






什么叫人类对齐?
在大语言模型的学习过程中,如何确保大语言模型的行为与人类价值观、人类真实意图和社会伦理相一致的研究问题,就叫人类对齐。
说起人类对齐,绕不开一项关键技术——基于人类反馈的强化学习(RLHF)
对齐标准?
三个具有代表性的对齐标准是:有用性、诚实性、无害性。
以上三个概念都比较宽泛,有许多研究都有针对性的提出了一些更细化的对齐标准。
RLHF算法系统
1.待对齐的模型
2.基于人类反馈数据学习的奖励模型
3.用于训练大语言模型的强化学习算法(PPO)
在InstructGPT中 RLHF的关键步骤:
正如图所示:
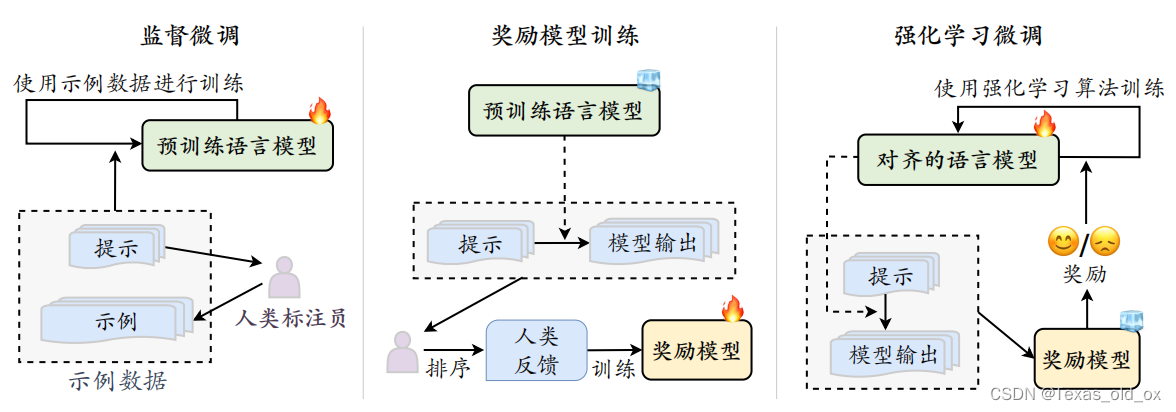
监督微调阶段:
为了让待对齐语言模型具有较好的指令遵循能力,通常需要收集高质量的指令数据进行监督微调。指令数据一般包括任务描述和示例输出。
奖励模型训练阶段:
首先使用语言模型针对任务指令生成一定数量的候选输出。随后,邀请标注员对于输出文本进行偏好标注。进一步,使用人工标注的偏好数据进行奖励模型的训练,使其能够建模人类偏好。
强化学习训练阶段:
待对齐语言模型担任策略实施者的角色(称为策略模型),它接收提示作为输入并返回输出文本,其动作空间是词汇表中的所有词元,状态指的是当前已生成的词元序列。奖励模型则根据当前语言模型的状态提供相应的奖励分数,用于指导策略模型的优化。为了避免当前训练轮次的语言模型明显偏离初始(强化学习训练之前)的语言模型,通常会在原始优化目标中加入一个惩罚项(如 KL散度)。
-
基于评分的人类反馈
-
基于排序的人类反馈
这是两种主要的方式。
奖励模型的训练:
为什么要训练奖励模型?
由于 RLHF 的训练过程中需要依赖大量的人类偏好数据进行学习,因此很难在训练过程中要求人类标注者实时提供偏好反馈。
怎么进行训练呢?训练这个的作用?
在训练开始前,需要预先构造一系列相关问题作为输入。人类标注者将针对这些问题标注出符合人类偏好的输出以及不符合人类偏好的输出。收集到这些人类偏好数据后,就可以用来训练奖励模型。经过充分训练的奖励模型能够有效地拟合人类偏好,并在后续的强化学习训练过程中替代人类提供反馈信号。
奖励模型的训练方法主要包括三种:
打分式:人类标注者需针对给定的输入问题,为相应的输出赋予反馈分数。
一般情况下,采用均方误差损失
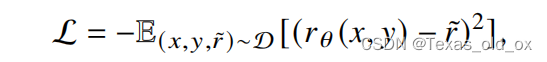
对比式:对比式训练方法一定程度上能够克服打分式训练方法的不足。针对一个问题输入,人类标注者仅需对两条相应输出进行排序,排序在前的输出被视为正例(更符合人类偏好),另一条输出则被视为负例。
一般用对比损失
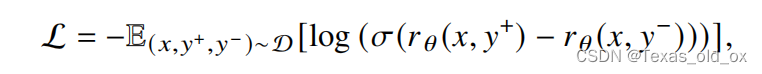
排序式:排序式训练方法可以被视为对比式训练方法的一种增强形式。对于一个给定的输入,人类标注者根据偏好对于多个模型生成的回复进行排序。通过标注的顺序,可以获得这些回复之间的相对优劣关系,即哪些回复更符合人类价值观。
和对比式采用的损失函数类似,可表示为如下形式:
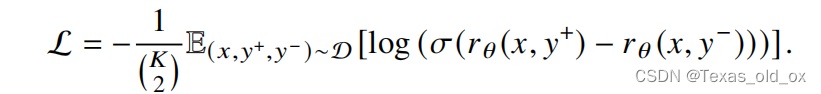
训练策略:为了进一步增强奖励模型对于人类偏好的拟合能力,可以通过修改训练过程的目标函数、选取合适的基座模型和设置合理的奖励计算形式等方式来优化奖励模型的训练过程。
-
目标函数优化
在训练大规模奖励模型时,有时会遇到过拟合问题。为了解决这一问题,可以将最佳的模型输出所对应的语言模型损失作为正则项。
例子:可以在对比式方法的损失函数的基础上添加模仿学习(Imitation Learning)的损失函数,即奖励模型在学习最大化正负例分数差距的同时也学习基于输入生成正例。
-
基座模型选取
使用更大的奖励模型(例如与原始模型尺寸相等或更大的模型)通常能够更好地判断模型输出质量,提供更准确的反馈信号。
-
奖励计算形式
由于对齐存在多个标准(例如有用性和诚实性),单一奖励模型很难满足所有对齐标准。因此,可以针对不同对齐标准训练多个特定的奖励模型,然后使用特定的组合策略(例如取平均值或加权平均)计算基于这些奖励模型的最终奖励。
以下是一个采用对比式训练方式的代码示例(源代码来自于 THE CHINESE BOOKFOR LARGE LANGUAGE MODELS Page174&Page175):
1 import torch
2 import torch.nn as nn
3 import torch.nn.functional as F
4
5 from transformers import LlamaForCausalLM,
6
7 class LlamaRewardModel(LlamaForCausalLM):
8 def __init__(self, config):
9 super().__init__(config)
10
11 # 初始化线性变换层,将隐状态映射为标量,用于输出最终奖励
12 self.reward_head = nn.Linear(config.hidden_size, 1, bias=False)
13
14 def _forward_rmloss(self, input_ids, attention_mask, **kargs):
15 # input_ids:输入词元的标号序列。
16 # attention_mask:与输入相对应的注意力掩码
17
18 # 将输入词元通过大语言模型进行编码,转化为隐状态
19 output = self.model.forward(
20 input_ids=input_ids,
21 attention_mask=attention_mask,
22 return_dict=True,
23 use_cache=False
24 )
25 # 使用线性变换层,将隐状态映射为标量
26 logits = self.reward_head(output.last_hidden_state).squeeze(-1)
27 return logits
28
29 def _forward_lmloss(self, prompt_ids, lm_attn_mask, response_ids):
30 # prompt_ids:输入词元和输出词元拼接后的标号序列
31 # lm_attn_mask:对应的注意力掩码
32 # response_ids:计算交叉熵损失时目标的标号序列
33
34 # 将输入词元通过大语言模型进行编码,转化为隐状态
35 outputs = self.model.forward(
36 input_ids=prompt_ids,
37 attention_mask=lm_attn_mask,
38 return_dict=True,
39 use_cache=False,
40 )
41 # 使用交叉熵计算模仿学习的损失,作为最终损失函数中的正则项
42 hidden_states = outputs.last_hidden_state
43 logits = self.lm_head(hidden_states)
44 loss_fct = nn.CrossEntropyLoss()
45 logits = logits.view(-1, self.config.vocab_size)
46 response_ids = response_ids.view(-1)
47 loss = loss_fct(logits, response_ids)
48 return loss
49
50 def forward(self, sent1_idx, attention_mask_1, sent2_idx,
attention_mask_2, labels, prompt_ids, lm_attn_mask, response_ids,
**kargs):
↩→
↩→
51 # sent1_idx:输入词元和正例输出词元拼接后的标号序列。
52 # attention_mask_1:sent1_idx 对应的注意力掩码。
53 # sent2_idx:输入词元和负例输出词元拼接后的标号序列。
54 # attention_mask_2:sent2_idx 对应的注意力掩码。
55 # labels:正例输出所在的序列(均为 0,表示正例在 sent1_idx 中)。
56 # prompt_ids:输入词元和正例输出词元拼接后的标号序列。
57 # lm_attn_mask:prompt_ids 对应的注意力掩码。
58 # response_ids:计算交叉熵损失时目标的标号序列。
59
60 # 计算正例输出的奖励值
61 reward0 = self._forward_rmloss(
62 input_ids = sent1_idx,
63 attention_mask = attention_mask_1
64 )
65 # 计算负例输出的奖励值
66 reward1 = self._forward_rmloss(
67 input_ids = sent2_idx,
68 attention_mask = attention_mask_2
69 )
70 # 计算对比式训练方法的损失函数
71 logits = reward0 - reward1
72 rm_loss = F.binary_cross_entropy_with_logits(logits,
labels.to(logits.dtype), reduction="mean") ↩→
73
74 # 计算模仿学习的正则项的损失函数
75 lm_loss = self._forward_lmloss(prompt_ids, lm_attn_mask,
response_ids) ↩→
76
77 # 计算最终损失
78 loss = rm_loss + lm_loss
79 return loss这里对上述代码增加一点说明:
_forward_rmloss 和 _forward_lmloss 分别是用于计算对比式训练的损失函数和模仿学习部分的损失函数;
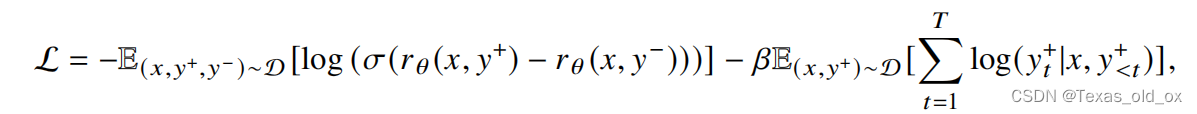
在模型中添加一个线性变换层的作用:
将隐状态从高维向量映射成一个标量。
语言模型的隐状态通常具有较高的维度,这是因为它们旨在捕获输入序列的复杂语言特征和上下文信息。而奖励信号本质上是一个标量值,用于量化某个行为或状态的好坏程度。因此,需要通过一个线性层来降维,将高维的特征表示转换为可以与奖励信号直接关联的单一数值。将高维向量映射到一个标量,实质上是将复杂的信息浓缩为一个易于理解和优化的目标。在奖励模型的上下文中,这一标量直接对应于预期的奖励大小,使得模型的训练目标更加明确和直接。
强化学习训练:
强化学习简述:
强化学习旨在训练一个智能体,该智能体与外部环境进行多轮交互,通过学习合适的策略进而最大化从外部环境获得的奖励。在强化学习的过程中,智能体是根据外部环境决定下一步行动的决策者,因此其被称为策略模型。在智能体和外部环境第t次交互的过程中,智能体需要根据当前外部环境的状态选择合适的策略,决定下一步该做出的行动。当智能体采取了某个行动之后,外部环境会从原来的状态变化为新的状态。此时,外部环境会给予智能体一个奖励分数。在和外部环境交互的过程中,智能体的目标是最大化所有决策(每一步的行动)能获得的奖励的总和。公式如下(不对其中参数做具体解释,简单来说就是找概率×奖励的最大值):
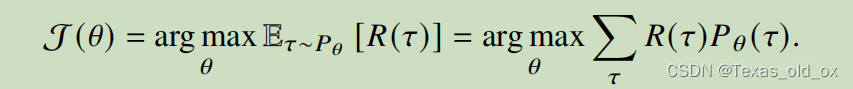
所以,大语言模型的人类对齐中的强化学习是怎么回事呢?
在自然语言生成任务中,大语言模型(即策略模型)需要根据用户输入的问题和已经生成的内容(即当前状态),生成下一个词元(即对下一步行动做出决策)。
当大语言模型完整生成整个回复之后(即决策轨迹),标注人员(或奖励模型)会针对大语言模型生成的回复进行偏好打分(即奖励分数)。大语言模型需要学习生成回应的有效策略,使得生成的内容能获得尽可能高的奖励,即其生成的内容尽可能符合人类的价值观和偏好。
近端策略优化(Proximal Policy Optimization, PPO)算法是强化学习领域的一种重要优化方法,主要用于训练能够根据外部环境状态做出行为决策的策略模型。
PPO算法训练流程:
首先,使用经过监督微调的大语言模型作为初始化策略模型 𝜋𝜃 和 𝜋𝜃old。然后,将策略模型 𝜋𝜃old 与环境进行交互,生成决策轨迹。进一步,PPO 算法会计算“优势估计”,用于衡量实际奖励与预期奖励之间的差异。此后,PPO 算法会尝试更新策略模型的参数,使用梯度裁剪或者引入 KL散度惩罚的方法,防止策略更新过于激进。经过一定次数的迭代后,PPO 算法会重新评估新策略的性能。如果新策略相比旧策略有所提升,那么这个新策略就会被接受,并用作下一轮学习的基础。
在RLHF的基础上后续又提出了一些不同的对齐方法,而且尽管 RLHF 已被证明是一种较为有效的语言模型对齐技术,但是它也存在一些局限性。这也衍生出了一些非强化学习的对齐方法。
对齐数据集的收集
-
基于奖励模型的方法
-
基于大语言模型的方法
以下是一个利用大语言模型来收集对齐数据集的方法示例:

关于非强化学习训练奖励模型的方法DPO,书上介绍的比较复杂。在算法解析中提到这样一段句话很重要:DPO 采用梯度下降的方式来优化策略模型的参数,优化过程中训练模型向符合人类偏好的内容靠近,同时尽量避免生成不符合人类偏好的内容。此外,公式中的前半部分可以看作是梯度的系数,动态地控制梯度下降的步长。
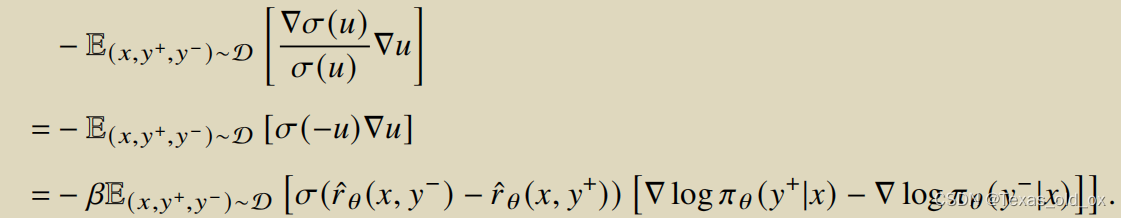
DPO总结:与 RLHF 算法相比,DPO 算法没有采用强化学习算法来训练奖励模型,而是通过监督微调的方式对于语言模型进行训练。与传统有监督微调方法不同,DPO 算法中不仅训练模型生成符合人类偏好的内容,同时降低模型生成不符合人类偏好内容的概率。相比于强化学习算法 PPO,DPO 在训练过程中只需要加载策略模型和参考模型,并不用加载奖励模型和评价模型。因此,DPO 算法占用的资源更少、运行效率更高,并且具有较好的对齐性能,在实践中得到了广泛应用。
下图是监督微调(SFT)和基于人类反馈的强化学习(RLHF)的优缺点对比表:

可以将文本生成问题看作为一个基于强化学习的决策过程:
当给定一个提示作为输入时,大语 言模型的任务是生成与任务指令相匹配的输出文本。这个生成过程可以被分解为 一系列逐个词元的生成步骤。在每个步骤中,大语言模型会根据已有的策略模型(即模型本身)在当前状态下的情况(包括当前已生成的词元序列以及可利用的上下文信息)来选择下一个动作,即生成下一个词元。
在这种设定下,我们优化的目标是让大语言模型能够不断优化其生成策略,生成更高质量的输出文本,获得更高的奖励分数。
本质上来说,为了学习教师 的生成策略,SFT 采用了基于示例数据的“局部”优化方式,即词元级别的损失函数。作为对比,RLHF 则采用了涉及人类偏好的“全局”优化方式,即文本级别的损失函数。
总的来说,SFT 特别适合预训练后增强模型的性能,具有实现简单、快速高效等优点;而 RLHF 可在此基础上规避可能的有害行为并进一步提高模型性能,但是实现较为困难,不易进行高效优化。















 1104
1104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









