






在自回归架构中,模型针对输入内容逐个单词生成输出内容的文本。这个过程一般被称为解码。
解码策略
大语言模型的生成方式本质上是一个概率采样过程,需要合适的解码策略来生成合适的输出内容。
下图是一个直观的解码策略——贪心搜索。
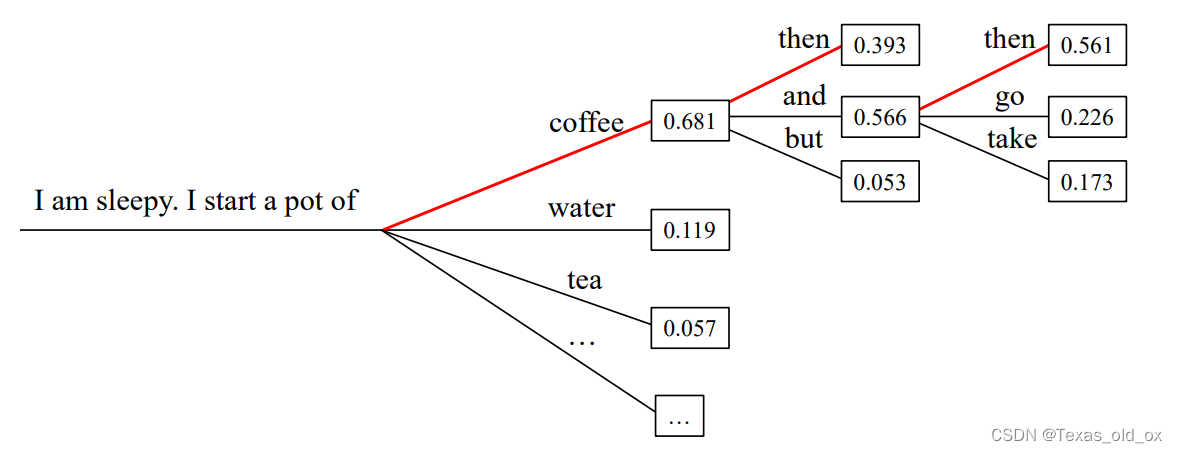
由于贪心搜索所采取的是确定性策略,对于不同的任务,该解码策略有一定差异。
还有另外的一种解码策略——概率采样

该图展示了下一个词元的概率分布,虽然单词“coffee”被选中的概率较高,但基于采样的策略同时也为选择其他单词(如“water”、“tea”等)留有一定的可能性,从而增加了生成文本的多样性和随机性。
贪心搜索的改进: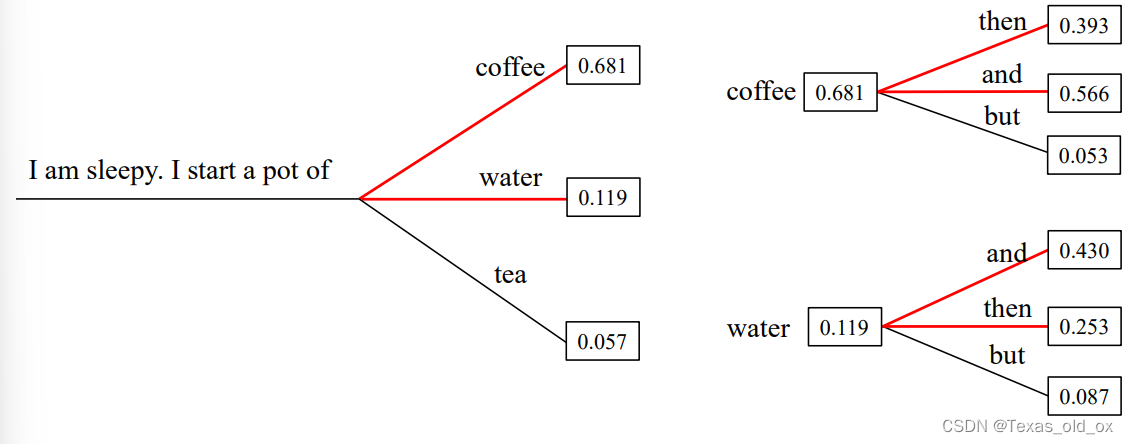
- 束搜索
寻找联合概率最高的句子。束通常被设置在3~6之间。
- 长度惩罚
如果没有长度惩罚,每生成一个单词,都会乘以一个小于1的概率,这就会导致容易产生短句,引入长度惩罚,会鼓励模型生成更长的句子。
- 重复惩罚
避免生成重复的连续n个词元。
随机采样的改进:
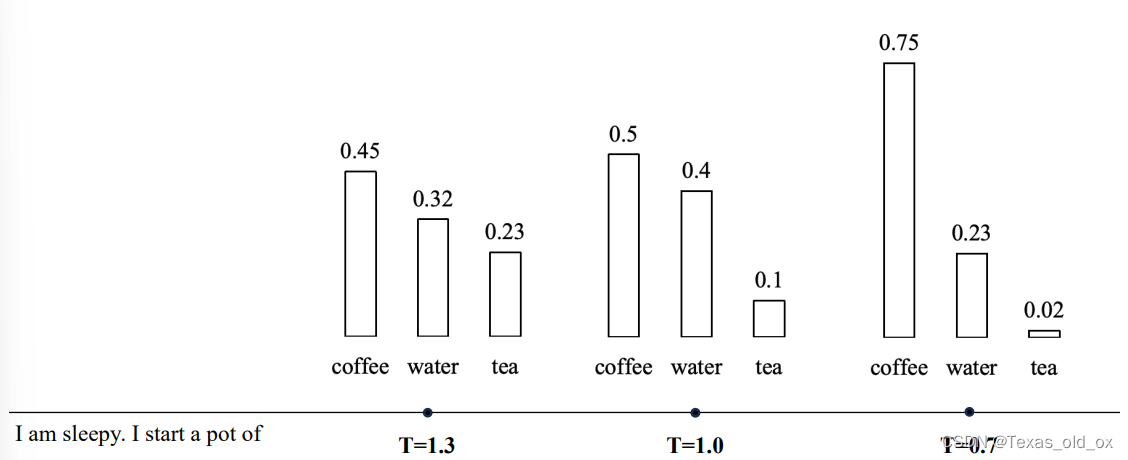
- 温度采样(温度系数 T(有时也标记为 τ 或 α)是一个引入到Softmax函数中的超参数,用来调整输出概率分布的“锐利”程度或“平滑”程度。)
降低温度系数 𝑡 会使得概率分布更加集中,从而增加了高概率词元的采样可能性,同时降低了低概率词元的采样可能。
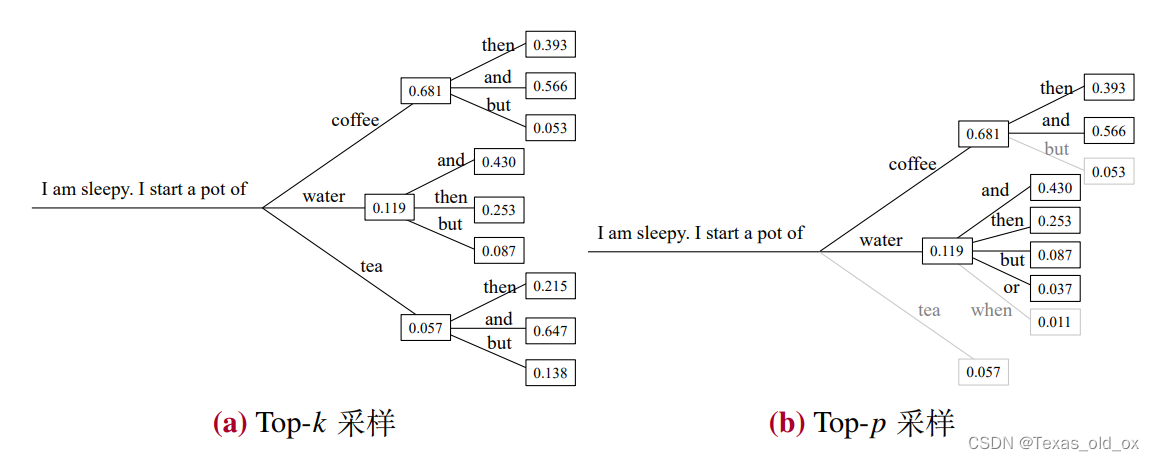
- Top-𝑘 采样
top-𝑘 采样策略是直接剔除概率较低的词元,限制模型从概率最高的前 𝑘 个词元中进行采样。
- Top-𝑝 采样
- 对比解码
由于大模型比小模型具有更强的生成能力,因而在预测下一个词元时,大语言模型相较于小模型更 倾向于为重要词元分配更高的概率。对比解码通过计算一个较大的语言模型和一个较小的语言模型之间的对数概率分布差值,然后基于归一化的差值分布采样下一个词元。
不同解码策略案例:


全量解码(黄色)阶段是受限于 GPU 浮点数计算能力的(即计算瓶颈)
全量解码阶段,对于输入序列,一次性地计算其状态并缓存键值矩阵
增量解码(蓝色)受限于 GPU 显存读写速度的(即显存瓶颈),这种问题通常被称为内存墙,解码阶段的低效问题主要出现在增量解码部分,这也是要着重优化的地方。
增量解码阶段,只计算上一步新生成词元的状态,并不断地以自回归方式生成新词元并对应更新键值缓存,直到生成结束。
针对内存墙的问题:
系统级优化方案:
- FlashAttention 通过矩阵分块和算子融合等方法,将中间结果一直保留在缓 存中,直到获得最终结果后再写回显存中,从而减少了显存读写量。
- PagedAttention 是针对键值缓存拼接和注意力计算的优化操作,能够有效降低这两个运算部分的访存量,从而提高计算效率。
- 批次管理优化旨在通过增加计算中的批次大小来提高计算强度。
解码策略优化:
推测解码(Speculative Decoding)
作者举的例子:
假设输入为“我与父亲不相见已二年余了,我最不能”,大模型的输出为“忘记的是他的背影”,总共要生成 8 个单词(为了讲解方便以单词为基础单位),需要 8 次 迭代的生成过程。如果使用推测解码,第一步先使用小模型生成 3 个单词,假设结果为“忘记他”,然后使用大模型进行验证,由于前两个词正确第三个词错误, 则同时将其修正为“忘记的”;第二步,再使用小模型生成 3 个单词,假设结果为 “日子是”,大模型验证第一个词便发现错误,同时将其修正为“他”;第三步,小模型生成“的背影”,大模型验证均正确,生成结束。回顾上述生成过程,小模型 共计生成了 9 次,大模型验证了 3 次(验证同时可以修正错误),相较于大模型的 8 次生成过程可以有一定的效率提升。
非自回归解码(Non-autoregressive Decoding)
尽管这些非(半)自回归策略在效 率上有所提升,但仍然不能达到自回归解码的效果。因此其很少单独使用,通常 可以用于推测解码中的候选片段生成,进而加速大模型的解码流程。
早退机制(Early Exiting)
早期一种常见的早退判断方法是对于 Transformer 每一层的输出都使用预测头得到在词表上的概率分布,然后计算该分布的熵。如果熵值小于预定义的阈值(即某一个词的概率显著较高),则可以判断为早退,不进行后续层的计算。
混合深度方法对于每一层的输入通过路由网络计算得分,如果该得分高于预先设定的阈值则进行该层的后续计算,否则直接跳过该层的计算。与传统早退机制直接跳过后续所有层计算相比,混合深度方法有选择性的跳过了部分层,因此可以更好地利用模型中不同层的特性。
级联解码(Cascade Inference)
与推测解码有类似的想法,级联解码考虑到不同请求的难易度不同,分别使用不同规模的模型来处理请求,从而实现最小化解码时间的效果。
低资源部署策略
模型量化,减少大模型的显存占用。
在神经网络压缩中,量化通常是指从浮点数到整数的映射过程。
针对神经网络模型,通常有两种类型的数据需要进行量化,分别为权重量化(也称为模型参数量化)和激活(值)量化,它们都以浮点数形式进行表示与存储。以下是实现量化和反量化的简单示例。
import torch
import numpy as np
def quantize_func(x, scales, zero_point, n_bits=8):
x_q = (x.div(scales) + zero_point).round()
x_q_clipped = torch.clamp(x_q, min=alpha_q, max=beta_q)
return x_q_clipped
def dequantize_func(x_q, scales, zero_point):
x_q = x_q.to(torch.int32)
x = scales * (x_q - zero_point)
x = x.to(torch.float32)
return x
if __name__ == "__main__":
# 输入配置
random_seed = 0
np.random.seed(random_seed)
m = 2
p = 3
alpha = -100.0 # 输入最小值为-100
beta = 80.0 # 输入的最大值为 80
X = np.random.uniform(low=alpha, high=beta,
size=(m, p)).astype(np.float32)
float_x = torch.from_numpy(X)
# 量化参数配置
num_bits = 8
alpha_q = -2**(num_bits - 1)
beta_q = 2**(num_bits - 1) - 1
# 计算 scales 和 zero_point
S = (beta - alpha) / (beta_q - alpha_q)
Z = int((beta * alpha_q - alpha * beta_q) / (beta - alpha))
# 量化过程
x_q_clip = quantize_func(float_x, S, Z)
print(f" 输入:\n{float_x}\n")
# tensor([[ -1.2136, 28.7341, 8.4974],
# [ -1.9210, -23.7421, 16.2609]])
print(f"{num_bits}比特量化后:\n{x_q_clip}")
# tensor([[ 11., 54., 25.],
# [ 10., -21., 36.]])
x_re = dequantize_func(x_q_clip,S,Z)
print(f" 反量化后:\n{x_re}")
# tensor([[ -1.4118, 28.9412, 8.4706],
# [ -2.1176, -24.0000, 16.2353]])大模型量化可以分为两大类:
量化感知训练
训练后量化
量化感知训练方法需要更新权重进而完成模型量化,而训练后量化方法则无需更新模型权重。
现有研究结论汇总:
- INT8 权重量化通常对于大语言模型性能的影响较小,更低精度权重量化的效果取决于具体的量化方法。
- 低比特权重量化对于大语言模型的影响通常较小。因此,在实际使用中,在相同显存开销的情况下,建议优先使用参数规模较大的语言模型,而不是表示精度较高的语言模型。
- 对于语言模型来说,激活值相对于模型权重更难量化
- 轻量化微调方法可以用于补偿量化大语言模型的性能损失(回顾 LoRA 方法,其核心是维护两部分参数,包括不微调的模型权重与微调的适配器参数。基于LoRA 的性能补偿方法的基本想法是,针对模型权重进行低比特量化,而对于适配器参数则使用 16 比特浮点数表示并使用LoRA 算法进行微调,在推理时,量化部分的模型权重会先反量化为 16 比特浮点数,再与适配器权重相加进行融合使用。)
除了模型量化外,其他模型压缩方法:
- 模型蒸馏
模型蒸馏(Model Distillation)的目标是将复杂模型(称为教师模型)包含的知识迁移到简单模型(称为学生模型)中,从而实现复杂模型的压缩。
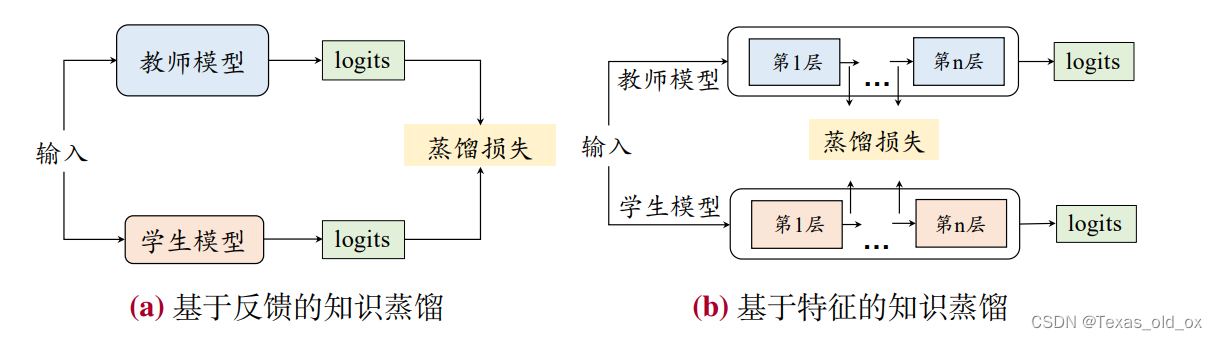
(a):让学生 模型输出的 logits 去近似教师模型输出的 logits,进而通过这种方式让学生模型学 习到教师模型的特有知识。
(b):关注于教师模型的中间层输出的激活值,并使用这些激活值作为监督信息训练学生模型。以教师模型的中间层特征与学生模型的中间层特征的相似度作为训练指标。
- 模型剪枝
模型剪枝(Model Pruning)的目标是,在尽可能不损失模型性能的情况下,努力消减模型的参数数量,最终有效降低模型的显存需求以及算力开销。
模型剪枝分为结构化剪枝(去除模型的某些部分)和非结构化剪枝(保持模型不变,使用掩码矩阵来剪枝模型参数矩阵)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









