







在处理大规模数据时,我们常常面临这样的困境:当数据被转化为高维嵌入向量后,传统聚类算法在计算效率和复杂结构捕捉上显得力不从心。比如,面对百万级的新闻标题数据,如何快速将相似主题的内容聚为一类?这时,HDBSCAN 算法与 Milvus 向量数据库的组合就能大显身手。今天,我们就来聊聊如何借助这对 “黄金搭档”,在高维空间中高效完成数据聚类,解锁数据内在模式的分析密码。
一、核心技术:HDBSCAN 与 Milvus 的优势互补
在深入实践之前,我们先搞清楚这两个核心技术的特点和分工:
1. HDBSCAN:擅长挖掘复杂结构的聚类高手
HDBSCAN(基于密度的层次聚类算法)是处理高维数据的利器,它有三个显著优势:
- 无需预设聚类数量:不像 K-means 需要提前指定 K 值,HDBSCAN 能自动发现最优的聚类数目,避免了人为设定的盲目性。
- 适应任意形状:通过分析数据点的局部密度和距离,能有效识别圆形、带状甚至不规则形状的聚类,这对于分布复杂的真实数据非常友好。
- 鲁棒的噪声处理:能将稀疏区域的点标记为噪声点,避免噪声对聚类结果的干扰。
2. Milvus:加速距离计算的向量数据库专家
当数据转化为高维嵌入向量后,直接计算所有点对的距离会产生 O (n²) 的时间复杂度,这在大规模数据下几乎不可行。Milvus 的作用就是解决这个痛点:
- 高效存储与索引:支持 FLAT、IVF、HNSW 等多种索引类型,能将向量检索速度提升至毫秒级,尤其适合高维向量的快速近邻搜索。
- 无缝集成算法:通过 Milvus 的 API,我们可以便捷地获取每个向量的前 k 个近邻,大幅减少 HDBSCAN 需要计算的距离矩阵规模,从 O (n²) 降至 O (nk),效率提升显著。
两者结合后,HDBSCAN 专注于聚类逻辑,Milvus 负责高效的向量存储和近邻检索,形成了 “分工明确、优势互补” 的技术方案。
二、实战教程:从数据预处理到聚类可视化
接下来,我们以新闻标题数据集为例,演示如何用 Milvus 和 HDBSCAN 完成聚类分析。数据集包含 2024 年的新闻标题和描述,我们的目标是将相似主题的新闻聚为一类。
1. 环境准备:安装必要工具
首先安装所需的库:
bash
# 安装Milvus(含模型支持)、HDBSCAN、可视化工具
pip install "pymilvus[model]" hdbscan plotly umap-learn
这里pymilvus[model]包含了预训练模型的支持,方便后续使用 BGE-M3 模型生成嵌入向量。
2. 数据预处理:生成嵌入向量
下载新闻数据集(可从 Kaggle 获取),合并标题和描述作为输入文本,使用 BGE-M3 模型生成 1024 维的嵌入向量:
python
运行
import pandas as pd
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
# 读取数据并合并文本
df = pd.read_csv("news_data_dedup.csv")
docs = [f"{title}\n{description}" for title, description in zip(df.title, df.description)]
# 生成嵌入向量(BGE-M3模型自动处理文本到向量的转换)
ef = BGEM3EmbeddingFunction()
embeddings = ef(docs)["dense"] # 提取密集型嵌入向量
BGE-M3 是专门针对中文的多模态嵌入模型,能有效捕捉文本的语义信息,生成高质量的嵌入向量。
3. 向量入库:构建 Milvus 集合
将嵌入向量和原始文本存入 Milvus,方便后续高效检索:
python
运行
from pymilvus import FieldSchema, CollectionSchema, DataType, connections, Collection
# 连接本地Milvus Lite(适合小规模数据,无需额外部署)
connections.connect(uri="milvus.db")
# 定义集合模式:包含ID、嵌入向量、原始文本字段
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=1024),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=65535),
]
schema = CollectionSchema(fields, description="News embeddings")
collection = Collection(name="news_data", schema=schema)
# 插入数据(逐条插入,也可批量处理提升效率)
for doc, emb in zip(docs, embeddings):
collection.insert({"text": doc, "embedding": emb})
# 创建FLAT索引(适合小规模数据,保证精确检索;大规模数据可换用IVF等索引)
index_params = {"index_type": "FLAT", "metric_type": "L2", "params": {}}
collection.create_index(field_name="embedding", index_params=index_params)
collection.flush() # 刷新集合,确保数据持久化
这里使用 L2 距离(欧氏距离)作为度量标准,因为 HDBSCAN 默认支持欧氏距离,且 FLAT 索引能提供精确的近邻搜索,适合演示场景。
4. 构建距离矩阵:利用 Milvus 加速近邻搜索
HDBSCAN 需要距离矩阵作为输入,但直接计算所有点对的距离太耗时。我们通过 Milvus 获取每个向量的前 50 个近邻,构建稀疏距离矩阵:
python
运行
import numpy as np
from pymilvus import Collection
collection = Collection("news_data")
collection.load() # 加载集合到内存,加速搜索
# 初始化数据结构
ids = []
dist = {}
embeddings_list = []
# 分页查询数据,避免内存溢出
iterator = collection.query_iterator(batch_size=10, expr="id > 0", output_fields=["id", "embedding"])
while True:
batch = iterator.next()
if not batch:
break
batch_ids = [data["id"] for data in batch]
batch_embs = [data["embedding"] for data in batch]
ids.extend(batch_ids)
embeddings_list.extend(batch_embs)
# 搜索每个向量的前50个近邻(L2距离)
search_params = {"metric_type": "L2", "params": {"nprobe": 10}} # nprobe控制搜索力度
results = collection.search(
data=batch_embs,
limit=50,
anns_field="embedding",
param=search_params,
output_fields=["id"],
)
# 存储近邻ID和距离
for i, bid in enumerate(batch_ids):
dist[bid] = [(result.id, result.distance) for result in results[i]]
# 将原始ID映射为连续索引,方便构建距离矩阵
ids2index = {id: idx for idx, id in enumerate(ids)}
n = len(ids)
dist_metric = np.full((n, n), np.inf, dtype=np.float64) # 初始化为无穷大
# 填充近邻距离,远距离点保持无穷大(HDBSCAN会忽略这些点)
for bid, neighbors in dist.items():
idx = ids2index[bid]
for nid, distance in neighbors:
nidx = ids2index[nid]
dist_metric[idx, nidx] = distance
dist_metric[nidx, idx] = distance # 距离矩阵对称
这里通过query_iterator分页处理数据,避免一次性加载所有数据导致内存不足。limit=50表示每个向量只考虑前 50 个近邻,大幅减少计算量,同时保留足够的局部密度信息。
5. 执行 HDBSCAN 聚类
使用预处理好的距离矩阵进行聚类,注意设置metric="precomputed"表明输入是距离矩阵:
python
运行
import hdbscan
# 初始化HDBSCAN,设置最小样本数和最小聚类大小
hdb = hdbscan.HDBSCAN(
min_samples=3, # 核心点至少需要的邻居数
min_cluster_size=3, # 最小聚类大小(避免过拟合)
metric="precomputed" # 使用预计算的距离矩阵
).fit(dist_metric)
# 聚类结果:-1表示噪声点,其他为聚类标签
cluster_labels = hdb.labels_
print(f"Clusters found: {len(set(cluster_labels)) - 1} (excluding noise)")
参数调整建议:
min_samples:值越大,聚类越严格,噪声点越多,通常设为 5-10。min_cluster_size:根据数据规模调整,小规模数据设为 3-5,大规模数据可设为 50-100。
6. 可视化聚类结果:用 UMAP 降维展示
将高维嵌入向量降维到 2D 空间,用不同颜色表示聚类,鼠标悬停可查看原始文本:
python
运行
import plotly.express as px
from umap import UMAP
# 降维处理
umap = UMAP(n_components=2, random_state=42, n_neighbors=80, min_dist=0.1)
umap_emb = umap.fit_transform(embeddings_list)
# 构建可视化数据框
df_umap = pd.DataFrame(umap_emb, columns=["x", "y"])
df_umap["cluster"] = cluster_labels.astype(str)
df_umap = df_umap[df_umap["cluster"] != "-1"] # 过滤噪声点
# 获取原始文本(需再次查询Milvus,可优化为预处理时存储)
texts = [doc for doc in docs] # 假设docs顺序与ids一致
df_umap["hover_text"] = texts[df_umap.index]
# 绘制散点图
fig = px.scatter(
df_umap, x="x", y="y", color="cluster",
hover_data={"hover_text": True}, title="HDBSCAN Clustering Results"
)
fig.show()
UMAP 能较好地保留高维数据的局部结构,使得可视化结果更贴近真实聚类分布。
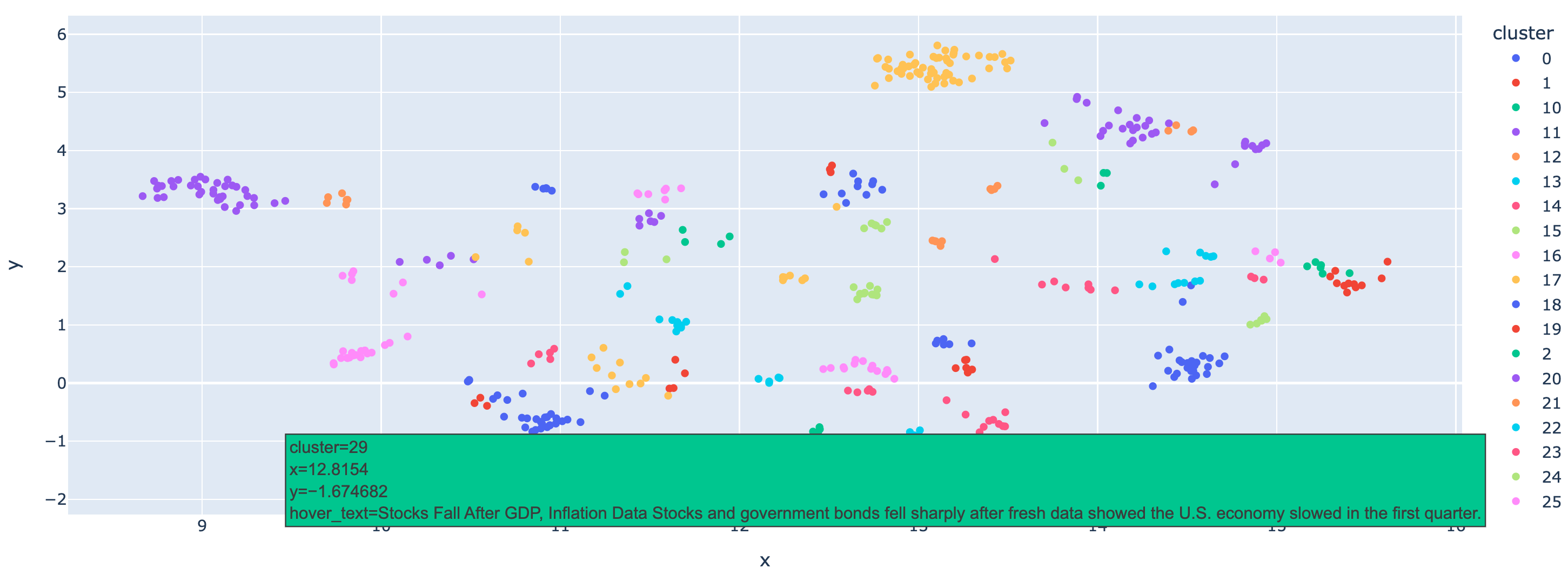
三、实践中的关键问题与解决思路
在实际操作中,我们可能会遇到这些挑战:
1. 大规模数据内存溢出
问题:当数据量超过百万级时,距离矩阵dist_metric可能占用数 GB 内存。
解决:
- 改用 Milvus 的分布式部署(Docker/Kubernetes),利用其分片存储能力。
- 使用近似索引(如 IVF、HNSW)替代 FLAT 索引,在保证精度损失可控的前提下,大幅提升搜索速度。
2. 聚类结果不理想
问题:出现噪声点过多或聚类过细。
解决:
- 调整 HDBSCAN 参数:增大
min_cluster_size合并小聚类,减小min_samples让聚类更宽松。 - 检查嵌入向量质量:确保文本预处理(如分词、去停用词)正确,或尝试更换更适合任务的嵌入模型(如 BERT、GPT-4 的文本嵌入)。
3. Milvus 连接失败
问题:本地文件路径错误或服务器端口未开放。
解决:
- 本地开发时,确保
uri="./milvus.db"路径正确,无中文或特殊字符。 - 服务器部署时,检查 Milvus 服务是否启动,端口 19530 是否可访问(默认端口)。
四、应用场景:让聚类结果创造业务价值
1. 用户需求分类(以电商为例)
将用户评价文本转化为嵌入向量,通过 HDBSCAN 聚类后,可清晰区分:
- 产品功能类需求(如 “电池续航短”“摄像头像素低”)
- 服务体验类需求(如 “物流太慢”“客服响应差”)
- 价格敏感类需求(如 “性价比低”“促销活动少”)
帮助产品经理快速定位高频问题,优先优化核心痛点。
2. 市场趋势分析
对行业报告、新闻资讯聚类后,能自动识别当前热点话题。例如,在新能源汽车领域,可能聚出 “电池技术突破”“充电基础设施建设”“政策补贴变化” 等聚类,辅助企业制定战略决策。
3. 动态事件监测
在社交媒体数据中,当某个新聚类突然出现并快速增长时,可能预示着热点事件爆发。例如,某品牌手机的 “发热严重” 评价突然聚类规模扩大,可作为质量问题预警信号。
五、总结与建议
通过 Milvus 与 HDBSCAN 的结合,我们实现了从高维向量数据到有意义聚类的高效转化。这套方案的核心优势在于:
- 效率提升:Milvus 的近邻搜索将距离计算复杂度从 O (n²) 降至 O (nk),支持百万级数据处理。
- 结构发现:HDBSCAN 无需预设聚类数,能捕捉任意形状的聚类,适合复杂真实数据。
- 可解释性:通过 UMAP 可视化,让高维聚类结果变得直观易懂。
如果你想在实际项目中应用,建议:
- 从小规模数据开始验证:先用千级数据调试代码,确保流程畅通。
- 关注嵌入质量:花时间优化文本预处理或选择更合适的嵌入模型,这对聚类效果影响巨大。
- 探索索引优化:大规模数据下,尝试 IVF-FLAT(速度与精度平衡)或 HNSW(极致速度)索引。
希望这篇教程能帮你打开高维数据聚类的大门。如果你在实践中遇到任何问题,欢迎在评论区留言交流,我们一起探讨解决方案!觉得有用的话,别忘了点击关注,后续会分享更多 Milvus 与机器学习结合的实战经验~


















 871
871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











