






写在前面:本笔记会省略很多内容,非常不建议初学的小白看,仅仅作为复习第二遍或者第三遍使用。
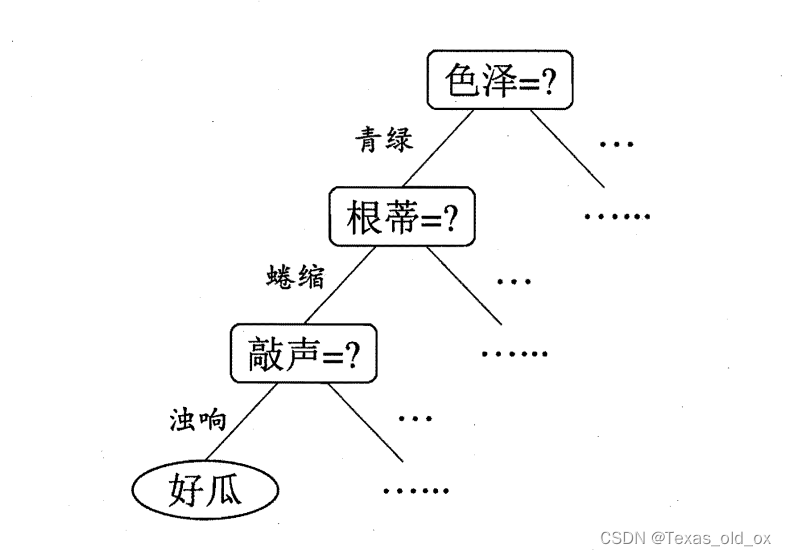
决策树是基于树结构来进行决策的,这恰是人类在面临决策问题时一种很自然的处理机制。上图可以体现一种决策过程。
决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树,其基本流程遵循简单且直观的"分而治之" (divide-and-conquer) 策略。

对于上述决策树算法,最为重要的是选择最优划分属性,这就需要引出一个概念——信息增益。
在构建决策树的过程中,我们需要选择哪些特征来分裂节点,以形成树的分支。信息增益就是用来评估特征分裂效果的一种重要指标。一般而言,信息增益越大,则意味着使用该属性来进行划分所获得的"纯度提升"越大。在决策树中,我们希望每个分支下的数据尽可能属于同一类别,这样就可以简化分类过程。信息增益越高,意味着使用该特征进行分裂后,子节点的数据纯度提高得越多,分类也就越清晰。
具体来说,信息增益是基于信息论中的熵概念。熵是一个度量不确定性或混乱程度的指标。在决策树中,数据集的熵反映了类别标签的混合程度。如果数据集中样本的类别标签非常均匀,那么熵就较高;反之,如果数据集中大多数样本属于同一类别,熵就较低。
大家如果对高中化学还有印象的话,应该会想到化学反应方程式左右的熵增熵减,这里的熵大概就是这么个东西。
一个著名的算法——ID3决策树学习算法,就是用的信息增益来划分属性。
当我们使用一个特征来分裂数据集时,我们会计算分裂前后的熵变化,即信息增益。信息增益的计算公式如下:
![]()
其中:
- Entropy(D) 是分裂前数据集 D 的熵;
- Entropy(Dv) 是分裂后属于特征 A 的值 v 的子集 Dv 的熵;
- ∣D∣ 和 ∣Dv∣ 分别是数据集 D 和子集 Dv 的样本数量。
实际上,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,著名的 C4.5 决策树算法不直接使 用信息增益,而是使用"增益率" (gain ratio) 来选择最优划分属性。需注意的是,增益率准则对可取值数目较少的属性有所偏好,因此 C4.5 算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
CART决策树使用“基尼指数”来选择划分属性,直观来说,Gini(D) 反映了从数据集中随机抽取两个样本,其类别标记不一致的概率.因此,Gini(D) 越小,则数据集的纯度越高。CART决策树生成的是二叉树,即每个非叶节点都有两个分支,分别代表特征取值的两种情况。
于是,我们在候选属性集合中,选择那个使得划分后基尼指数最小的属性作为最优划分属性。
在决策树中,应对过拟合的方式主要是“剪枝”,基本策略分为预剪枝和后剪枝。
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。
后剪枝则是先从训练集生成一棵完整的决策树, 然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
那么问题来了,如何判断决策树泛化性能是否提升呢?
在使用数据集的时候划分为训练集和验证集,计算剪枝前和剪枝后验证集的精度,如果会带来上升,那就剪,不上升那就不剪。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 加载数据
data = load_iris()
X = data.data
y = data.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建CART分类器实例,使用预剪枝
pre_clf = DecisionTreeClassifier(criterion='gini', max_depth=3, min_samples_split=20, random_state=42)
pre_clf.fit(X_train, y_train)
# 预测并评估预剪枝模型
y_pred_pre = pre_clf.predict(X_test)
accuracy_pre = accuracy_score(y_test, y_pred_pre)
print("Pre-pruned Accuracy:", accuracy_pre)
# 使用成本复杂性剪枝(后剪枝)
path = pre_clf.cost_complexity_pruning_path(X_train, y_train)
ccp_alphas, impurities = path.ccp_alphas, path.impurities
clfs = []
for ccp_alpha in ccp_alphas:
clf = DecisionTreeClassifier(random_state=42, ccp_alpha=ccp_alpha)
clf.fit(X_train, y_train)
clfs.append(clf)
print("Number of nodes in the last tree is: {} with ccp_alpha: {}".format(
clfs[-1].tree_.node_count, ccp_alphas[-1]))
# 深度搜索找到最优的 ccp_alpha 值
clfs = clfs[:-1]
ccp_alphas = ccp_alphas[:-1]
train_scores = [clf.score(X_train, y_train) for clf in clfs]
test_scores = [clf.score(X_test, y_test) for clf in clfs]
fig, ax = plt.subplots()
ax.set_xlabel("alpha")
ax.set_ylabel("accuracy")
ax.set_title("Accuracy vs alpha for training and testing sets")
ax.plot(ccp_alphas, train_scores, marker='o', label="train", drawstyle="steps-post")
ax.plot(ccp_alphas, test_scores, marker='o', label="test", drawstyle="steps-post")
ax.legend()
plt.show()
# 选择最优 ccp_alpha 并重新训练模型
optimal_ccp_alpha = ccp_alphas[np.argmax(test_scores)]
post_clf = DecisionTreeClassifier(random_state=42, ccp_alpha=optimal_ccp_alpha)
post_clf.fit(X_train, y_train)
# 预测并评估后剪枝模型
y_pred_post = post_clf.predict(X_test)
accuracy_post = accuracy_score(y_test, y_pred_post)
print("Post-pruned Accuracy:", accuracy_post)
# 可视化决策树
plt.figure(figsize=(20,10))
plot_tree(post_clf, filled=True, feature_names=data.feature_names, class_names=data.target_names)
plt.show()首先创建了一个预剪枝的决策树模型,并评估了它的准确性。然后,使用成本复杂性剪枝路径计算了一系列的ccp_alpha值,并对每一个值都训练了一个决策树模型,最后通过比较测试集上的准确率来确定最优的ccp_alpha值,进而得到最优的决策树模型。最后还可视化了这个最优决策树,以便于理解其结构。大家可以去尝试运行一下,加深记忆。
决策树如何处理连续属性?
- 选择具有最高信息增益(或根据使用的不纯度度量)的切分点,将数据集分为两个子集。
- 这个切分点将用于创建决策树中的一个分支节点,左边的分支代表低于切分点的值,右边的分支代表高于切分点的值
需注意的是,与离散属性不同,若当前结点划分属性为连续属性。该属性还可作为其后代结点的划分属性。例如在父结点上使用了 "密度<=0.381",不会禁止在子结点上使用"密度<=0.294"
如何处理缺失值呢?
在计算信息增益时,C4.5会考虑到属性中可能存在的缺失值。通常,信息增益是基于属性值划分数据集后,熵的变化量来计算的。但是,如果属性有缺失值,C4.5会采用一种加权方法来处理这些缺失值。
具体来说,对于一个具有缺失值的属性,C4.5算法会假设缺失值可以取该属性的所有可能值,并根据数据集中每种可能值的频率为这些假设值分配权重。然后,它会基于这些加权的假设值来计算信息增益。
在预测阶段,如果一个样本在某个属性上有缺失值,C4.5会通过加权所有可能的分支来处理这个问题。这里的过程类似于计算信息增益时的处理方式:
- 首先,根据训练数据中该属性每种值的频率,计算出每种可能值的概率权重。
- 然后,对于缺失值的样本,C4.5会按照每种可能值的权重,沿着决策树的相应分支进行预测。
- 最终的预测结果是所有可能分支预测结果的加权平均,权重即是对应的概率。
假设我们有一个决策树节点,正在考虑使用属性A进行分裂,但有些样本在属性A上的值是缺失的。如果属性A有三个可能的值:a1, a2, a3,且训练数据中这三个值的频率分别是20%,30%,50%,那么缺失值的样本将按照20%,30%,50%的权重分配到a1, a2, a3对应的子节点上。
在预测时,如果一个样本在属性A上缺失值,它将同样按照20%,30%,50%的权重分别沿a1, a2, a3的分支预测,最终的分类结果是这三种可能结果的加权平均。这种处理缺失值的方式充分利用了数据的统计信息,使得决策树即使在面对不完整数据时也能做出相对合理的预测。同时,它也避免了简单的删除或填充缺失值所带来的信息损失或偏差问题。
多变量决策树:
多变量决策树(MVDTs, Multi-Variable Decision Trees)是传统决策树的一个扩展,它允许在决策树的节点上使用多个特征的组合来做出决策,而不是像传统的决策树那样,每个节点仅基于单个特征进行分裂。
在传统的决策树中,每个内部节点通常对应一个单一的特征,该特征用于将数据集划分为两个或更多子集。然而,在某些情况下,单个特征可能不足以区分数据,或者数据的决策边界可能是多维的,这就促使了多变量决策树的发展。
- MVDTs可以使用线性组合的方式来组合多个特征,即在节点处使用一个线性方程来评估多个特征的加权和。
- 由于使用了多个特征的组合,MVDTs可以捕获更复杂的决策边界,这对于处理高维数据和非线性关系特别有用。
- 在某些场景下,MVDTs可能比单变量决策树提供更好的泛化能力和预测精度,尤其是在特征之间存在强相关性的情况下。















 901
901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









