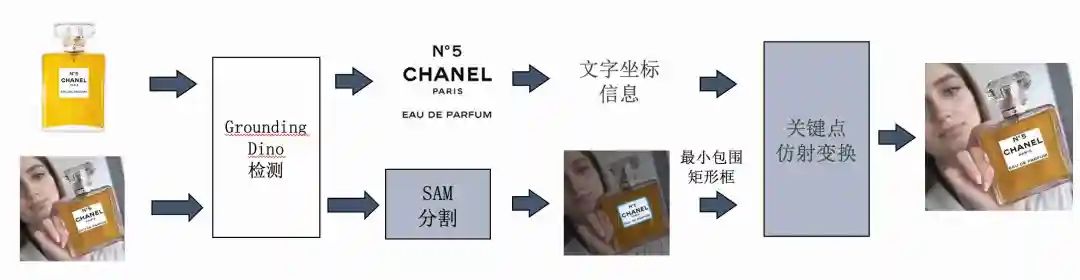
通过提取原始商品的文字区域,贴图到生成商品的对应区域,完美还原文字细节。

线上方案
经过上述几个方向的探索,初步解决了香水等商品的海报生成问题,但对复杂图文的商品依然很难还原,例如:

既要完美还原,又要增加泛化性,索性,全图贴回去【狗头】。方案如下:
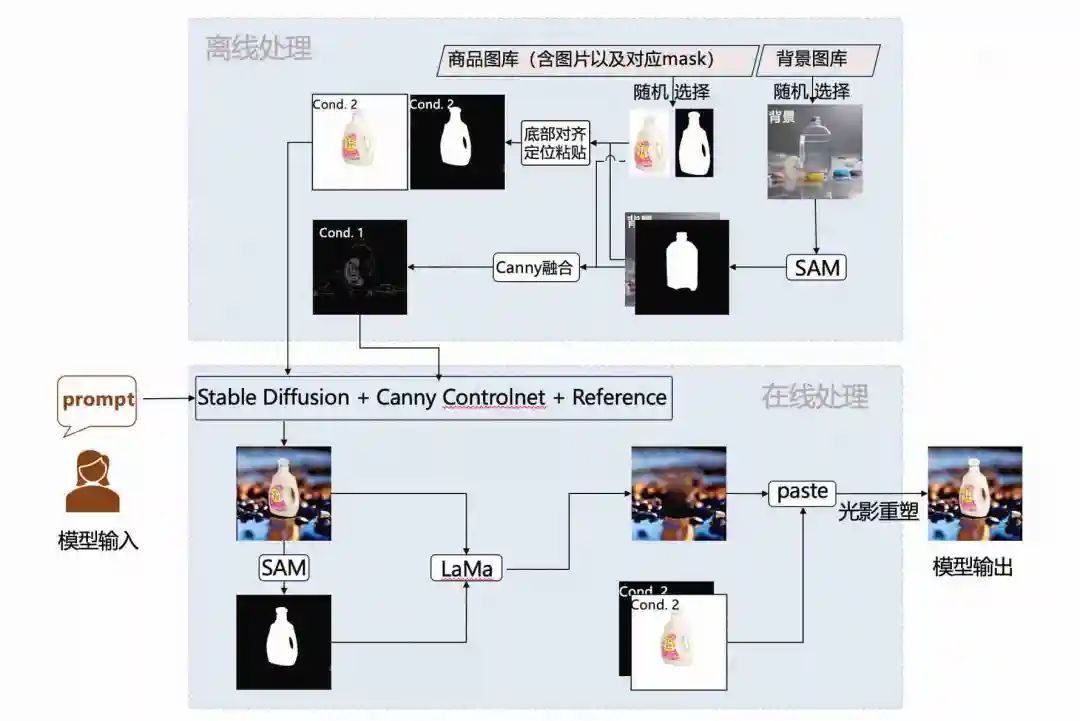
离线模块通过文生图产生一个背景图库。
离线模块预置多角度商品图,解决商品角度的多样性问题。
从背景图库中选择一张跟当前商品最相关的图作为引导图。解决商品和背景不协调的问题,提高出图率。
由商品图和背景图一起,生成线框图和商品白底图以及对应的mask。
通过Stable Diffusion+Canny Controlnet+Reference生成初步的商品海报。
使用SAM和LAMA抹除商品,防止后面贴图时,边缘出现对不齐的情况。
将抹去商品的图和步骤4中的商品白底图、对应的mask作为输入,合成新的图像。
提取步骤5中的生成商品的光影信息,投射到步骤7的商品上,生成最终的商品海报。
总结一下:
通过Copy&Paste的方式,保证无差别还原。
通过预置引导图解决了完全随机性,提高了出图率。
通过两步生成解决了倒影等问题。图像精美,具备高级感。
通过擦除重建以及图像融合技术,缓解了商品边缘的毛刺问题。
通过从生成图上提取光影,映射到贴图,解决了光影不和谐的问题。

测试效果


线上效果
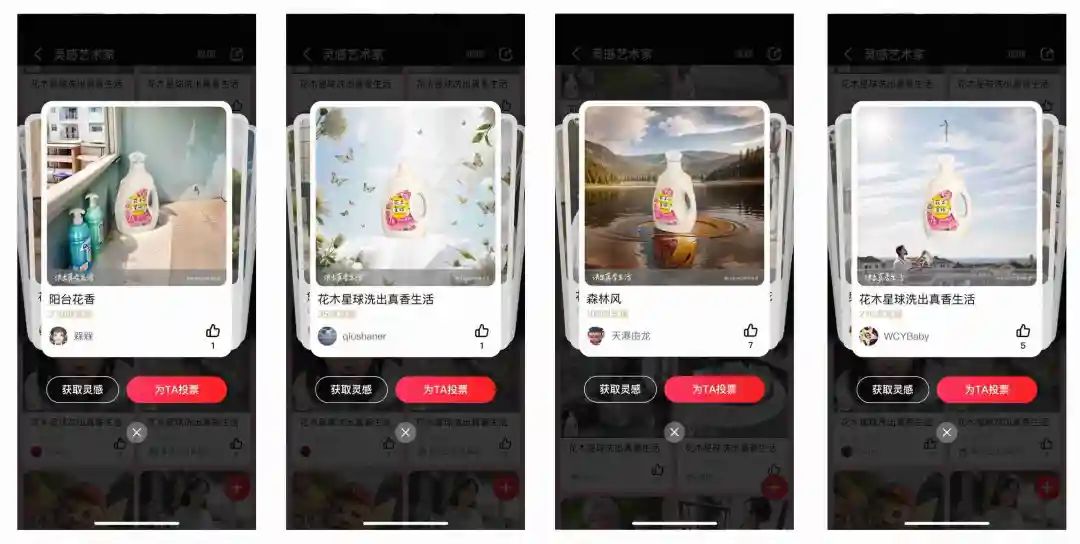
出图率95%以上,基本每张图都能看,大部分图能抗打。A10 GPU上,单卡出图速度3-5秒。

下一步探索方向
初步看,效果可以接受了,但依然还有一些可以提升的空间,比如:
如何进一步提升复杂海报的生成效果,增加遮挡关系?
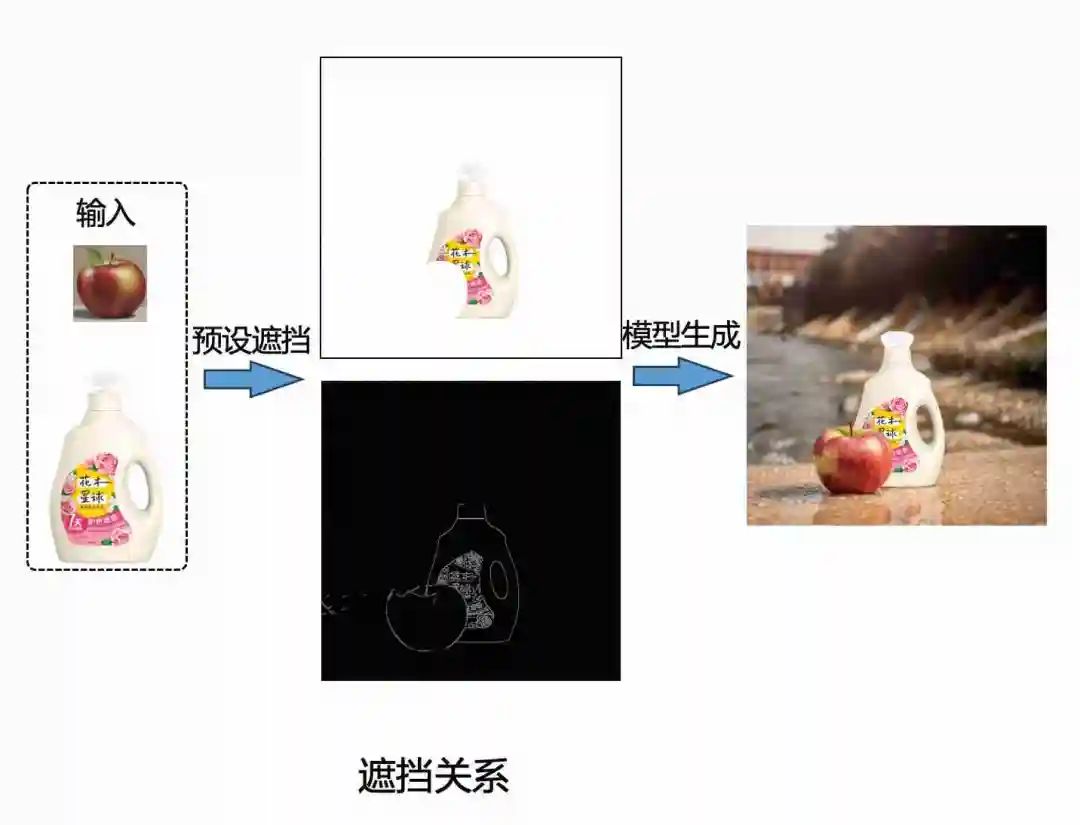
如何解决商品与背景的比例和谐,GLIGEN可能是答案?

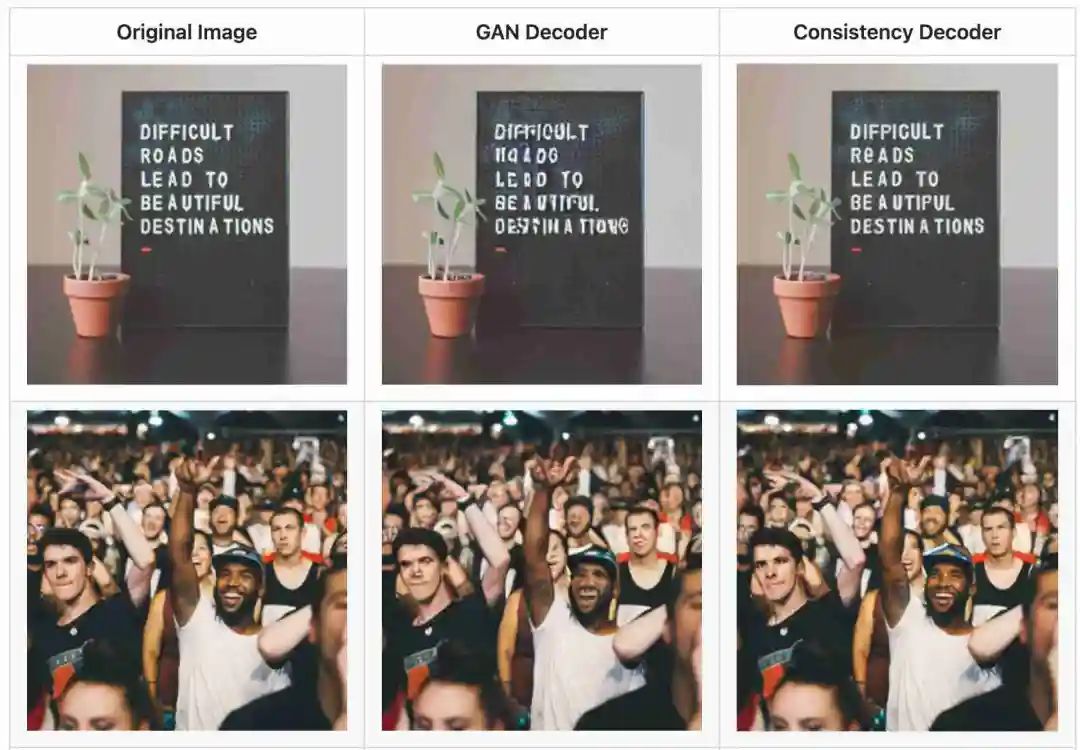
贴图总显得不那么算法,是否有机会继续提升VAE的能力,或者去掉VAE。Consistency Decoder可以试试?
最后,探索从未停止,AIGC永不眠。

引用
[1] IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
[2] Paint by Example: Exemplar-based Image Editing with Diffusion Models
[3] AnyDoor: Zero-shot Object-level Image Customization
[4] High-Resolution Image Synthesis with Latent Diffusion Models
[5] SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
[6] GLIGEN: Open-Set Grounded Text-to-Image Generation
[7] https://github.com/openai/consistencydecoder

团队介绍
我们是大淘宝FC技术智能策略团队,负责手机天猫搜索、推荐、拍立享等业务研发和技术平台建设,综合运用搜推算法、机器视觉、AIGC等前沿技术,致力于依靠技术的进步支持场景的提效和产品的创新,为用户带来更好的购物体验。
¤ 拓展阅读 ¤


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









