






最近在阅读【ICCV2021】Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification的源码,开一个坑,记录一下。
MultiHeadAtt
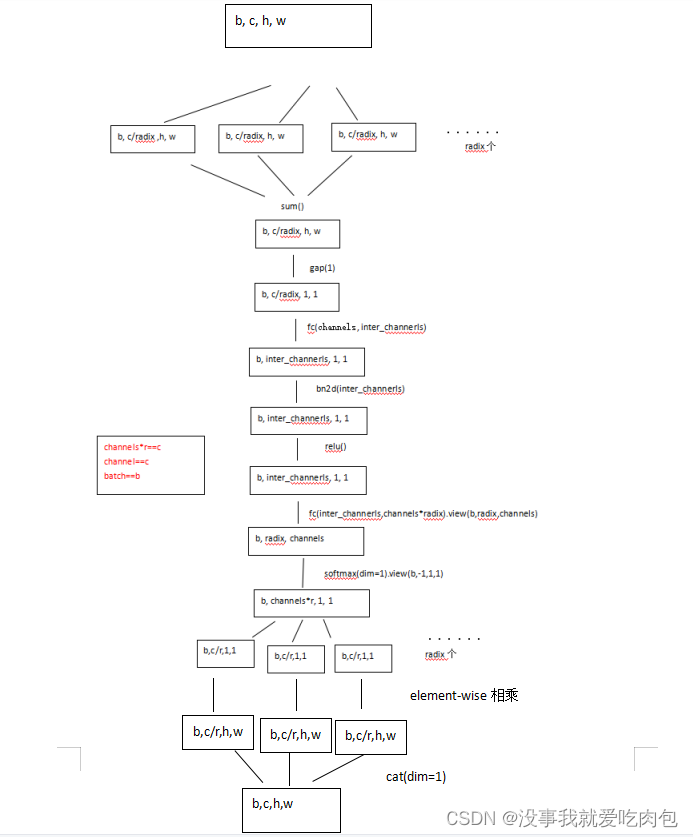
位于baseline.py,用于对输入特征图计算注意力并返回。这里的注意力采用的是类似ResNest中的Split-attention,还有一个是SENet,这里不讲了,只记录前者。
class MultiHeadAtt(nn.Module):
"""
Extend the channel attention into MultiHeadAtt.
It is modified from "Zhang H, Wu C, Zhang Z, et al. Resnest: Split-attention networks."
"""
def __init__(self, in_channels, channels,
radix=4, reduction_factor=4,
rectify=False, norm_layer=nn.BatchNorm2d):
super(MultiHeadAtt, self).__init__()
inter_channels = max(in_channels*radix//reduction_factor, 32)
self.radix = radix
self.channels = channels
self.relu = nn.ReLU(inplace=True)
self.fc1 = nn.Conv2d(channels, inter_channels, 1, groups=1)
self.bn1 = norm_layer(inter_channels)
self.fc2 = nn.Conv2d(inter_channels, channels*radix, 1, groups=1)
def forward(self, x):
batch, channel = x.shape[:2]
# 把channel拆分成radix份, 每份形状[b,channel//self.radix,h,w]
splited = torch.split(x, channel//self.radix, dim=1)
# radix个splited进行element-wise相加
gap = sum(splited)
# [b,channel//self.radix,1,1]
gap = F.adaptive_avg_pool2d(gap, 1)
gap = self.fc1(gap)
gap = self.bn1(gap)
gap = self.relu(gap)
# print(gap)
# [b,channels*radix,1,1].view() --> [b, radix, channels]
atten = self.fc2(gap).view((batch, self.radix, self.channels))
# print(atten.shape)
atten = F.softmax(atten, dim=1).view(batch, -1, 1, 1)
# print(atten.shape)
atten = torch.split(atten, channel//self.radix, dim=1)
# print(atten[0].shape)
out= torch.cat([att*split for (att, split) in zip(atten, splited)],1)
return out.contiguous()
对于输入x,给出其注意力图计算的图解如下:















 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









