






最近基于条件视频编码的工作告一段落,还是写一篇文章小小的总结一下。
Code
先简单介绍一下研究现状,条件视频编码框架是微软亚洲研究院提出的,第一次发表是在 NeurIPS 2021 上,后续也有一系列跟进的工作。先放论文和代码链接:
DCVC (NeurIPS 21):https://arxiv.org/abs/2109.15047
DCVC-TCM (TMM 23): https://arxiv.org/abs/2111.13850
DCVC-HEM (ACMMM 22): https://arxiv.org/abs/2207.05894
DCVC-DC (CVPR 23): https://arxiv.org/abs/2302.14402
推理的代码和预训练模型在 https://github.com/microsoft/DCVC/tree/main
作者未公开训练模型的代码,Github上也有许多讨论,有兴趣可以参考一下。若按最初的DCVC论文进行训练,训练过程还是比较复杂的,需要多阶段训练和多次修改损失函数。根据开源的模型我也在CompressAI上大概复现了一下,但是训练还是不稳定,有兴趣的朋友可以探究一下。
Paper
DCVC
关于一开始提出的条件编码框架,原作者也写了一篇公众号文章,是很好的学习材料。
https://mp.weixin.qq.com/s/YTCrWcad-MoeuvkDTgPUug
条件编码框架最大的创新点就是摒弃了传统的残差编码方式。传统的视频编码流程中对当前帧进行编码时,需要生成一张预测帧,然后将需要编码的当前帧和预测帧相减后得到残差,对残差进行编码。这是一种简单的方式,但是效果却不是最好的。简单的说就是编码当前帧的一个像素时,该像素其实不仅仅与预测帧中对应位置的像素有关,而是与已编码的所有像素和预测帧的所有像素都有关。解码的时候也是类似的情况。如果仅编码残差,其实并没有充分利用先前帧中的所有信息。
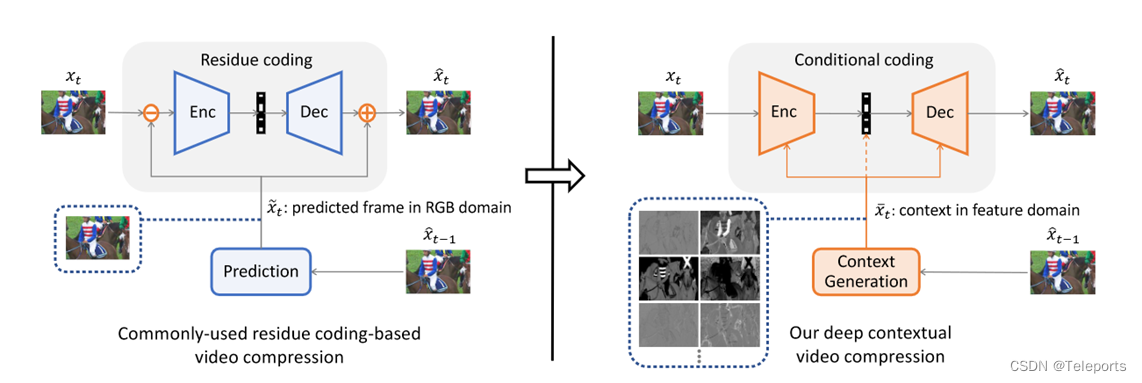
条件编码框架中的条件可以是任何有助于压缩当前帧的信息,预测帧当然可以用作条件,但肯定不是唯一可用的条件。
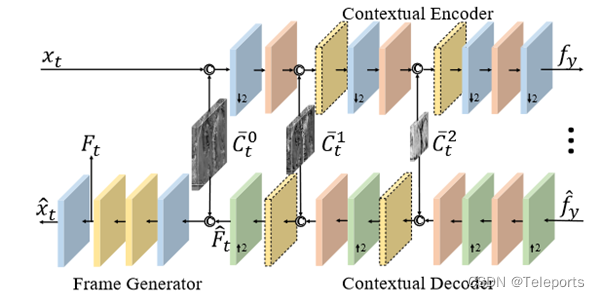
回到文中提出的压缩框架,可以看到在这里所用的条件的生成过程如下:从先前的重建帧中提取了特征,这里提取了64个通道的特征,然后在特征域下做Warping,这里的光流估计网络用的也是被广泛应用在其它基于深度学习的视频压缩工作中的SpyNet。Warping结束后再经过一个Refinement网络,最后生成的上下文信息被用作条件,帮助编解码器和熵模型完成对当前帧编解码过程。
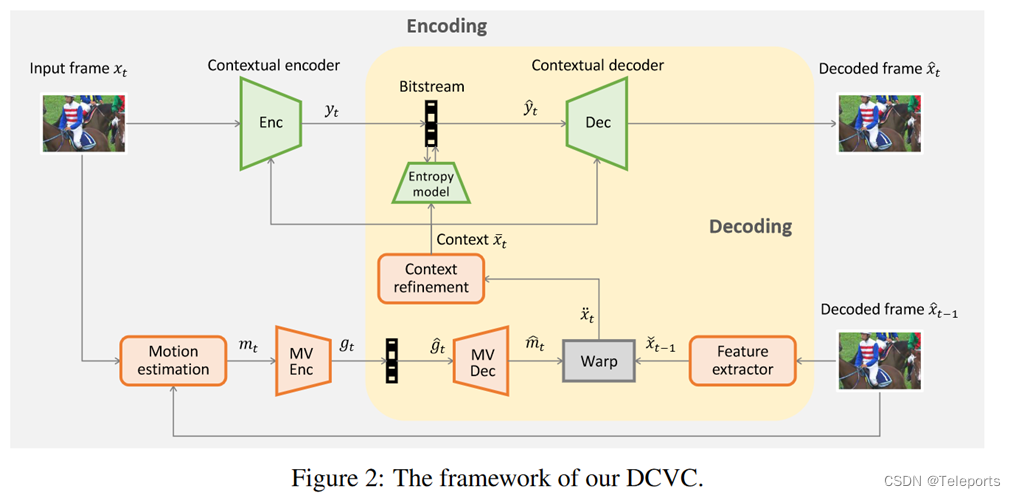
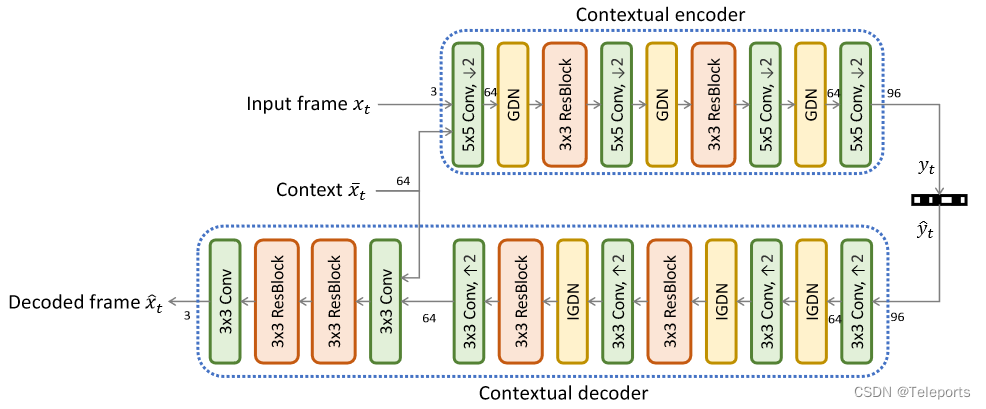
具体的编解码器结构论文中也给出了,在编码的时候,把当前帧和上下文Concat一下再送入编码器,而解码的时候则是将上下文在解码器靠后的位置Concat进去。
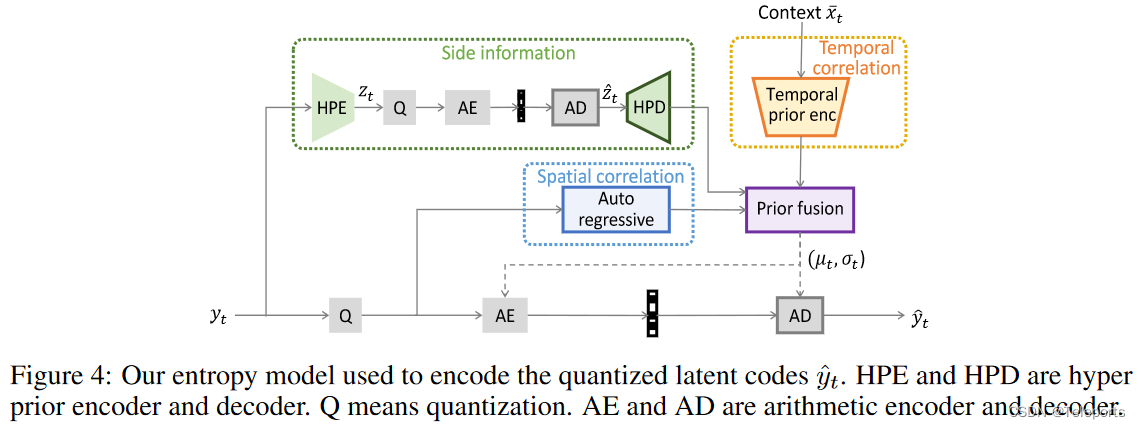
熵模型方面,除了常见的Hyper prior做side imformation,还把上下文引进来帮助估计分布。此外还用了Auto regressive,实际测试了一下这个会把训练和编解码速度都拖慢很多。
DCVC-TEM
TEM是Temporal context mining,前面提到DCVC从先前的重建帧中提取特征。这可能带来的一个问题是,重建帧只有三个通道,不足以容纳丰富的运动和纹理信息。那就不再直接从重建帧中直接提取上下文,而是从特征中提取时间上下文,Buffer中也直接存64个通道的特征。Decoder输出也不再直接输出重建帧,而是输出特征,再由一个网络根据输出的特征和时间上下文信息生成重建帧。
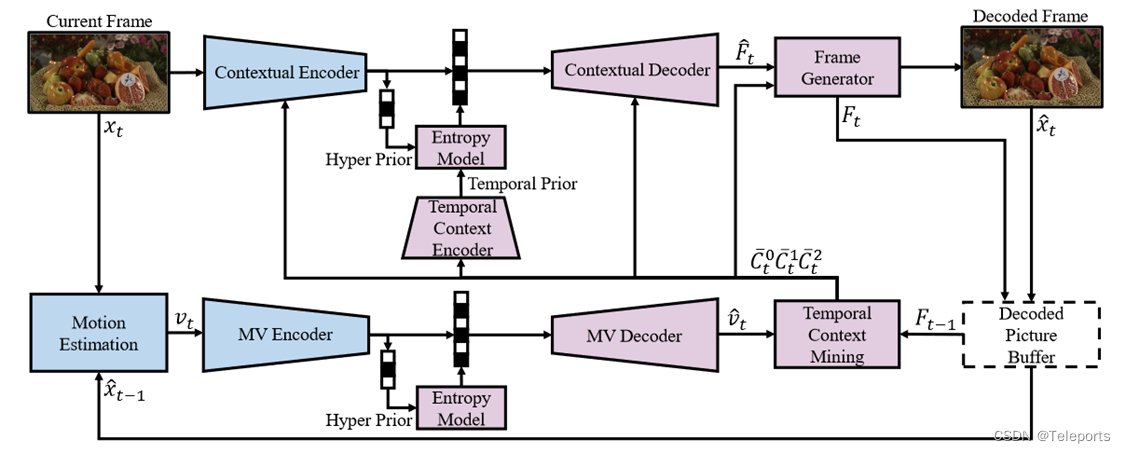
提取的上下文方面,也引入了3个尺度的,分别加到编解码器浅层到深层的不同位置。
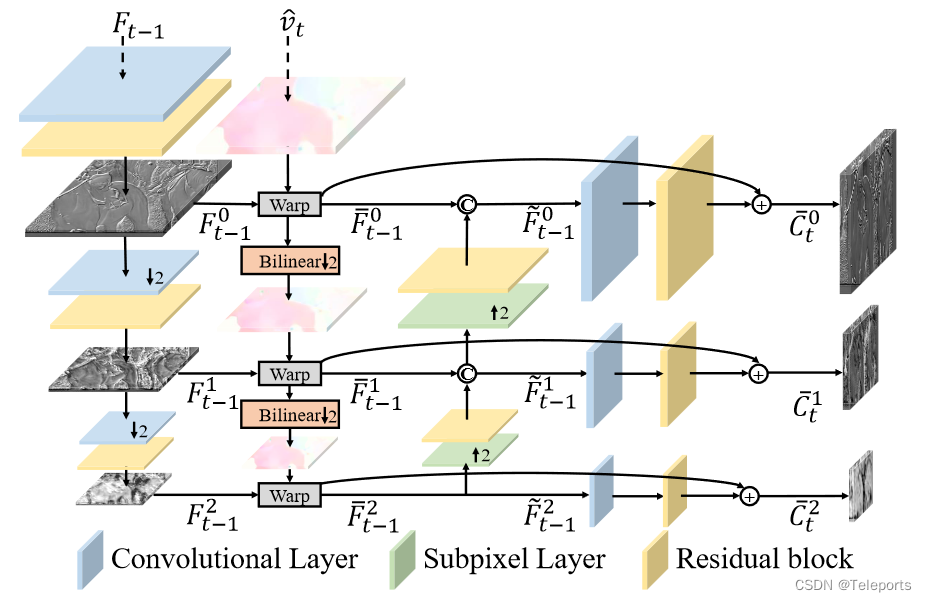
从主观上看,尺度较大的上下文保留了更多的纹理和细节,尺度较小的则有更多运动信息。

DCVC-HEM
HEM是Hybrid Spatial-Temporal Entropy Model,在TEM的基础上对熵模型进行了改进
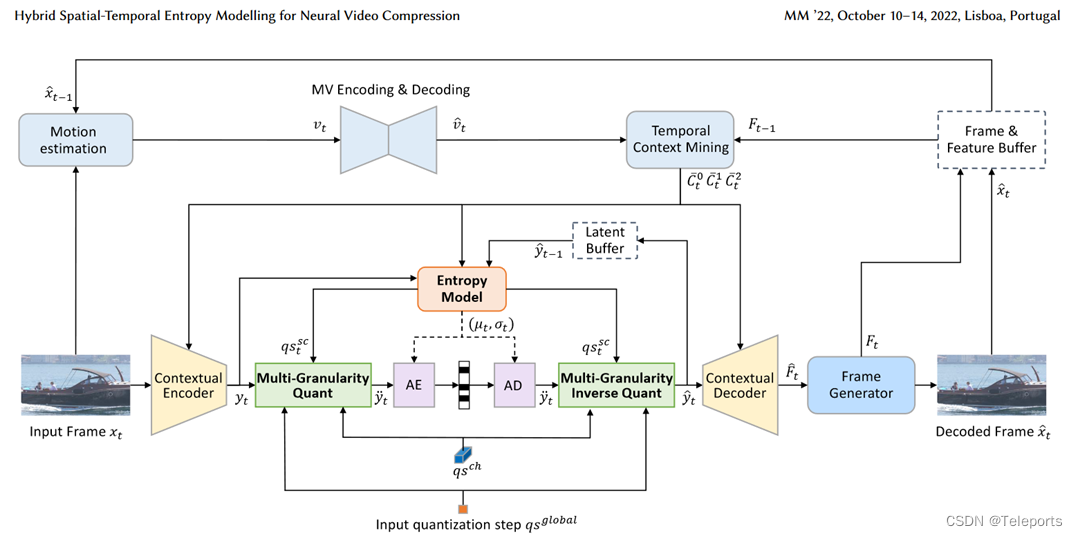 一个很大的创新是这里的量化步骤中,量化步长是在三个粒度上确定的,QS = global QS(用户针对目标码率设定) * channel-wise QS(不同的通道包含不同重要性的信息)* spatial-channel-wise QS(不同空间位置具有不同的特征)。这样只需要训练一个模型,根据所需码率调整这些步长即可,不再需要像之前的工作一样针对不同的码率训练不同的模型。
一个很大的创新是这里的量化步骤中,量化步长是在三个粒度上确定的,QS = global QS(用户针对目标码率设定) * channel-wise QS(不同的通道包含不同重要性的信息)* spatial-channel-wise QS(不同空间位置具有不同的特征)。这样只需要训练一个模型,根据所需码率调整这些步长即可,不再需要像之前的工作一样针对不同的码率训练不同的模型。
DCVC-DC
最新的工作,还没细看,简单贴一下结果图。
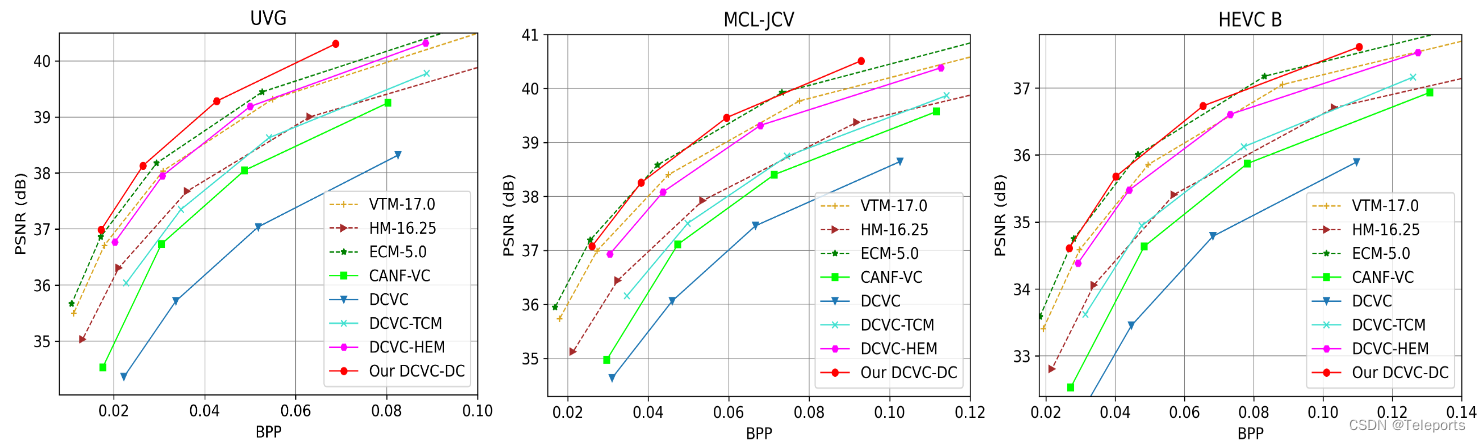 可见历经三次进化,DCVC的结果已经可以和几个参考软件相比拟,还是很有潜力的。
可见历经三次进化,DCVC的结果已经可以和几个参考软件相比拟,还是很有潜力的。
结语
DCVC的框架大体还是从传统视频编解码的框架改进来的,以深度学习的能力,在相似的框架下超越手工设计的算法其实并不是没有可能,最新的工作也展现了这样的潜力。
如果将来还有时间,再细化一下本文的相关细节。















 4044
4044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









