







前言
学习笔记,仅供学习,不做商用,如有侵权,联系我删除即可
在介绍深度神经网络之前,我们需要了解神经网络训练的基础知识。
本章将介绍神经网络的整个训练过程,包括:
- 定义简单的神经网络架构;
- 数据处理;
- 指定损失函数;
- 如何训练模型。
一、线性回归
回归(regression)是能为一个或多个自变量与因变量之间关系建模的一类方法。在自然科学和社会科学领域,回归经常用来表示输入和输出之间的关系。
1.1 线性回归的基本元素
线性回归基于几个简单的假设:
- 首先,假设自变量x和因变量y之间的关系是线性的,允许包含观测值的一些噪声;
- 其次,我们假设任何噪声都比较正常,如噪声遵循正态分布。
为了解释线性回归,我们举一个实际的例子:我们希望根据房屋的面积(平方英尺)和房龄(年)来估算房屋价格(美元)。为了开发一个能预测房价的模型,我们需要收集一个真实的数据集。这个数据集包括了房屋的销售价格、面积和房龄。
在机器学习的术语中,该数据集称为训练数据集(training data set)或训练集(training set)。
每行数据(比如一次房屋交易相对应的数据)称为样本(sample),也可以称为数据点(data point)或数据样本(data instance)。
试图预测的目标(比如预测房屋价格)称为标签(label)或目标(target)。
预测所依据的自变量(面积和房龄)称为特征(feature)或协变量(covariate)。
线性模型
线性假设是指目标(房屋价格)可以表示为特征(面积和房龄)的加权和![]()
其中,![]() ,决定了每个特征对我们预测值的影响。b称为偏置(bias)、 偏移量(offset)或截距(intercept)。偏置是指当所有特征都取值为0时,预测值应该为多少。
,决定了每个特征对我们预测值的影响。b称为偏置(bias)、 偏移量(offset)或截距(intercept)。偏置是指当所有特征都取值为0时,预测值应该为多少。
仿射变换(affine transformation):仿射变换的特点是通过加权和对特征进行线性变换(linear transformation),并通过偏置项来进行平移(translation)。
在开始寻找最好的模型参数(model parameters)w和b之前,我们还需要两个东西:(1)一种模型质量的度量方式;(2)一种能够更新模型以提高模型预测质量的方法。
损失函数
损失函数(loss function)能够量化目标的实际值与预测值之间的差距。通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。回归问题中最常用的损失函数是平方误差函数。
解析解
线性回归的解可以用一个公式简单地表达出来,这类解叫作解析解(analytical solution)
随机梯度下降(SGD)
在我们无法得到解析解的情况下,我们仍然可以有效地训练模型。
本书中用到的是一种名为梯度下降(gradient descent)的方法,这种方法几乎可以优化所有深度学习模型。它通过不断地在损失函数递减的方向上更新参数来降低误差。
梯度下降最简单的用法是计算损失函数(数据集中所有样本的损失均值)关于模型参数的导数(在这里也可以称为梯度)。但实际中的执行可能会非常慢:因为在每一次更新参数之前,我们必须遍历整个数据集。因此,我们通常会在每次需要计算更新的时候随机抽取一小批样本,这种变体叫做小批量随机梯度下降(minibatch stochastic gradient descent)。
在每次迭代中,我们首先随机抽样一个小批量B,它是由固定数量的训练样本组成的。然后,我们计算小批量的平均损失关于模型参数的导数(也可以称为梯度)。最后,我们将梯度乘以一个预先确定的正数η,并从当前参数的值中减掉。
算法的步骤如下:
- 初始化模型参数的值,如随机初始化;
- 从数据集中随机抽取小批量样 本且在负梯度的方向上更新参数,并不断迭代这一步骤。
|B|表示每个小批量中的样本数,这也称为批量大小(batch size)。
η表示学习率(learning rate)。
批量大小和学习率的值通常是手动预先指定,而不是通过模型训练得到的。
这些可以调整但不在训练过程中更新的参数称为超参数(hyperparameter)。
调参(hyperparameter tuning)是选择超参数的过程。超参数通常是我们根据训练迭代结果来调整的,而训练迭代结果是在独立的验证数据集(validation dataset)上评估得到的。
在从未见过的数据上实现较低的损失的能力被称为泛化(generalization)
用模型进行预测
给定特征估计目标的过程通常称为预测(prediction)或推断(inference)
1.2 从线性回归到深度网络
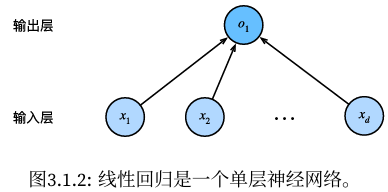
在图3.1.2所示的神经网络中,输入为x1,...,xd,因此输入层中的输入数(或称为特征维度,feature dimensionality)为d。网络的输出为o1,因此输出层中的输出数是1。
通常在计算层数时不考虑输入层,因此图3.1.2所示的神经网络的层数为1.
线性回归模型视为仅由单个人工神经元组成的神经网络,或称为单层神经网络。
每个输入都与每个输出(在本例中只有一个输出)相连,我们将这种变换(图3.1.2中的输出层)称为全连接层(fully‐connected layer)或称为稠密层(dense layer)。
1.3 训练一个模型的过程概括
整体的训练过程如下:
- 获取数据集;
- 读取数据集;
- 初始化模型参数;
- 定义模型;
- 定义损失函数;
- 定义优化算法;
- 训练。
在每次迭代中,我们读取一小批量训练样本,并通过我们的模型来获得一组预测。
计算完损失后,我们开始反向传播,存储每个参数的梯度。
最后,我们 调用优化算法SGD来更新模型参数。

定义模型的简洁方法
首先定义一个模型变量net,它是一个Sequential类的实例。
Sequential类将多个层串联在一起。当给定输入数据时,Sequential实例将数据传入到第一层,然后将第一层的输出作为第二层的输入,以此类推。
在PyTorch中,全连接层在Linear类中定义。值得注意的是,我们将两个参数传递到nn.Linear中。第一个指定输入特征形状,即2,第二个指定输出特征形状,输出特征形状为单个标量,因此为1。
# nn是神经网络的缩写
from torch import nn
net = nn.Sequential(nn.Linear(2, 1))初始化模型参数、损失函数、优化算法
直接访问参数以设定它们的初始值
# 模型参数
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
# loss function
loss = nn.MSELoss()
# 优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.03)小批量随机梯度下降算法是一种优化神经网络的标准工具,PyTorch在optim模块中实现了该算法的许多变种。
当实例化一个SGD实例时,我们要指定优化的参数(可通过net.parameters()从我们的模型中获得)以及优化算法所需的超参数字典。小批量随机梯度下降只需要设置lr值,这里设置为0.03。
训练
步骤:
- 通过调用net(X)生成预测并计算损失Loss(前向传播)
- 通过进行反向传播来计算梯度
- 通过调用优化器来更新模型参数
例如:
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X) ,y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}'
二、softmax回归
2.1 分类问题
独热编码(one‐hot encoding)。独热编码是一个向量,它的分量和类别一样多。类别对应的分量设置为1,其他所有分量设置为0。
例如:标签y将是一个三维向量,其中(1,0,0)对应于 “猫”、(0,1,0)对应于“鸡”、(0,0,1)对应于“狗”:
![]()
2.2 网络架构
为了估计所有可能类别的条件概率,我们需要一个有多个输出的模型,每个类别对应一个输出。为了解决线性模型的分类问题,我们需要和输出一样多的仿射函数(affine function)。每个输出对应于它自己的仿射函数。

有4个特征和3个可能的输出类别,我们将需要12个标量来表示权重(带下标的w),3个标量来表示偏置(带下标的b),输出的结果应该是:

2.3 参数开销
任何具有d个输入和q个输出的全连接层,参数开销为O(dq)。
幸运的是,将d个输入转换为q个输出的成本可以减少到O(dq/n),其中超参数n可以由我们灵活指定
2.4 softmax运算
要将输出视为概率,我们必须保证在任何数据上的输出都是非负的且总和为1。
softmax函数能够将未规范化的预测变换为非负数并且总和为1,同时让模型保持可导的性质。
首先对每个未规范化的预测求幂,这样可以确保输出非负。为了确保最终输出的概率值总和为1,再让每个求幂后的结果除以它们的总和。如下式:

softmax运算不会改变未规范化的预测o之间的大小次序,只会确定分配给每个类别的概率。
尽管softmax是一个非线性函数,但softmax回归的输出仍然由输入特征的仿射变换决定。因此,softmax回归是一个线性模型(linear model)
2.5 损失函数
交叉熵损失(cross-entropy loss)是所有标签分布的预期损失值,是分类问题最常用的损失之一。

![]()
导数是我们softmax模型分配的概率与实际发生的情况(由独热标签向量表示)之间的差异。
2.6 模型预测和评估
在训练softmax回归模型后,给出任何样本特征,可以预测每个输出类别的概率。
通常使用预测概率最高的类别作为输出类别。
如果预测与实际类别(标签)一致,则预测是正确的。
在接下来的实验中,将使用精度(accuracy)来评估模型的性能。
精度等于正确预测数与预测总数之间的比率。
为了计算精度,可以执行以下操作:
- 首先,如果y_hat是矩阵,那么假定第二个维度存储每个类的预测分数。使用argmax获得每行中最大元素的索引来获得预测类别。
- 将预测类别与真实y元素进行比较。由于等式运算符“==”对数据类型很敏感,因此y_hat的数据类型转换为与y的数据类型需要保持一致。结果是一个包含0(错)和1(对)的张量。
- 最后,求和得到正确预测的数量。
















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











