







 蚂蚁集团与上海仁济医院泌尿科合作发布RJUA-QA Datasets,是国内首个临床专科推理数据集,旨在提高大模型在医疗诊断推理能力,提供评测基准。数据集基于医生临床经验,涵盖多病种和场景,具有真实临床背景、多样性和可解释性,可用于训练和评估医疗领域大模型。
蚂蚁集团与上海仁济医院泌尿科合作发布RJUA-QA Datasets,是国内首个临床专科推理数据集,旨在提高大模型在医疗诊断推理能力,提供评测基准。数据集基于医生临床经验,涵盖多病种和场景,具有真实临床背景、多样性和可解释性,可用于训练和评估医疗领域大模型。
OpenKG地址:http://openkg.cn/dataset/rjua-qadatasets
开放许可协议:CC BY-SA 4.0 (署名相似共享)
贡献者:上海交通大学医学院附属仁济医院(迟辰斐、吕向国、张明、李方舟、马硝惟、薛蔚、黄翼然),蚂蚁数字医疗健康团队(徐晓莉、陈志攀、陈子潇、甄帅)、蚂蚁医疗大模型团队(蔡鸿博、石磊、吕世伟、杨晓燕、赵登、申月、陶东杰、顾进杰、张志强、梁磊)
摘要
本文介绍一个基于临床医学泌尿外科知识体系构造的QA推理数据集,由蚂蚁集团医疗大模型团队(AntGroup Medical LLM)与上海交通大学医学院附属仁济医院泌尿科(Department of Urology, Shanghai Jiao Tong University School of Medicine Affiliated Renji Hospital)专家团队合作研发,简称为RJUA-QA Datasets,数据来源于医生参考临床经验中真实患者情况,改写的虚拟患者临床数据,不涉及任何医患隐私数据,经AI模型和专家团队处理校验,构建为问答对(Q-context-A)。本数据集旨在提高大型语言模型在医疗诊断推理方面的能力,并作为在严肃可控场景下应用的评测基准。我们将详细介绍数据集的构建过程、特点及统计分析,并全面评测了行业和通用大模型在该数据集上的性能,后续团队将持续优化数据集,为人工智能在医疗领域的研究与应用提供有力支持。
1、前言
自大型语言模型(LLM)问世以来,其在医疗服务领域的应用持续推动着行业的进步。近年来,随着互联网医疗服务的普及,患者对在线问诊和咨询的需求也呈现出不断上升的趋势。如今,远程医疗服务成为患者寻求便捷、高效医疗支持的首选。在这种背景下,大型语言模型所具备的丰富知识和自然语言交互优势,为智能医疗助手的广泛应用带来了巨大的潜力。
然而,这些模型在实际应用中仍面临诸多挑战,在医疗问诊过程中,复杂的情境要求个人助手具备丰富的医学知识,以便通过多轮对话了解患者需求并给出专业、详尽的解答。然而,通用型语言模型在应对医疗问诊时,常常因为缺乏足够领域知识而导致回避问题或回答不相关;另外,由于大模型的幻觉问题和推理不足,在实际应用上无法保证可控性和正确性。最关键的问题是,当前高质量的中文医学专科数据集相对稀缺,这对训练出色的医疗领域语言模型提出了挑战。
为了克服这些难题,蚂蚁与上海仁济医院泌尿科专家团队联合研发,基于医生团队临床经验改写的虚拟患者诊疗数据,构建了一个医疗泌尿专科问答推理数据集。据我们所知,该数据集是国内首个结合临床经验的医疗专科QA数据集,具有非常重要的科研和应用研究价值。该数据集的目标是提高大型模型在逻辑推理方面的能力,并为实际应用提供评估标准。我们期待这个数据集能为医疗领域的大型模型研究提供有价值的支持。
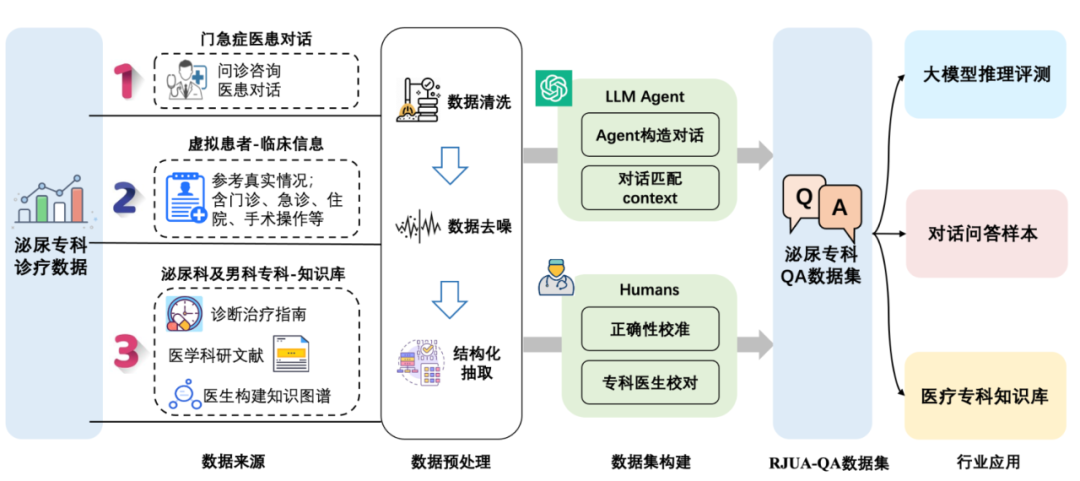
图1. RJUA-QA Datasets构建流程
2、数据集构建及特点
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2478
2478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









